最近在github上学习一个前端项目
主要是利用 React / Node 实现的应用,代码虽然不难,但涉及的东西很多,所以我把我最近学到的东西,作为笔记写在这里,供我以后使用,或者大家参考,有什么问题还请大佬指点
主要是利用 React / Node 实现的应用,代码虽然不难,但涉及的东西很多,所以我把我最近学到的东西,作为笔记写在这里,供我以后使用,或者大家参考,有什么问题还请大佬指点~~~
MongoDB
- 安装
安装其实不难,就是现在有点卡,附上官网机票:

或者我的百度云盘
链接:
密码:0e3u
还有GUI下载,可以直接窗口查看数据,不用命令行
链接:
密码:mj0l
英文文档
当然还有中文翻译文档mongoose文档 当然还有中文翻译文档
链接:
密码:idl7
或者你可以去菜鸟教程上学习,机票:

- 使用
在安装完成后,你需要在你的安装目录下,新建(ctrl+shift+n)几个文件夹,如下图示
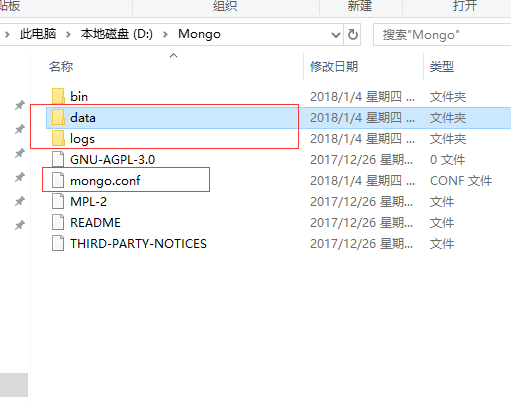
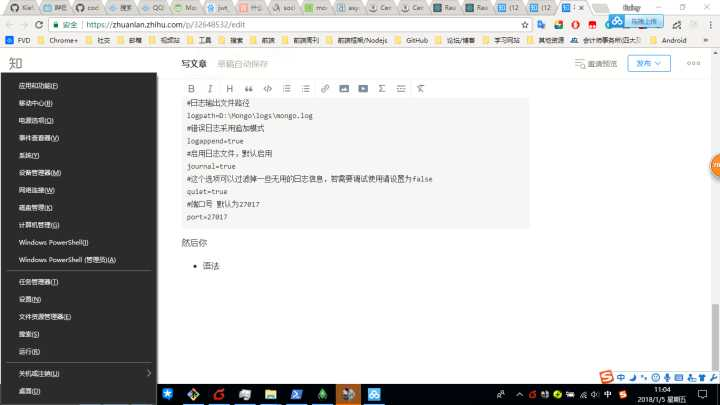
其中mongo.conf配置如下
#数据库路径
dbpath=D:\Mongo\data
#日志输出文件路径
logpath=D:\Mongo\logs\mongo.log
#错误日志采用追加模式
logappend=true
#启用日志文件,默认启用
journal=true
#这个选项可以过滤掉一些无用的日志信息,若需要调试使用请设置为false
quiet=true
#端口号 默认为27017
port=27017
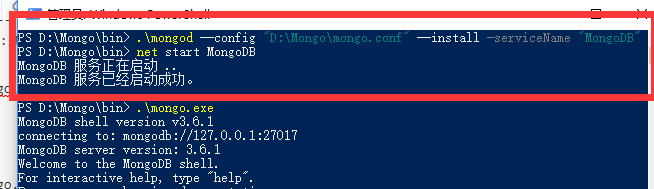
然后你win+x打开windows powershell(管理员)
cd进入你的安装目录下的bin目录,执行以下命令
./mongod --config 'xxxxx\mongo.conf'
xxxxx就是你的安装目录,我的目录是D:/Mongo
所以我执行
./mongod --config 'D:\Mongo\mongo.conf'
然后打开127.0.0.1:27017
你会看到一段英文的话,就开启成功了
下面教下免去这种麻烦的启动方式
./mongod --config 'D:\Mongo\mongo.conf' --install --serviceName 'MongoDB'
net satrt MongoDB
如果你出现服务器名无效的话,有以下解决方案:
- 你使用不得管理员cmd,请切换cmd
- 将你之前的服务停止并且完全删干净(windows下使用sc命令)。确保你下载的mongodb和系统位数匹配请务必使用“管理员权限”打开cmd命令行,然后输入:
D:\Mongo\bin\mongod.exe --dbpath "D:\Mongo\db" --logpath "D:\Mongo\db\db.log" --install --serviceName "mongo" --logappend --directoryperdb
- 语法
创建数据库的语法格式如下:
use DATABASE_NAME
删除数据库的语法格式如下:
db.dropDatabase()
使用 insert() 或 save() 方法向集合中插入文档,语法如下:
db.COLLECTION_NAME.insert(document)
更新已存在的文档。语法格式如下:
db.collection.update(
<query>,
<update>,
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>
}
)
参数说明:
- query : update的查询条件,类似sql update查询内where后面的。
- update : update的对象和一些更新的操作符(如$,$inc...)等,也可以理解为sql update查询内set后面的
- upsert : 可选,这个参数的意思是,如果不存在update的记录,是否插入objNew,true为插入,默认是false,不插入。
- multi : 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。
- writeConcern :可选,抛出异常的级别。
删除文档
db.collection.remove(
<query>,
{
justOne: <boolean>,
writeConcern: <document>
}
)
参数说明:
- query :(可选)删除的文档的条件。
- justOne : (可选)如果设为 true 或 1,则只删除一个文档。
- writeConcern :(可选)抛出异常的级别。
查询数据的语法格式如下:
db.collection.find(query, projection)
- query :可选,使用查询操作符指定查询条件
- projection :可选,使用投影操作符指定返回的键。查询时返回文档中所有键值, 只需省略该参数即可(默认省略)。
如果你需要以易读的方式来读取数据,可以使用 pretty() 方法,语法格式如下:
>db.col.find().pretty()
pretty() 方法以格式化的方式来显示所有文档。
条件操作符有:
- (>) 大于 - $gt
- (<) 小于 - $lt
- (>=) 大于等于 - $gte
- (<= ) 小于等于 - $lte
limit()方法基本语法如下所示:
>db.COLLECTION_NAME.find().limit(NUMBER)
sort()方法基本语法如下所示:
>db.COLLECTION_NAME.find().sort({KEY:1})
ensureIndex() 方法来创建索引。
>db.COLLECTION_NAME.ensureIndex({KEY:1})
语法中 Key 值为你要创建的索引字段,1为指定按升序创建索引,如果你想按降序来创建索引指定为-1即可。
MongoDB 的对象 Id(ObjectId)。
ObjectId 是一个12字节 BSON 类型数据,有以下格式:
- 前4个字节表示时间戳
- 接下来的3个字节是机器标识码
- 紧接的两个字节由进程id组成(PID)
- 最后三个字节是随机数。
MongoDB中存储的文档必须有一个"_id"键。这个键的值可以是任何类型的,默认是个ObjectId对象。
在一个集合里面,每个文档都有唯一的"_id"值,来确保集合里面每个文档都能被唯一标识。
http://socke.io
一.http://Socket.IO的介绍Socket.IO一.Socket.IO的介绍
http://Socket.IO支持及时、双向与基于事件的交流。它可以在每个平台、每个浏览器和每个设备上工作,可靠性和速度同样稳定。
- 实时分析:将数据推送到客户端,这些客户端会被表示为实时计数器,图表或日志客户。
- 实时通信和聊天:只需几行代码便可写成一个http://Socket.IO的”Hello,World”聊天应用。
- 二进制流传输:从1.0版本开始,http://Socket.IO支持任何形式的二进制文件传输,例如:图片,视频,音频等。
- 文档合并:允许多个用户同时编辑一个文档,并且能够看到每个用户做出的修改。
官方上提供了2个demo:多人聊天室、多人玩游戏。大家可以去官网试一试。
客户端socket.on()监听的事件:Socket.IO - Chat客户端socket.on()监听的事件:
- 连接:
connect:连接成功
connecting:正在连接
disconnect:断开连接
- 失败
connect_failed:连接失败
error:错误发生,并且无法被其他事件类型所处理
message:同服务器端message事件
anything:同服务器端anything事件 - 重连
reconnect_failed:重连失败
reconnect:成功重连
reconnecting:正在重连 - 第一次连接,事件触发顺序
connecting->connect;当失去连接时,事件触发顺序为:disconnect->reconnecting(可能进行多次)->connecting->reconnect->connect。
服务端
io.on('connection',function(socket));//监听客户端连接,回调函数会传递本次连接的socket
io.sockets.emit('String',data);//给所有客户端广播消息
io.sockets.socket(socketid).emit('String', data);//给指定的客户端发送消息
socket.on('String',function(data));//监听客户端发送的信息
socket.emit('String', data);//给该socket的客户端发送消息
广播消息
//给除了自己以外的客户端广播消息
socket.broadcast.emit("msg",{data:"hello,everyone"});
//给所有客户端广播消息
io.sockets.emit("msg",{data:"hello,all"});
分组
socket.on('group1', function (data) {
socket.join('group1');
});
socket.on('group2',function(data){
socket.join('group2');
});
客户端发送
socket.emit('group1'),就可以加入group1分组;
socket.emit('group2'),就可以加入group2分组;
一个客户端可以存在多个分组(订阅模式)
踢出分组
socket.leave(data.room);
对分组中的用户发送信息
//不包括自己
socket.broadcast.to('group1').emit('event_name', data);
//包括自己
io.sockets.in('group1').emit('event_name', data);
broadcast方法允许当前socket client不在该分组内
获取连接的客户端socket
io.sockets.clients().forEach(function (socket) {
//.....
