命名管道
参考了https://blog.csdn.net/orangleliu/article/details/49133199

上一讲我们说的是匿名管道,不用我们自己去创建的,并且用完管道文件就没有了,今天我们来学习命名管道,就是我们自己创建的,一直存在的,如果你不删的话,这里。的知识视频里没有来看一个例子:

管道这个词还是挺形象的,这个p是不存数据的,只有当输入和输出都有的时候,这个数据才可以传过去,管道才有用,就像交易双方都点头,猫<p就像买方,date> p就像卖方,这个交易才算完成,钱或者物资才能流通。
不过我觉得这奇葩的地方就在于你必须用两个终端来完成这个过程。用一个终端是不行的。这个和脚本也没关系。

看到脚本里的命令是一行一行运行的,先是日期> p,所以在另一个窗口中打出cat <p会打印时间,而脚本里的第二行是cat <p,所以在第二个终端输入date> p,会在第一个终端打出时间信息。如果有多个进程往外送水,一个人接水呢?

看到是可以都接受的,不过打印出来的顺序正好和输出的时间顺序相反,这就叫后来居上吧,并且呢,看到一对输入输出匹配完成后在猫<p是没有输出的,因为管道不存水,这个也很难好理解,猫<p相当于是建立新的一对输入输出关系。同时,看到睡觉2000> p,只有在匹配了输入猫<p之后才会有pid,说明只有配对成功才能执行命令,GIF里面看到睡眠的1确实重定向到了p管道文件。再验证一下后来者居上。

一个输入多个输出呢,这当然好理解了,因为一个终端cat> p之后,这个交易已经重置了,你再另一个终端cat <p这是开始新的交易,这个终端是买方,是买方主动联系的卖家而已。命名管道也不是很难对吧。
三通管道(也叫三通)

参考了https://blog.csdn.net/williamwang2013/article/details/8550178。

也就是说三通只是对1重定向。



如果你想把错误信息也输出到文件中,也可以。


作业管理
参考了
https://www.cnblogs.com/harrymore/p/8794944.html
https://blog.csdn.net/bit_clearoff/article/details/57113825
首先应该知道什么是作业?



