前言
poi的读取的三种模式
- eventmodel方式,基于事件驱动,SAX的方式解析excel(.xlsx是基于OOXML的),CPU和内存消耗非常低,但是只能读不能写
- usermodel,就是我们一般使用的方式,这种方式可以读可以写,但是CPU和内存消耗非常大
- SXSSF,POI3.8以后开始支持,这种方式只能写excel
依赖包
<!-- apache poi 操作Microsoft Document -->
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>3.17</version>
</dependency>
<!-- Apache POI - Java API To Access Microsoft Format Files -->
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>3.17</version>
</dependency>
<!-- Apache POI - Java API To Access Microsoft Format Files -->
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml-schemas</artifactId>
<version>3.17</version>
</dependency>
<!-- poi eventmodel方式 依赖包 -->
<dependency>
<groupId>xerces</groupId>
<artifactId>xercesImpl</artifactId>
<version>2.11.0</version>
</dependency>一、SXSSF (Since POI 3.8 beta3)
说明
自3.8-beta3以来,POI提供了一个低内存占用的SXSSF API,它构建在XSSF之上。
SXSSF是一个兼容于api的XSSF的流扩展,当需要生成非常大的电子表格时,它将被使用,而堆空间是有限的。SXSSF通过限制对滑动窗口中的行的访问来实现它的低内存占用,而XSSF允许访问文档中的所有行。不再出现在窗口中的较老的行变得不可访问,因为它们被写到磁盘上。
在自动刷新模式中,可以指定存取窗口的大小,以便在内存中持有一定数量的行。当达到这个值时,额外一行的创建会导致从存取窗口删除最低索引的行,并将其写到磁盘上。或者,窗口大小可以被设置为动态增长;根据需要,可以通过显式调用flushRows(int keepRows)定期对其进行修剪。
由于实现的流特性,与XSSF相比有以下限制:
- 只有有限数量的行可以在某个时间点访问。
- 不支持Sheet.clone()。
- 不支持公式评估
下面的表格对POI的电子表格API的比较特性进行了比较:
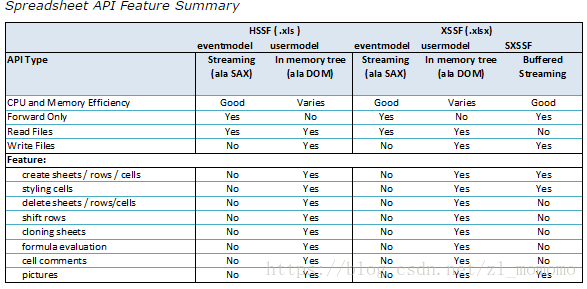
示例
下面的例子写了一张有百行窗口的表格。当行数达到101时,rownum=0的行会被刷新到磁盘,并从内存中删除,当rownum达到102时, rownum=1的行被刷新
@Test
public void test() throws Exception{
Long start = System.currentTimeMillis();
//内存最大存放100行数据 超过100自动刷新到硬盘中
SXSSFWorkbook wb = new SXSSFWorkbook(100); // keep 100 rows in memory, exceeding rows will be flushed to disk
Sheet sh = wb.createSheet();
for(int rownum = 0; rownum < 500000; rownum++){
Row row = sh.createRow(rownum);//一行
for(int cellnum = 0; cellnum < 10; cellnum++){
Cell cell = row.createCell(cellnum); //一行中一个方格
String address = new CellReference(cell).formatAsString();
cell.setCellValue(address);
}
}
FileOutputStream out = new FileOutputStream("f:/temp/sxssf.xlsx");
wb.write(out);
out.close();
// dispose of temporary files backing this workbook on disk
//处理在磁盘上支持本工作簿的临时文件
wb.dispose();
wb.close();
Long end = System.currentTimeMillis();
System.out.println(end - start + "ms"); //50万条数据写入大概在16秒
}下一个例子关闭了自动刷新(windows size=-1),代码手动控制将数据的部分写入磁盘
@Test
public void test3() throws IOException{
Long start = System.currentTimeMillis();
SXSSFWorkbook wb = new SXSSFWorkbook(-1); // turn off auto-flushing and accumulate all rows in memory
Sheet sh = wb.createSheet();
for(int rownum = 0; rownum < 1000; rownum++){
Row row = sh.createRow(rownum);
for(int cellnum = 0; cellnum < 10; cellnum++){
Cell cell = row.createCell(cellnum);
String address = new CellReference(cell).formatAsString();
cell.setCellValue(address);
}
// manually control how rows are flushed to disk
if(rownum % 100 == 0) {
((SXSSFSheet)sh).flushRows(100); // retain 100 last rows and flush all others
// ((SXSSFSheet)sh).flushRows() is a shortcut for ((SXSSFSheet)sh).flushRows(0),
// this method flushes all rows
}
}
FileOutputStream out = new FileOutputStream("f:/temp/sxssf.xlsx");
wb.write(out);
out.close();
// dispose of temporary files backing this workbook on disk
wb.dispose();
Long end = System.currentTimeMillis();
System.out.println(end - start + "ms"); //100条数据 650ms
}小结
其核心是减少存储在内存当中的数据,达到一定行数就存储到硬盘的临时文件中
二、XSSF and SAX (Event API)
说明
如果内存占用是一个问题,那么对于XSSF来说,您可以获得底层XML数据,并自己处理它。要使用这个API,您可以构建一个org.apache.poi.xssf.eventmodel.xssfreader的实例。这将在共享字符串表和样式上提供一个不错的接口。它提供了从文件的其余部分获取原始xml数据的方法,然后您将把这些数据传递给SAX。
背景
Excel2003与Excel2007