})
获取分组信息
//获取所有房间(分组)信息 io.sockets.manager.rooms
//来获取此socketid进入的房间信息 io.sockets.manager.roomClients[socket.id]
//获取particular room中的客户端,返回所有在此房间的socket实例
io.sockets.clients('particular room')
另一种分组方式
io.of('/some').on('connection', function (socket) {
socket.on('test', function (data) {
socket.broadcast.emit('event_name',{});
});
});
客户端
var socket = io.connect('ws://103.31.201.154:5555/some')
socket.on('even_name',function(data){
console.log(data);
})
客户端都链接到ws://103.31.201.154:5555 但是服务端可以通过io.of('/some')将其过滤出来。
另外,http://Socket.IO提供了4个配置的API:io.configure, io.set, io.enable, io.disable。其中io.set对单项进行设置,io.enable和io.disable用于单项设置布尔型的配置。io.configure可以让你对不同的生产环境(如devlopment,test等等)配置不同的参数。
2. 客户端
建立一个socket连接
var socket = io("ws://103.31.201.154:5555");
监听服务消息
socket.on('msg',function(data){
socket.emit('msg', {rp:"fine,thank you"}); //向服务器发送消息
console.log(data);
});
socket.on("String",function(data)) 监听服务端发送的消息 Sting参数与服务端emit第一个参数相同
监听socket断开与重连。
socket.on('disconnect', function() {
console.log("与服务其断开");
});
socket.on('reconnect', function() {
console.log("重新连接到服务器");
});
原文:http://www.cnblogs.com/xiezhengcai/p/3956401.html
async
Async的内容分为三部分:
流程控制:简化十种常见流程的处理
- series: 串行执行,一个函数数组中的每个函数,每一个函数执行完成之后才能执行下一个函数。
- parallel: 并行执行多个函数,每个函数都是立即执行,不需要等待其它函数先执行。传给最终callback的数组中的数据按照tasks中声明的顺序,而不是执行完成的顺序。
- whilst: 相当于while,但其中的异步调用将在完成后才会进行下一次循环。
- doWhilst: 相当于do…while, doWhilst交换了fn,test的参数位置,先执行一次循环,再做test判断。
- until: until与whilst正好相反,当test为false时循环,与true时跳出。其它特性一致。
- doUntil: doUntil与doWhilst正好相反,当test为false时循环,与true时跳出。其它特性一致。
- forever: 无论条件循环执行,如果不出错,callback永远不被执行。
- waterfall: 按顺序依次执行一组函数。每个函数产生的值,都将传给下一个。
- compose: 创建一个包括一组异步函数的函数集合,每个函数会消费上一次函数的返回值。把f(),g(),h()异步函数,组合成f(g(h()))的形式,通过callback得到返回值。
- applyEach: 实现给一数组中每个函数传相同参数,通过callback返回。如果只传第一个参数,将返回一个函数对象,我可以传参调用。
- queue: 是一个串行的消息队列,通过限制了worker数量,不再一次性全部执行。当worker数量不够用时,新加入的任务将会排队等候,直到有新的worker可用。