这个-j是作业格式输出的意思。

在centos7里似乎不太一样,我把2193杀死了,但是作业还在运行。

如果像下面这这样,作业才是真的GG了。


会话的话,我们用XSHELL远程连接打开的就是一个会话。


这里面有一个SID,还记得前面其实提到过一个session的东西,这个会话就被叫做会话,bash是这个会话的会话负责人。

第二条不能等待输入就是没有人机交互的,不需要人键盘输入的。

不过在centos7里面是不会自动打出来做信息的。需要们的工作出来。


不过我们并没有办法看到外壳被拉到后台。



用睡眠演示一下:
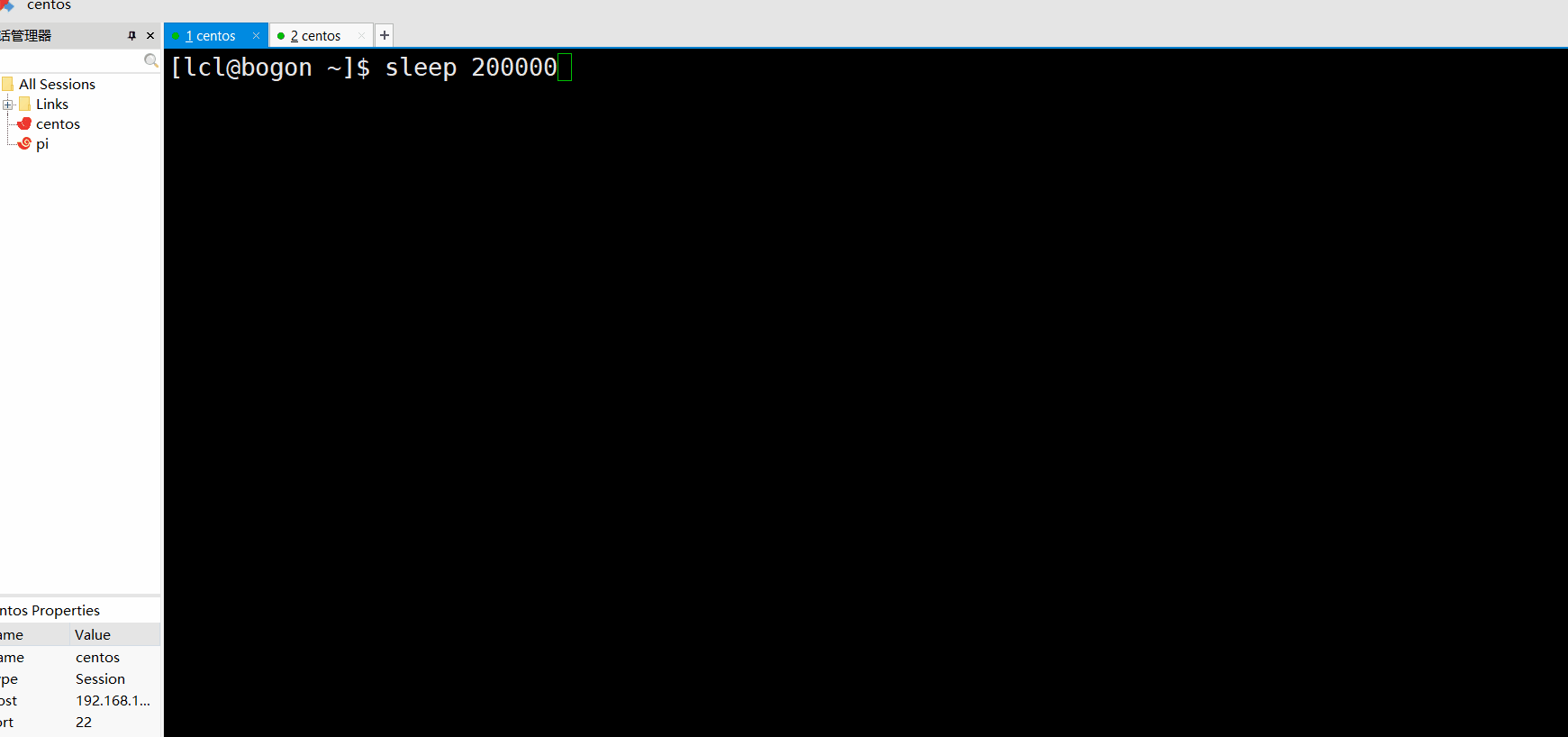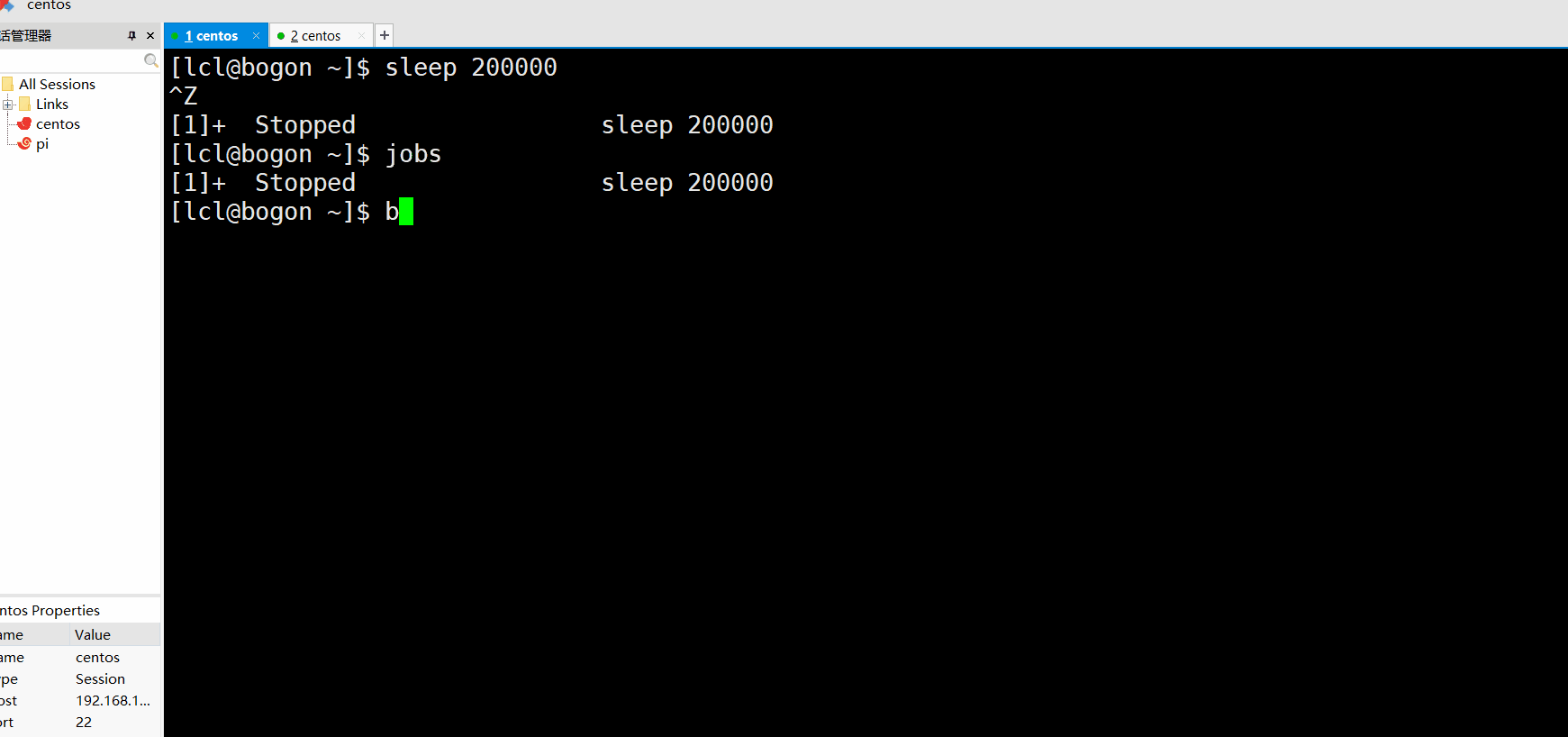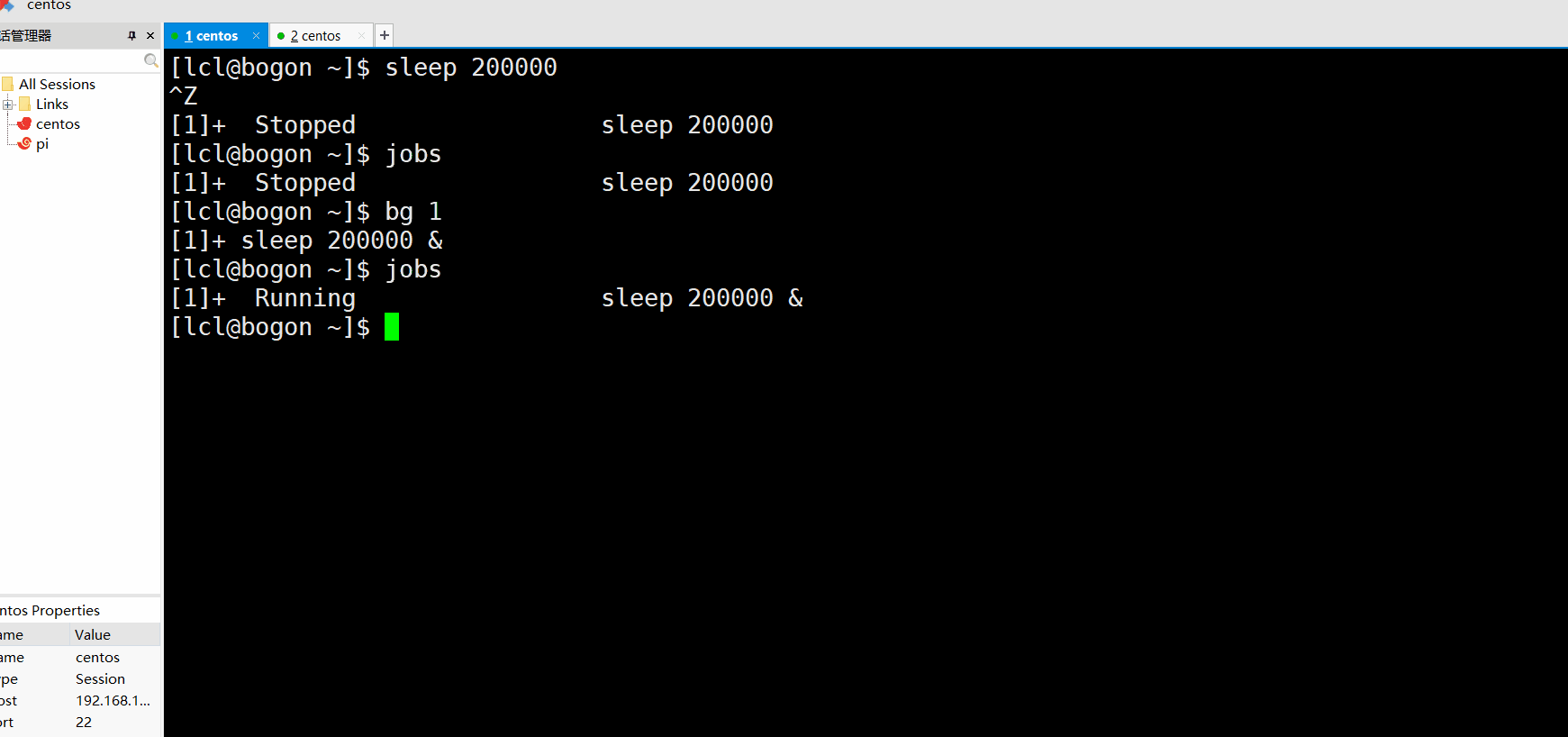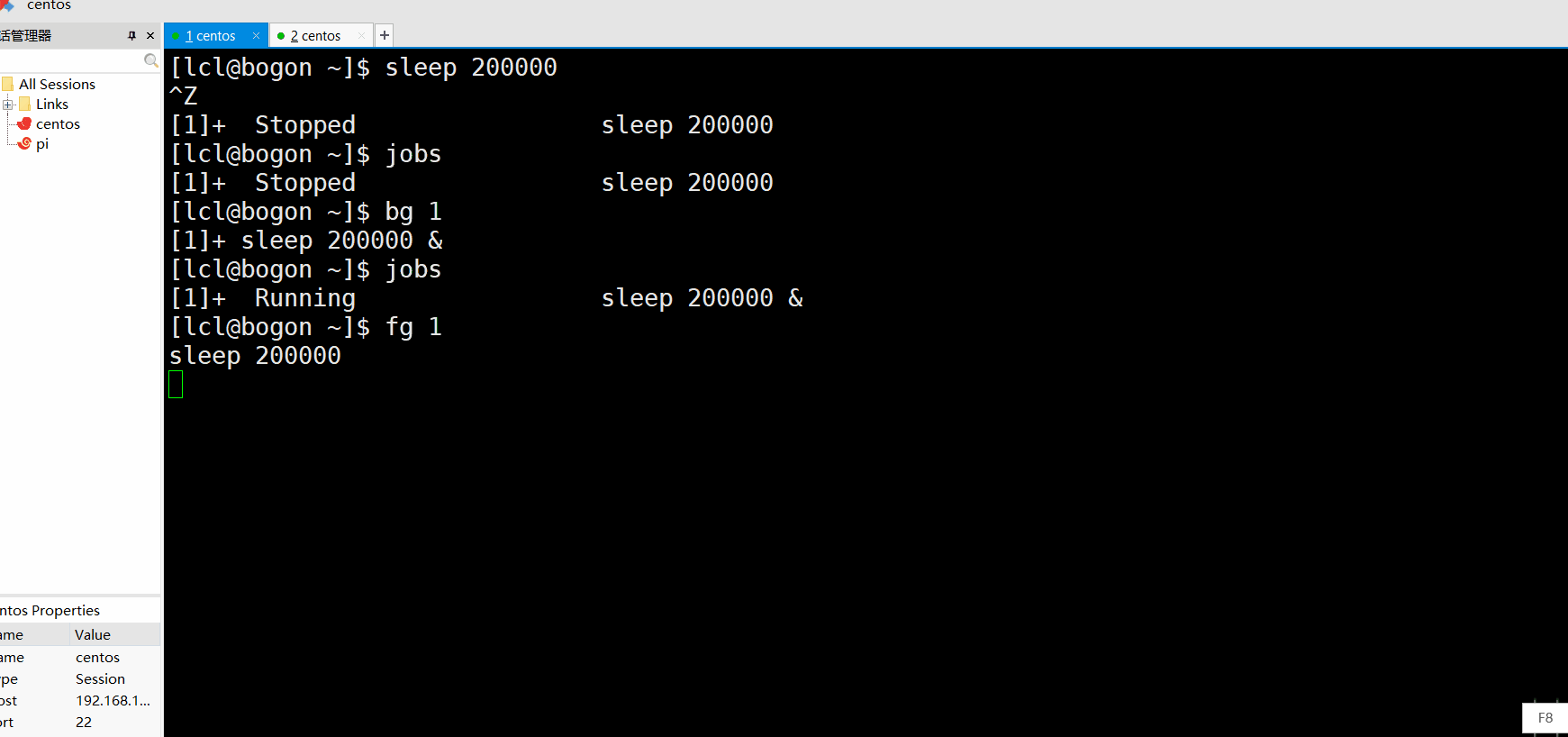