两个版本的最大行数和列数不同,2003版最大行数是65536行,最大列数是256列,2007版及以后的版本最大行数是1048576行,最大列数是16384列。
excel2003是以二进制的方式存储,这种格式不易被其他软件读取使用;而excel2007采用了基于XML的ooxml开放文档标准,ooxml使用XML和ZIP技术结合进行文件存储,XML是一个基于文本的格式,而且ZIP容器支持内容的压缩,所以其一大优势是可以大大减小文件的尺寸。
把xlsx后缀改为zip,打开文件发现目录
打开xl
sharedStrings.xml 共享字符串
styles.xml excel的样式数据
workbooks.xml excel的sheet
示例
package com.java.poi;
import java.io.InputStream;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.LinkedHashMap;
import java.util.List;
import java.util.Map;
import javax.xml.parsers.ParserConfigurationException;
import org.apache.poi.openxml4j.opc.OPCPackage;
import org.apache.poi.openxml4j.opc.PackageAccess;
import org.apache.poi.util.SAXHelper;
import org.apache.poi.xssf.eventusermodel.XSSFReader;
import org.apache.poi.xssf.model.SharedStringsTable;
import org.apache.poi.xssf.usermodel.XSSFRichTextString;
import org.xml.sax.Attributes;
import org.xml.sax.ContentHandler;
import org.xml.sax.InputSource;
import org.xml.sax.SAXException;
import org.xml.sax.XMLReader;
import org.xml.sax.helpers.DefaultHandler;
import org.xml.sax.helpers.XMLReaderFactory;
import com.mysql.jdbc.util.LRUCache;
public class ExampleEventUserModel {
public void processFirstSheet(String filename) throws Exception {
try(OPCPackage pkg = OPCPackage.open(filename,PackageAccess.READ);){
XSSFReader r = new XSSFReader( pkg );
SharedStringsTable sst = r.getSharedStringsTable();
XMLReader parser = fetchSheetParser(sst);
//process the first sheet
try(InputStream sheet = r.getSheetsData().next()){
InputSource sheetSource = new InputSource(sheet);
parser.parse(sheetSource);
}
}
}
public void processAllSheets(String filename) throws Exception {
try (OPCPackage pkg = OPCPackage.open(filename, PackageAccess.READ)) {
XSSFReader r = new XSSFReader(pkg);
SharedStringsTable sst = r.getSharedStringsTable();
XMLReader parser = fetchSheetParser(sst);
Iterator<InputStream> sheets = r.getSheetsData();
while (sheets.hasNext()) {
System.out.println("Processing new sheet:\n");
try (InputStream sheet = sheets.next()) {
InputSource sheetSource = new InputSource(sheet);
parser.parse(sheetSource);
}
System.out.println("");
}
}
}
public XMLReader fetchSheetParser(SharedStringsTable sst) throws SAXException, ParserConfigurationException {
XMLReader parser =SAXHelper.newXMLReader();
ContentHandler handler = new SheetHandler(sst);
parser.setContentHandler(handler);
return parser;
}
/**
* See org.xml.sax.helpers.DefaultHandler javadocs 重写 startElement characters endElements方法
*/
private static class SheetHandler extends DefaultHandler {
private SharedStringsTable sst;
private String lastContents;
private boolean nextIsString; //是否为string格式标识
private final LruCache<Integer,String> lruCache = new LruCache<>(60);
/*private int sheetIndex = -1;
private int curRow = 0;
private int curCol = 0;
private List<String> rowlist = new ArrayList<String>(); */
/**
* 缓存
* @author Administrator
*
* @param <A>
* @param <B>
*/
private static class LruCache<A,B> extends LinkedHashMap<A, B> {
private final int maxEntries;
public LruCache(final int maxEntries) {
super(maxEntries + 1, 1.0f, true);
this.maxEntries = maxEntries;
}
@Override
protected boolean removeEldestEntry(final Map.Entry<A, B> eldest) {
return super.size() > maxEntries;
}
}
private SheetHandler(SharedStringsTable sst) {
this.sst = sst;
}
/**
* 该方法自动被调用,每读一行调用一次,在方法中写自己的业务逻辑即可
* @param sheetIndex 工作簿序号
* @param curRow 处理到第几行
* @param rowList 当前数据行的数据集合
*/
/* public void optRow(int sheetIndex, int curRow, List<String> rowList) {
String temp = "";