- cargo: 一个串行的消息队列,类似于queue,通过限制了worker数量,不再一次性全部执行。不同之处在于,cargo每次会加载满额的任务做为任务单元,只有任务单元中全部执行完成后,才会加载新的任务单元。
- auto: 用来处理有依赖关系的多个任务的执行。
- iterator: 将一组函数包装成为一个iterator,初次调用此iterator时,会执行定义中的第一个函数并返回第二个函数以供调用。
- apply: 可以让我们给一个函数预绑定多个参数并生成一个可直接调用的新函数,简化代码。
- nextTick: 与nodejs的nextTick一样,再最后调用函数。
- times: 异步运行,times可以指定调用几次,并把结果合并到数组中返回
- timesSeries: 与time类似,唯一不同的是同步执行
集合处理:如何使用异步操作处理集合中的数据
Async提供了很多针对集合的函数,可以简化我们对集合进行异步操作时的步骤。如下:
- each: 如果想对同一个集合中的所有元素都执行同一个异步操作。
- map: 对集合中的每一个元素,执行某个异步操作,得到结果。所有的结果将汇总到最终的callback里。与each的区别是,each只关心操作不管最后的值,而map关心的最后产生的值。
- filter: 使用异步操作对集合中的元素进行筛选, 需要注意的是,iterator的callback只有一个参数,只能接收true或false。
- reject: reject跟filter正好相反,当测试为true时则抛弃
- reduce: 可以让我们给定一个初始值,用它与集合中的每一个元素做运算,最后得到一个值。reduce从左向右来遍历元素,如果想从右向左,可使用reduceRight。
- detect: 用于取得集合中满足条件的第一个元素。
- sortBy: 对集合内的元素进行排序,依据每个元素进行某异步操作后产生的值,从小到大排序。
- some: 当集合中是否有至少一个元素满足条件时,最终callback得到的值为true,否则为false.
- every: 如果集合里每一个元素都满足条件,则传给最终回调的result为true,否则为false
- concat: 将多个异步操作的结果合并为一个数组。
工具类:几个常用的工具类
Async中提供了几个工具类,给我们提供一些小便利:
- memoize: 让某一个函数在内存中缓存它的计算结果。对于相同的参数,只计算一次,下次就直接拿到之前算好的结果。
- unmemoize: 让已经被缓存的函数,返回不缓存的函数引用。
- log: 执行某异步函数,并记录它的返回值,日志输出。
- dir: 与log类似,不同之处在于,会调用浏览器的console.dir()函数,显示为DOM视图。
- noConflict: 如果之前已经在全局域中定义了async变量,当导入本async.js时,会先把之前的async变量保存起来,然后覆盖它。仅仅用于浏览器端,在nodejs中没用,这里无法演示。
JWT
Json web token (JWT)
为了在网络应用环境间传递声明而执行的一种基于JSON的开放标准((RFC 7519).
该token被设计为紧凑且安全的,特别适用于分布式站点的单点登录(SSO)场景。
JWT的声明一般被用来在身份提供者和服务提供者间传递被认证的用户身份信息,
以便于从资源服务器获取资源,也可以增加一些额外的其它业务逻辑所必须的声明信息,
该token也可直接被用于认证,也可被加密。
基于token的鉴权机制
基于token的鉴权机制类似于http协议也是无状态的,它不需要在服务端去保留用户的认证信息或者会话信息。这就意味着基于token认证机制的应用不需要去考虑用户在哪一台服务器登录了,这就为应用的扩展提供了便利。
流程上是这样的:
- 用户使用用户名密码来请求服务器
- 服务器进行验证用户的信息
- 服务器通过验证发送给用户一个token
- 客户端存储token,并在每次请求时附送上这个token值
- 服务端验证token值,并返回数据
这个token必须要在每次请求时传递给服务端,它应该保存在请求头里, 另外,服务端要支持CORS(跨来源资源共享)策略,一般我们在服务端这么做就可以了Access-Control-Allow-Origin: *。
JWT长什么样?