注意作业用杀杀的时候用的应该是作业号,也就是[]里面的数字,这个百分号一定要加,不然没办法区分作业和进程了。



的确是这样子的。

存储管理
相信我们都知道内存速度比硬盘快,内存掉电就会失去数据,要不然程序员也不会有,2S的习惯,当然是在窗户下说的,硬盘是只要不坏都是永久性储存的。


机械硬盘有很多磁道,磁道里又分为很多扇区,机械硬盘找数据就得先找到那个磁道,然后等着转到目标扇区,然后进行IO操作,并且文件可能不是集中存在某个扇区某个磁道的,所以就会比较慢,有寻道时间,延迟时间等。


现在的磁盘一般都是2.5的。

一般都是热插拔,就是电脑不用关机直接拔的那种,一般呢,会把很多硬盘做成一个阵列,叫做RAID,这样可以增加容错率,提高IO速度,如果其中有一块硬盘坏了,一般直接热插拔好像就可以,我也不是很懂,视频里这么说的。

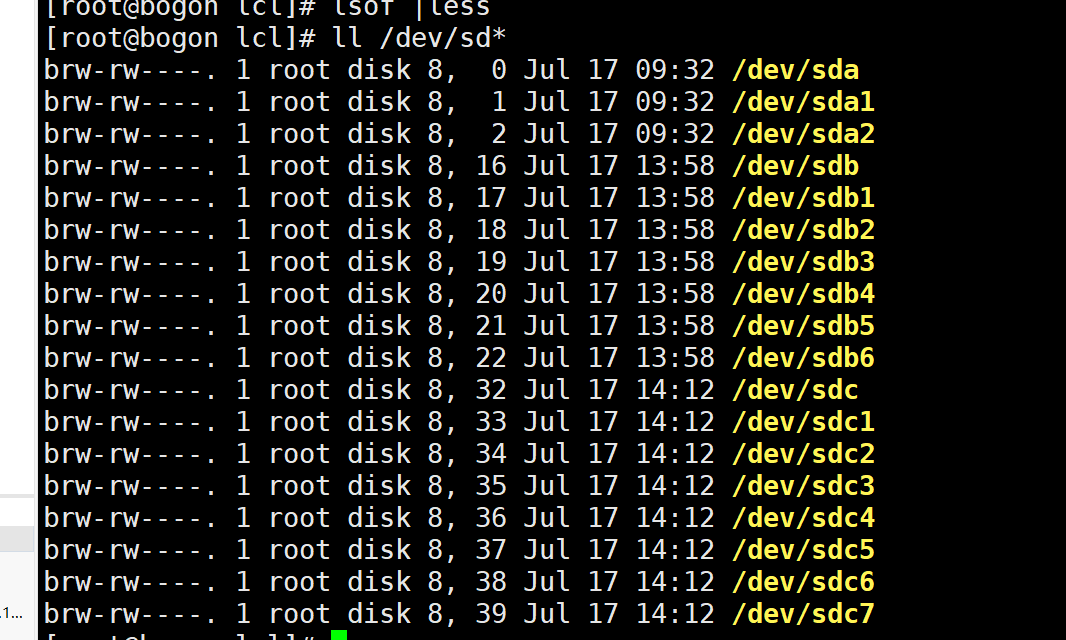
硬盘的命名呢,一般我们都是用的/ dev / SDA,的/ dev / SDB ....用lsblk可以看一看。

这个我们当时就给了一块硬盘,所以说只有SDA,这个硬盘有两个分区为sda1,sda2。
SR0是光驱,可以不去管它.KVM的我们就看看,后面可能会学一下,我们目前用的还是VMware的。

上面展示了一下惠普的服务器硬盘命名和一般的不太一样。连接方式本地存储和网络存储比较多,本地存一些操作系统等软件,网络存储主要是一些数据需要共享的时候就用到,比较火的是头孢分布式存储,我虽然不是很了解区块链,但是似乎感觉区块链就是用的这个,它还会保留副本。
基本分区


分区就是规划扇区,这几块扇区归你,那几块扇区归他等等.linux有两种分区表,一种是MBR,用的软件是fdisk的,这种最多14个分区,其中4个主分区,如果想分多于四个分区,就得分扩展分区,扩展分区和主分区的和最多是4个,逻辑分区是从扩展分区里分出来的,一般的搭配是3个主分区加一个扩展分区。为什么MBR只能由4个主分区呢?这是因为MBR第一个那个灰色的分区,叫做每个存储设备(主引导记录)占一个扇区,每个扇区512字节,用来存放分区表(primary partion table)的只有64B,每一个主分区要占16B,所以最多4个。这种分区方案是IBM工资制定的。我们先来加两块硬盘,一块是一种分区。我已经事先添加了一块SDB下面再添加一块SDC:

重启虚拟机之后效果就是这样:

