-
项与项集:设itemset={item1, item_2, …, item_m}是所有项的集合,其中,item_k(k=1,2,…,m)成为项。项的集合称为项集(itemset),包含k个项的项集称为k项集(k-itemset)。
-
事务与事务集:一个事务T是一个项集,它是itemset的一个子集,每个事务均与一个唯一标识符Tid相联系。不同的事务一起组成了事务集D,它构成了关联规则发现的事务数据库。
-
关联规则:关联规则是形如A=>B的蕴涵式,其中A、B均为itemset的子集且均不为空集,而A交B为空。
-
支持度(support):关联规则的支持度定义如下:

其中
 表示事务包含集合A和B的并(即包含A和B中的每个项)的概率。注意与P(A or B)区别,后者表示事务包含A或B的概率。
表示事务包含集合A和B的并(即包含A和B中的每个项)的概率。注意与P(A or B)区别,后者表示事务包含A或B的概率。 -
置信度(confidence):关联规则的置信度定义如下:
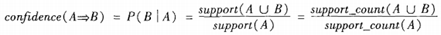
-
项集的出现频度(support count):包含项集的事务数,简称为项集的频度、支持度计数或计数。
-
频繁项集(frequent itemset):如果项集I的相对支持度满足事先定义好的最小支持度阈值(即I的出现频度大于相应的最小出现频度(支持度计数)阈值),则I是频繁项集。
-
强关联规则:满足最小支持度和最小置信度的关联规则,即待挖掘的关联规则。
实现步骤:1.找出所有的频繁项集 2.由频繁项集产生强关联规则
关联分析是用于发现大数据集中元素间有趣关系的一个工具集,可以采用两种方式来量化这些有趣的关系。第一种方式是使用频繁项集,它会给出经常在一起出现的元素项。第二种方式是关联规则,每条关联规则意味着元素项之间的“如果……那么”关系。发现元素项间不同的组合是个十分耗时的任务,不可避免需要大量昂贵的计算资源,这就需要一些更智能的方法在合理的时间范围内找到频繁项集。能够实现这一目标的一个方法是Apriori算法,它使用Apriori原理来减少在数据库上进行检查的集合的数目。Apriori原理是说如果一个元素项是不频繁的,那么那些包含该元素的超集也是不频繁的。Apriori算法从单元素项集开始,通过组合满足最小支持度要求的项集来形成更大的集合。支持度用来度量一个集合在原始数据中出现的频率。关联分析可以用在许多不同物品上。商店中的商品以及网站的访问页面是其中比较常见的例子。每次增加频繁项集的大小,Apriori算法都会重新扫描整个数据集。当数据集很大时,这会显著降低频繁项集发现的速度。
下面会介绍FP-growth算法,和Apriori算法相比,该算法只需要对数据库进行两次遍历,能够显著加快发现频繁项集的速度。
FP-growth算法基于Apriori构建,但采用了高级的数据结构减少扫描次数,大大加快了算法速度。FP-growth算法只需要对数据库进行两次扫描,而Apriori算法对于每个潜在的频繁项集都会扫描数据集判定给定模式是否频繁,因此FP-growth算法的速度要比Apriori算法快。
FP-growth算法发现频繁项集的基本过程如下:
- 构建FP树
- 从FP树中挖掘频繁项集
FP-growth算法
- 优点:一般要快于Apriori
- 缺点:实现比较困难,在某些数据集上性能会下降
- 适用数据类型:离散型数据