JWT是由三段信息构成的,将这三段信息文本用.链接一起就构成了Jwt字符串。就像这样:
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiYWRtaW4iOnRydWV9.TJVA95OrM7E2cBab30RMHrHDcEfxjoYZgeFONFh7HgQ
JWT的构成
第一部分我们称它为头部(header)
第二部分我们称其为载荷(payload, 类似于飞机上承载的物品)
第三部分是签证(signature).
header
jwt的头部承载两部分信息:
- 声明类型,这里是jwt
- 声明加密的算法 通常直接使用 HMAC SHA256
完整的头部就像下面这样的JSON:
{
'typ': 'JWT',
'alg': 'HS256'
}
然后将头部进行base64加密(该加密是可以对称解密的),构成了第一部分.
eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9
playload
载荷就是存放有效信息的地方。这个名字像是特指飞机上承载的货品,这些有效信息包含三个部分
- 标准中注册的声明
- 公共的声明
- 私有的声明
标准中注册的声明 (建议但不强制使用) :
- iss: jwt签发者
- sub: jwt所面向的用户
- aud: 接收jwt的一方
- exp: jwt的过期时间,这个过期时间必须要大于签发时间
- nbf: 定义在什么时间之前,该jwt都是不可用的.
- iat: jwt的签发时间
- jti: jwt的唯一身份标识,主要用来作为一次性token,从而回避重放攻击。
公共的声明 :
公共的声明可以添加任何的信息,一般添加用户的相关信息或其他业务需要的必要信息.但不建议添加敏感信息,因为该部分在客户端可解密.
私有的声明 :
私有声明是提供者和消费者所共同定义的声明,一般不建议存放敏感信息,因为base64是对称解密的,意味着该部分信息可以归类为明文信息。
定义一个payload:
{
"sub": "1234567890",
"name": "John Doe",
"admin": true
}
然后将其进行base64加密,得到Jwt的第二部分。
eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiYWRtaW4iOnRydWV9
signature
jwt的第三部分是一个签证信息,这个签证信息由三部分组成:
- header (base64后的)
- payload (base64后的)
- secret
这个部分需要base64加密后的header和base64加密后的payload使用.连接组成的字符串,然后通过header中声明的加密方式进行加盐secret组合加密,然后就构成了jwt的第三部分。
// javascript
var encodedString = base64UrlEncode(header) + '.' + base64UrlEncode(payload);
var signature = HMACSHA256(encodedString, 'secret'); // TJVA95OrM7E2cBab30RMHrHDcEfxjoYZgeFONFh7HgQ
将这三部分用.连接成一个完整的字符串,构成了最终的jwt:
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiYWRtaW4iOnRydWV9.TJVA95OrM7E2cBab30RMHrHDcEfxjoYZgeFONFh7HgQ
注意:secret是保存在服务器端的,jwt的签发生成也是在服务器端的,secret就是用来进行jwt的签发和jwt的验证,所以,它就是你服务端的私钥,在任何场景都不应该流露出去。一旦客户端得知这个secret, 那就意味着客户端是可以自我签发jwt了。
如何应用
一般是在请求头里加入Authorization,并加上Bearer标注:
fetch('api/user/1', {
headers: {
'Authorization': 'Bearer ' + token
}
})
服务端会验证token,如果验证通过就会返回相应的资源。整个流程就是这样的:
jwt-diagram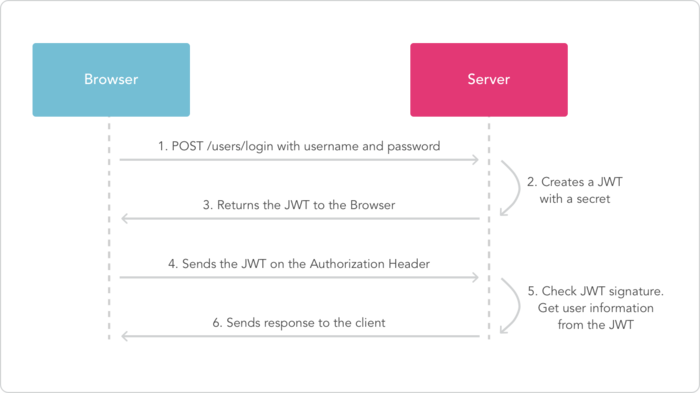 jwt-diagram
jwt-diagram
总结
优点
因为json的通用性,所以JWT是可以进行跨语言支持的,像JAVA,JavaScript,NodeJS,PHP等很多语言都可以使用。
- 因为有了payload部分,所以JWT可以在自身存储一些其他业务逻辑所必要的非敏感信息。
- 便于传输,jwt的构成非常简单,字节占用很小,所以它是非常便于传输的。
- 它不需要在服务端保存会话信息, 所以它易于应用的扩展
安全相关
- 不应该在jwt的payload部分存放敏感信息,因为该部分是客户端可解密的部分。
- 保护好secret私钥,该私钥非常重要。
- 如果可以,请使用https协议
express

基于 Node.js 平台,快速、开放、极简的 web 开发框架。
路由
路由是指如何定义应用的端点(URIs)以及如何响应客户端的请求。
路由是由一个 URI、HTTP 请求(GET、POST等)和若干个句柄组成,它的结构如下: app.METHOD(path, [callback...], callback), app 是 express对象的一个实例, METHOD 是一个 HTTP 请求方法, path 是服务器上的路径, callback 是当路由匹配时要执行的函数。