下面分别进行两种分区:
基本分区管理

上面用的是VDB,VDC,不影响我们操作,看成SDB,SDC就行。

先来进行MBR分区。这个分区软件fdisk不需要下载。分区是需要root权限的,可以sudo或者干脆直接切到root用户.fdisk / dev / sdb就可以对sdb分区了。

米是帮助,常用的也就是d删除,正新建,对显示,W保存,Q不保存退出。创建一个分区还是比较简单的。

Ñ新建一个分区,回车,会让你选择分区类型,P是主分区,E是扩展分区,默认是P,直接回车,然后让你选择分区编号,默认是从1开始升序排列的,这是第一次创建,所以默认是1。
还是直接回车,然后让你选起始扇区,默认是2048,直接默认就可以了,回车,然后让你选结束扇区,对于人来说一般还是习惯用+大小{K,M,绿}的方式,我给了10G,回车,显示1分区就创建好了.P查看一下。

唉,发现SDB居然由21.5G,这个1.5G我也不知道怎么多出来的,我也很懵逼,后面是多少个字节,多少个扇区。下一行写了分区的最小单位是扇区,一个扇区512B。磁盘标志类型是DOS,MBR就是这种类型的。我们可以大概算一算(20973567-2048)×512 /一千○二十四分之一千○二十四=

M≈10240M了0.10485760 = 10 * 1024 * 1024,说明一个块(块)是1KB。
下面再来分一个区,这次我们不按照顺序来。

看到一共20G,但是这次我们给10G失败了,为什么呢?因为下面图里的灰色,黄色都是要占位置的,所以剩下的肯定不能给10G了。(为什么不说蓝色,因为我们这里还没有扩展分区)
还看到sdb3的起始扇区和SDB1的结束扇区是挨着的。

我们再创建一个扇区,sdb2给了1G,不再演示,主要是看看创建第四个扇区时会发生什么。

第四个扇区创建的时候默认的类型就是ë了,不过我们还是可以创建p的。最后的SD4,可以算一算一千零二十四分之四百十九万三千二百八十零/ 1024 = 4095M,比4G少了1M,1M着可能就是灰色和黄色吧。

还可以再创建新分区吗?不行了,提示你要想创建更多分区,就得用一个扩展分区来替换主分区。我们就来做一下。


这样我们就可以创建多个4个分区,会有提示说时逻辑分区。


我们看到,我们创建的sdb5逻辑分区的扇区范围是在sdb4扩展分区的范围里面的,但是起始扇区有点不一样,中间隔了33558528-33556480 = 2048个扇区,也就是1M.4193280 -4192256 = 1024K也是1M,这块应该就是上面图里的蓝色部分了。
然后我们W¯¯保存一下。用lsblk看一下。

看到SD4只有1K的大小,这是为什么呢?因为其实扩展分区的存在就是为了分多于4个区而已,我们是没有办法用它的,它里面存的是分区表,我们真正用到的应该是逻辑分区,也就是sdb5这种的分区.fdisk -l / dev / sdb可以查看我们保存的分区,前提是一定要保存。

出现最后一行提示的原因是我们sdb1和sdb2的是扇区不是挨着的,没有按照顺序,所以是不在磁盘顺序,不过没有关系。
我们再试一个东西:

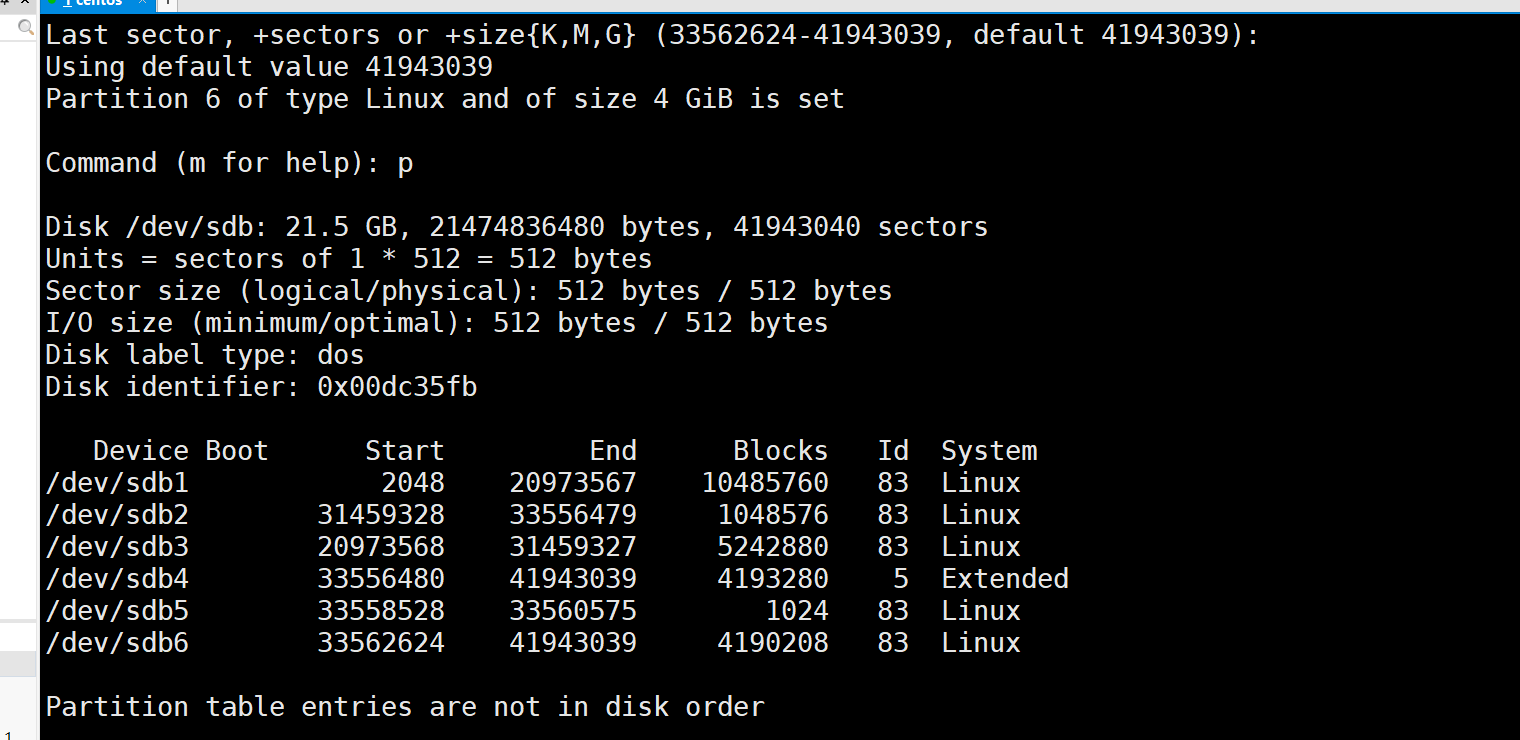
这个主要是想说明,多了一个逻辑分区的话,sdb5和sdb6也不是连着的,中间差了2624-575 = 2049个扇区,那就是1024.5KB,存的可能还是分区有关的一些信息。
gdisk软件需要我们yum -y install gdisk才可以用的。我们先假装我们的硬盘有2T。
步骤基本上不变的。看到只有MBR分区表,BSD,APM,GPT分区表都没有,因为我们还没有创建啊。