for(String str : rowList) {
temp += str + "_";
}
this.rowlist.clear();
this.curRow++;
this.curCol=0;
System.out.println(temp);
} */
@Override
public void startElement(String uri, String localName, String name,
Attributes attributes) throws SAXException {
// c => cell 代表单元格
if(name.equals("c")) {
// Print the cell reference
//获取单元格的位置,如A1,B1
System.out.print(attributes.getValue("r") + " - ");
// Figure out if the value is an index in the SST 如果下一个元素是 SST 的索引,则将nextIsString标记为true
//单元格类型
String cellType = attributes.getValue("t");
//cellType值 s:字符串 b:布尔 e:错误处理
if(cellType != null && cellType.equals("s")) {
//标识为true 交给后续endElement处理
nextIsString = true;
} else {
nextIsString = false;
}
}
// Clear contents cache
lastContents = "";
}
/**
* 得到单元格对应的索引值或是内容值
* 如果单元格类型是字符串、INLINESTR、数字、日期,lastIndex则是索引值
* 如果单元格类型是布尔值、错误、公式,lastIndex则是内容值
*/
@Override
public void characters(char[] ch, int start, int length)
throws SAXException {
lastContents += new String(ch, start, length);
}
@Override
public void endElement(String uri, String localName, String name)
throws SAXException {
// Process the last contents as required.
// Do now, as characters() may be called more than once
if(nextIsString) {
int idx = Integer.parseInt(lastContents);
lastContents = lruCache.get(idx);
//如果内容为空 或者Cache中存在相同key 不保存到Cache中
if(lastContents == null &&!lruCache.containsKey(idx)){
lastContents = new XSSFRichTextString(sst.getEntryAt(idx)).toString();
lruCache.put(idx, lastContents);
}
nextIsString = false;
}
// v => contents of a cell
// Output after we've seen the string contents
if(name.equals("v")) {
System.out.println(lastContents);
//rowlist.add(curCol++,lastContents);
}else{
//如果标签名称为 row , 已到行尾
if(name.equals("row")){
//optRow(sheetIndex, curRow, rowlist);
System.out.println(lruCache);
lruCache.clear();
}
}
}
}
public static void main(String[] args) throws Exception {
new ExampleEventUserModel().processFirstSheet("F:/temp/template.xlsx");
}
}SheetHandler类说明:程序依次调用重写的startElement,characters,endElement方法
小结
excel2007后采用了基于XML的ooxml开放文档标准,通过操作原始xml数据的方法获得数据。
三、User API (HSSF and XSSF)
New Workbook
Workbook wb = new HSSFWorkbook();
...
try (OutputStream fileOut = new FileOutputStream("workbook.xls")) {
wb.write(fileOut);
}
Workbook wb = new XSSFWorkbook();
...
try (OutputStream fileOut = new FileOutputStream("workbook.xlsx")) {
wb.write(fileOut);
}
Files vs InputStreams
在打开一本工作簿时,不管是一个.xls HSSFWorkbook,还是一个.xlsx XSSFWorkbook,工作簿都可以从文件或InputStream中加载。使用File对象可以降低内存消耗,而InputStream则需要更多的内存,因为它必须缓冲整个文件。
如果使用WorkbookFactory,它很容易使用其中一个或另一个:
// Use a file
Workbook wb = WorkbookFactory.create(new File("MyExcel.xls"));
// Use an InputStream, needs more memory
Workbook wb = WorkbookFactory.create(new FileInputStream("MyExcel.xlsx"));如果直接使用HSSFWorkbook或XSSFWorkbook,您通常应该通过 NPOIFSFileSystem或OPCPackage的使用来完全控制生命周期(包括在完成时关闭文件):
// HSSFWorkbook, File
NPOIFSFileSystem fs = new NPOIFSFileSystem(new File("file.xls"));
HSSFWorkbook wb = new HSSFWorkbook(fs.getRoot(), true);
....
fs.close();
// HSSFWorkbook, InputStream, needs more memory
NPOIFSFileSystem fs = new NPOIFSFileSystem(myInputStream);
HSSFWorkbook wb = new HSSFWorkbook(fs.getRoot(), true);
// XSSFWorkbook, File
OPCPackage pkg = OPCPackage.open(new File("file.xlsx"));
XSSFWorkbook wb = new XSSFWorkbook(pkg);
....
pkg.close();
// XSSFWorkbook, InputStream, needs more memory
OPCPackage pkg = OPCPackage.open(myInputStream);
XSSFWorkbook wb = new XSSFWorkbook(pkg);
....
pkg.close();小结:
数据量比较小使用NPOIFSFileSystem或OPCPackage来操作excel,并尽可能使用文件对象参数