下面是一个基本的路由示例:
var express = require('express');
var app = express();
// respond with "hello world" when a GET request is made to the homepage
app.get('/', function(req, res) {
res.send('hello world');
});
路由方法
路由方法源于 HTTP 请求方法,和 express 实例相关联。
下面这个例子展示了为应用跟路径定义的 GET 和 POST 请求:
// GET method route
app.get('/', function (req, res) {
res.send('GET request to the homepage');
});
// POST method route
app.post('/', function (req, res) {
res.send('POST request to the homepage');
});
Express 定义了如下和 HTTP 请求对应的路由方法: get, post, put, head, delete, options, trace, copy, lock, mkcol, move, purge, propfind, proppatch, unlock, report, mkactivity, checkout, merge, m-search, notify, subscribe, unsubscribe, patch, search, 和 connect。
有些路由方法名不是合规的 JavaScript 变量名,此时使用括号记法,比如: app['m-search']('/', function ...
app.all() 是一个特殊的路由方法,没有任何 HTTP 方法与其对应,它的作用是对于一个路径上的所有请求加载中间件。
在下面的例子中,来自 “/secret” 的请求,不管使用 GET、POST、PUT、DELETE 或其他任何 http 模块支持的 HTTP 请求,句柄都会得到执行。
app.all('/secret', function (req, res, next) {
console.log('Accessing the secret section ...');
next(); // pass control to the next handler
});
路由路径
路由路径和请求方法一起定义了请求的端点,它可以是字符串、字符串模式或者正则表达式。
Express 使用 path-to-regexp 匹配路由路径,请参考文档查阅所有定义路由路径的方法。 Express Route Tester 是测试基本 Express 路径的好工具,但不支持模式匹配。
查询字符串不是路由路径的一部分。
使用字符串的路由路径示例:
// 匹配根路径的请求
app.get('/', function (req, res) {
res.send('root');
});
// 匹配 /about 路径的请求
app.get('/about', function (req, res) {
res.send('about');
});
// 匹配 /random.text 路径的请求
app.get('/random.text', function (req, res) {
res.send('random.text');
});
使用字符串模式的路由路径示例:
// 匹配 acd 和 abcd
app.get('/ab?cd', function(req, res) {
res.send('ab?cd');
});
// 匹配 abcd、abbcd、abbbcd等
app.get('/ab+cd', function(req, res) {
res.send('ab+cd');
});
// 匹配 abcd、abxcd、abRABDOMcd、ab123cd等
app.get('/ab*cd', function(req, res) {
res.send('ab*cd');
});
// 匹配 /abe 和 /abcde
app.get('/ab(cd)?e', function(req, res) {
res.send('ab(cd)?e');
});
字符 ?、+、* 和 () 是正则表达式的子集,- 和 . 在基于字符串的路径中按照字面值解释。
使用正则表达式的路由路径示例:
// 匹配任何路径中含有 a 的路径:
app.get(/a/, function(req, res) {
res.send('/a/');
});
// 匹配 butterfly、dragonfly,不匹配 butterflyman、dragonfly man等
app.get(/.*fly$/, function(req, res) {
res.send('/.*fly$/');
});
路由句柄
可以为请求处理提供多个回调函数,其行为类似 中间件。唯一的区别是这些回调函数有可能调用 next('route') 方法而略过其他路由回调函数。可以利用该机制为路由定义前提条件,如果在现有路径上继续执行没有意义,则可将控制权交给剩下的路径。
路由句柄有多种形式,可以是一个函数、一个函数数组,或者是两者混合,如下所示.