?查看帮助,命令都差不多的。


不同的一点在于n的时候,就不会问你是p还是e了,因为没有这个概念,分的区都是一样的。多了一步问你是不是linux filesystem,回车即可。

这种可以分最多128个分区的,w保存,y即可。这里再可能一点,如果没有空间可分,会提示你没有可用的免费区域。
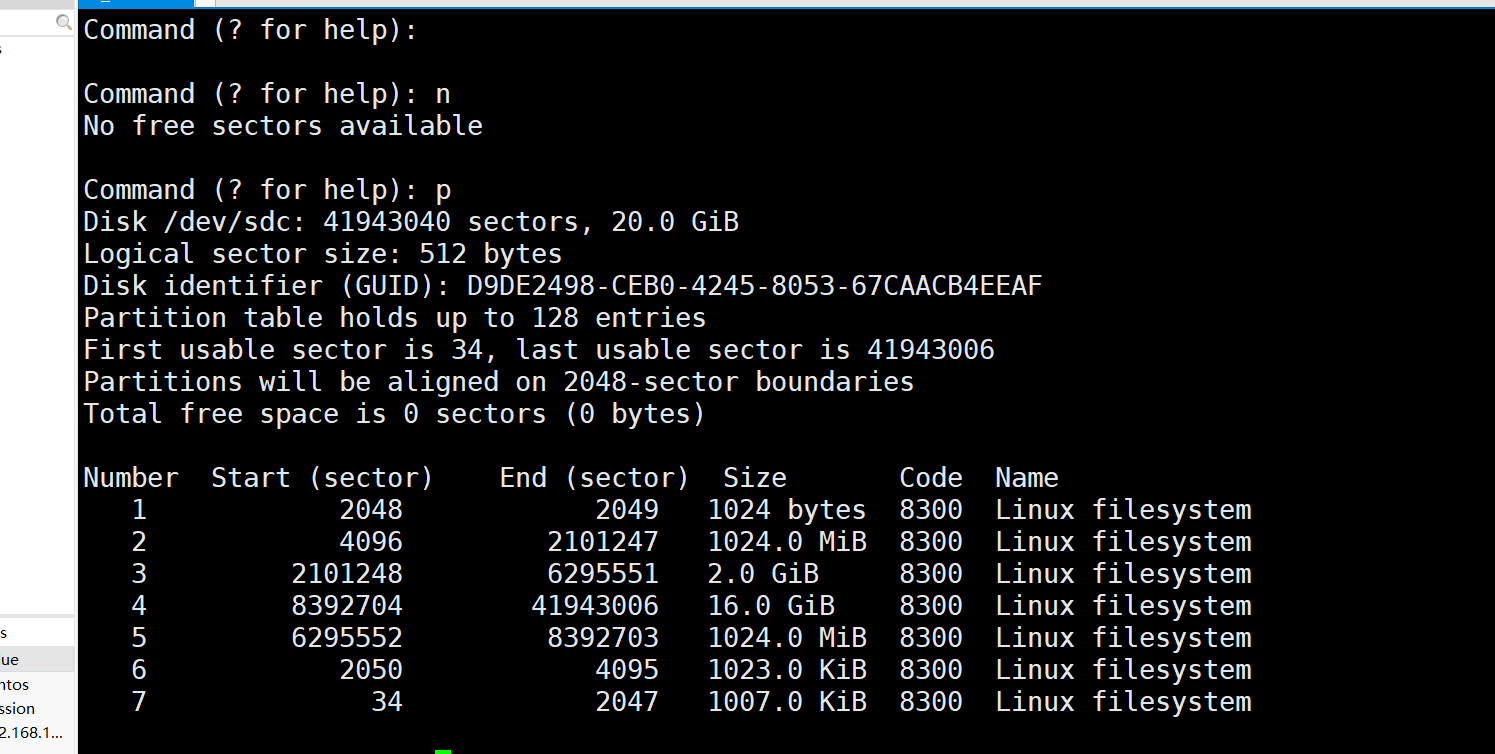
保存之后,lsblk看一下。

1K + 1G + 2G + 16G + 1G + 1023K + 1007K = 20G1M1007K,唉,怎么比20G还多?事实上SDB的几个分区加起来是20G1M1K,这我只能说我也不是太清楚了。
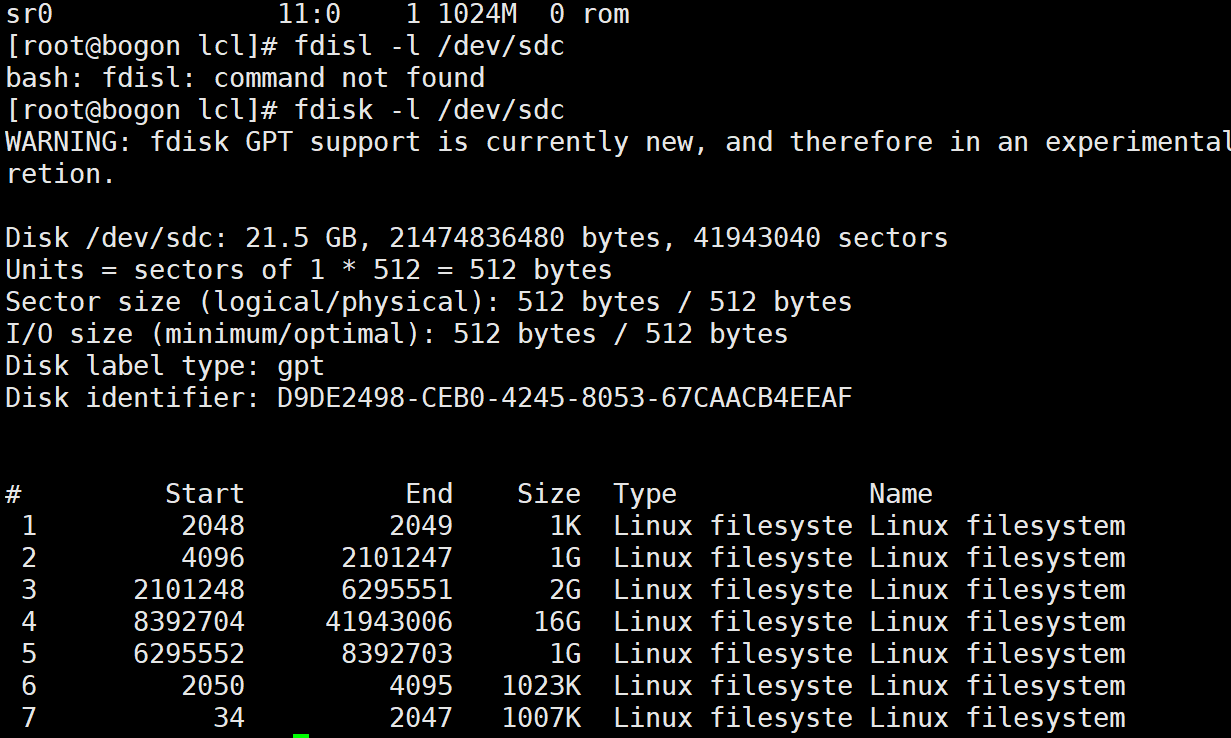
用一个分区就好,不然的话。

当然你还可以还这么看分区。
许
不过有的系统可能需要先partprobe / dev / sdb一下,刷新一下。
到这一步,我们只是创建了分区而已,但是里面还没有文件系统,什么叫文件系统呢?

不同的文件系统文件组织方式是不一样的,窗户的文件树根目录是和你的卷有关系的,比如说我的计算机里有CDEF四个盘,就有四个根目录。而在linux一般只有一个根目录,就是/。
格式化

简单地说,格式化就是在硬盘里构建文件系统,让Linux的认识它。当然如果对有数据地硬盘格式化,结果就是丢失数据。
格式化

文件系统有很多种,xfs和ext4只是其中的一种.windows里面一般是NTFS.mkfs就是make filesystem。

我们来试一下。

看到有BTRFS,CRAMFS等等文件系统。一般是对硬盘的某一个分区格式化,而不是对整个硬盘格式化。

不过也可以对整个硬盘格式化。-F强制即可。

看到格式化会分几个区域,一些是给元数据称之为元数据的。

还有一些是给数据的。其中有一个BSIZE = 4096的意思就是说,存储文件的最小单位,块的大小是4KB,即使一个文件只有1KB,它也占一个块,如果一个文件10K,应该是占三个块了。基本上默认的块都是4K,但是这个是可以改的。



到这一步格式化就完成了,但是我们怎么从这个磁盘里读文件,怎么往这个磁盘里写文件,怎么管理文件呢?你对着一个设备文件怎么实现上面的功能?这就需要用到挂载这个概念。
这里再说一下两列8,0是什么意思,8是主设备号,如果这个数字一样,表示是同一种设备,后面的0,1,2,16等是副设备号,用来区分都是8这种主设备的设备。

设备文件的这种LL的格式和其它文件是不一样的。一般的文件那个位置都是文件大小。

挂载

我们插ü盘的时候其实就有了一个自动挂载的过程.linux里面的挂载呢,就是要把设备文件和文件树中已存在的目录对应起来,挂载这个词其实很形象,就相是把一个存储设备挂在了文件树上面,设备文件对应的文件树中的目录被称为挂载点。

没有挂载之前,我们在文件系统里是看不到上面格式化的分区或者硬盘的。但是挂载之后就可以,但是注意挂载点一定要是已存在的目录,挂载的命令是mount -t是指定文件系统,不给的话会自动识别的,-o是挂载选项,RO代表只读,-a是挂载所有在fstab文件里提到的挂载点,也可以不给,这种使用坐骑命令的方式称为手动挂载,因为重启的话挂载点就没了,必须要再次挂载。