使用一个回调函数处理路由:
app.get('/example/a', function (req, res) {
res.send('Hello from A!');
});
使用多个回调函数处理路由(记得指定 next 对象):
app.get('/example/b', function (req, res, next) {
console.log('response will be sent by the next function ...');
next();
}, function (req, res) {
res.send('Hello from B!');
});
使用回调函数数组处理路由:
var cb0 = function (req, res, next) {
console.log('CB0');
next();
}
var cb1 = function (req, res, next) {
console.log('CB1');
next();
}
var cb2 = function (req, res) {
res.send('Hello from C!');
}
app.get('/example/c', [cb0, cb1, cb2]);
混合使用函数和函数数组处理路由:
var cb0 = function (req, res, next) {
console.log('CB0');
next();
}
var cb1 = function (req, res, next) {
console.log('CB1');
next();
}
app.get('/example/d', [cb0, cb1], function (req, res, next) {
console.log('response will be sent by the next function ...');
next();
}, function (req, res) {
res.send('Hello from D!');
});
响应方法
下表中响应对象(res)的方法向客户端返回响应,终结请求响应的循环。如果在路由句柄中一个方法也不调用,来自客户端的请求会一直挂起。
方法描述res.download()提示下载文件。res.end()终结响应处理流程。res.json()发送一个 JSON 格式的响应。res.jsonp()发送一个支持 JSONP 的 JSON 格式的响应。res.redirect()重定向请求。res.render()渲染视图模板。res.send()发送各种类型的响应。res.sendFile以八位字节流的形式发送文件。res.sendStatus()设置响应状态代码,并将其以字符串形式作为响应体的一部分发送。
app.route()
可使用 app.route() 创建路由路径的链式路由句柄。由于路径在一个地方指定,这样做有助于创建模块化的路由,而且减少了代码冗余和拼写错误。请参考 Router() 文档 了解更多有关路由的信息。
下面这个示例程序使用 app.route() 定义了链式路由句柄。
app.route('/book')
.get(function(req, res) {
res.send('Get a random book');
})
.post(function(req, res) {
res.send('Add a book');
})
.put(function(req, res) {
res.send('Update the book');
});
express.Router
可使用 express.Router 类创建模块化、可挂载的路由句柄。Router 实例是一个完整的中间件和路由系统,因此常称其为一个 “mini-app”。
下面的实例程序创建了一个路由模块,并加载了一个中间件,定义了一些路由,并且将它们挂载至应用的路径上。
在 app 目录下创建名为 birds.js 的文件,内容如下:
var express = require('express');
var router = express.Router();
// 该路由使用的中间件
router.use(function timeLog(req, res, next) {
console.log('Time: ', Date.now());
next();
});
// 定义网站主页的路由
router.get('/', function(req, res) {
res.send('Birds home page');
});
// 定义 about 页面的路由
router.get('/about', function(req, res) {
res.send('About birds');
});
module.exports = router;
然后在应用中加载路由模块:
var birds = require('./birds');
...
app.use('/birds', birds);
应用即可处理发自 /birds 和 /birds/about 的请求,并且调用为该路由指定的 timeLog 中间件。
使用中间件
Express 是一个自身功能极简,完全是由路由和中间件构成一个的 web 开发框架:从本质上来说,一个 Express 应用就是在调用各种中间件。
中间件(Middleware) 是一个函数,它可以访问请求对象(request object (req)), 响应对象(response object (res)), 和 web 应用中处于请求-响应循环流程中的中间件,一般被命名为 next 的变量。
中间件的功能包括:
- 执行任何代码。
- 修改请求和响应对象。
- 终结请求-响应循环。
- 调用堆栈中的下一个中间件。
如果当前中间件没有终结请求-响应循环,则必须调用 next() 方法将控制权交给下一个中间件,否则请求就会挂起。
Express 应用可使用如下几种中间件:
使用可选则挂载路径,可在应用级别或路由级别装载中间件。另外,你还可以同时装在一系列中间件函数,从而在一个挂载点上创建一个子中间件栈。
应用级中间件
应用级中间件绑定到 app 对象 使用 app.use() 和 app.METHOD(), 其中, METHOD 是需要处理的 HTTP 请求的方法,例如 GET, PUT, POST 等等,全部小写。例如:
var app = express();
// 没有挂载路径的中间件,应用的每个请求都会执行该中间件
app.use(function (req, res, next) {
console.log('Time:', Date.now());
next();
});