系统默认的挂载点是在到/ mnt里面,但是你可以随意挂载的。
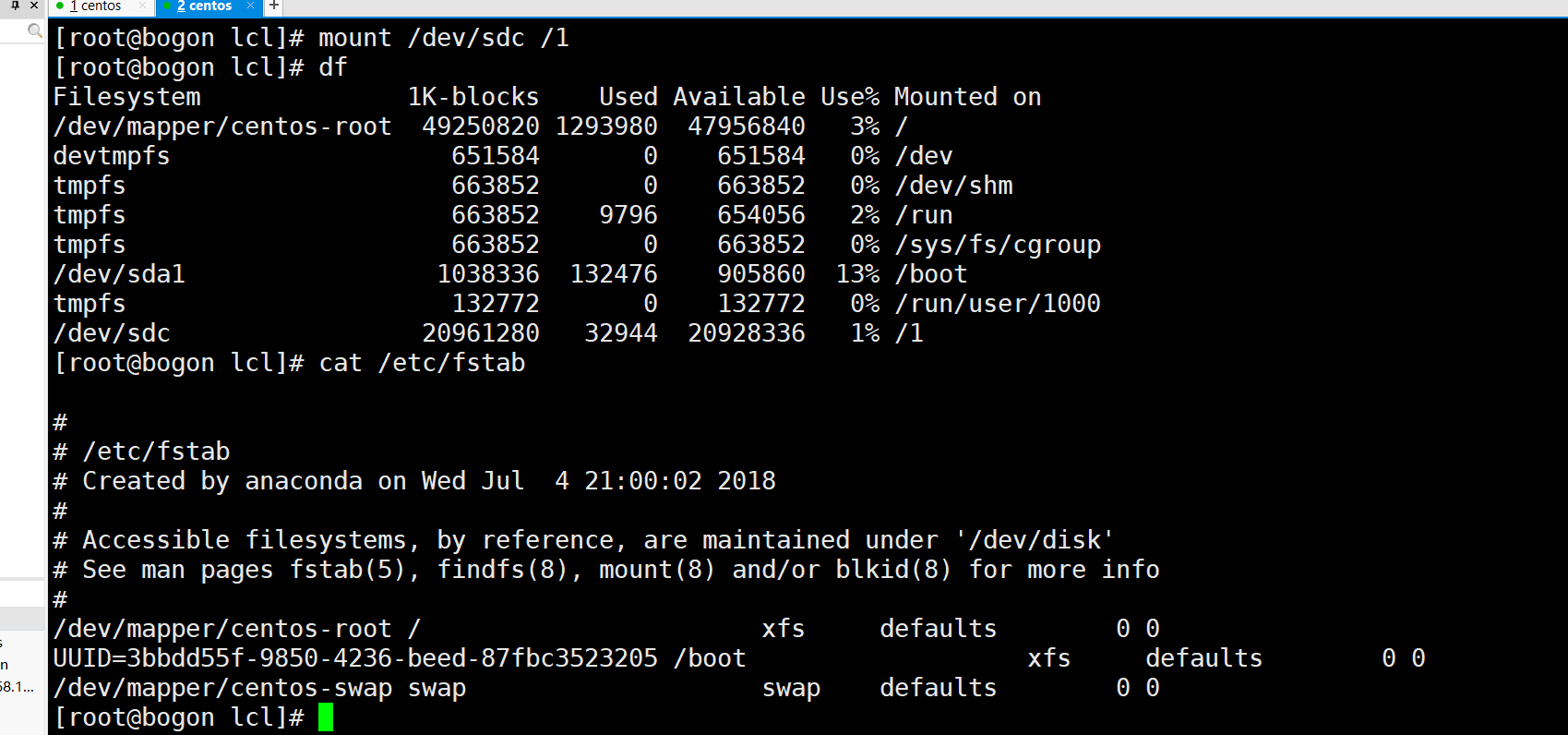
看到这种挂载是没有改变/ etc / fstab中配置文件的内容的,所以重启还得重现挂载。
那么一劳永逸的方式就是直接修改/ etc / fstab中了。

这第一列的参数是需要挂载的设备,第二列是挂载点,第三列是文件系统,第四列是挂载选项,就是前面-o ro那个东西,后面的两个0,第一个是开机不备份,第二个是开机不检查的意思。弄完以后不需要重启,可以用mount -a来挂载。

这个报错是因为我们当时格式化sdb2的时候用的是EXT4。回去该一下/ etc / fstab中就行。


看到的/ dev / sdb2就挂载到了/ 1处,而的/ dev / SDC回到了我们一开始给它的挂载点的/ mnt /磁盘1。

卸除取消挂载也是一次性的,不会改变/ etc / fstab中里面的内容,看到设备对于挂载点是有时间先后的竞争关系的,都是后来居上,但是如果山中无老虎,猴子称大王,就是说的/ dev / sdb2取消挂载/ 1是,的/ dev / SDC就挂上去了,如果sdb2又挂上去了,那么的/ dev / SDC的挂载点就有退出的/ mnt / disk1的了。


还有一种使用UUID的方式来挂载的。什么是UUID呢?参考了https://www.cnblogs.com/phpfans/p/5087899.html



如何得到的UUID呢?就用到了BLKID了。

然后我们可以修改/ etc / fstab中了。


举个例子理解一下挂载,文件是存在硬盘里面的。

把/ 1挂载点取消,/ 1/1就找不到了。

重新挂载呢,又可以查看了,说明呢,文件时切实地存在硬盘里面的你挂不挂载,它都在那里,但是只有挂载上去你才能看到而已。
基本分区明显的缺点就是不能扩容,空间满了就没办法了,下一讲是逻辑卷,可以解决扩容问题。