// 挂载至 /user/:id 的中间件,任何指向 /user/:id 的请求都会执行它
app.use('/user/:id', function (req, res, next) {
console.log('Request Type:', req.method);
next();
});
// 路由和句柄函数(中间件系统),处理指向 /user/:id 的 GET 请求
app.get('/user/:id', function (req, res, next) {
res.send('USER');
});
下面这个例子展示了在一个挂载点装载一组中间件。
// 一个中间件栈,对任何指向 /user/:id 的 HTTP 请求打印出相关信息
app.use('/user/:id', function(req, res, next) {
console.log('Request URL:', req.originalUrl);
next();
}, function (req, res, next) {
console.log('Request Type:', req.method);
next();
});
作为中间件系统的路由句柄,使得为路径定义多个路由成为可能。在下面的例子中,为指向 /user/:id 的 GET 请求定义了两个路由。第二个路由虽然不会带来任何问题,但却永远不会被调用,因为第一个路由已经终止了请求-响应循环。
// 一个中间件栈,处理指向 /user/:id 的 GET 请求
app.get('/user/:id', function (req, res, next) {
console.log('ID:', req.params.id);
next();
}, function (req, res, next) {
res.send('User Info');
});
// 处理 /user/:id, 打印出用户 id
app.get('/user/:id', function (req, res, next) {
res.end(req.params.id);
});
如果需要在中间件栈中跳过剩余中间件,调用 next('route') 方法将控制权交给下一个路由。 注意: next('route') 只对使用 app.VERB() 或 router.VERB() 加载的中间件有效。
// 一个中间件栈,处理指向 /user/:id 的 GET 请求
app.get('/user/:id', function (req, res, next) {
// 如果 user id 为 0, 跳到下一个路由
if (req.params.id == 0) next('route');
// 否则将控制权交给栈中下一个中间件
else next(); //
}, function (req, res, next) {
// 渲染常规页面
res.render('regular');
});
// 处理 /user/:id, 渲染一个特殊页面
app.get('/user/:id', function (req, res, next) {
res.render('special');
});
路由级中间件
路由级中间件和应用级中间件一样,只是它绑定的对象为 express.Router()。
var router = express.Router();
路由级使用 router.use() 或 router.VERB() 加载。
上述在应用级创建的中间件系统,可通过如下代码改写为路由级:
var app = express();
var router = express.Router();
// 没有挂载路径的中间件,通过该路由的每个请求都会执行该中间件
router.use(function (req, res, next) {
console.log('Time:', Date.now());
next();
});
// 一个中间件栈,显示任何指向 /user/:id 的 HTTP 请求的信息
router.use('/user/:id', function(req, res, next) {
console.log('Request URL:', req.originalUrl);
next();
}, function (req, res, next) {
console.log('Request Type:', req.method);
next();
});
// 一个中间件栈,处理指向 /user/:id 的 GET 请求
router.get('/user/:id', function (req, res, next) {
// 如果 user id 为 0, 跳到下一个路由
if (req.params.id == 0) next('route');
// 负责将控制权交给栈中下一个中间件
else next(); //
}, function (req, res, next) {
// 渲染常规页面
res.render('regular');
});
// 处理 /user/:id, 渲染一个特殊页面
router.get('/user/:id', function (req, res, next) {
console.log(req.params.id);
res.render('special');
});
// 将路由挂载至应用
app.use('/', router);
错误处理中间件
错误处理中间件有 4 个参数,定义错误处理中间件时必须使用这 4 个参数。即使不需要 next 对象,也必须在签名中声明它,否则中间件会被识别为一个常规中间件,不能处理错误。
错误处理中间件和其他中间件定义类似,只是要使用 4 个参数,而不是 3 个,其签名如下: (err, req, res, next)。
app.use(function(err, req, res, next) {
console.error(err.stack);
res.status(500).send('Something broke!');
});
内置中间件
从 4.x 版本开始,, Express 已经不再依赖 Connect 了。除了 express.static, Express 以前内置的中间件现在已经全部单独作为模块安装使用了。请参考 中间件列表。
express.static(root, [options])
express.static 是 Express 唯一内置的中间件。它基于 serve-static,负责在 Express 应用中提托管静态资源。
参数 root 指提供静态资源的根目录。
可选的 options 参数拥有如下属性。
属性描述类型缺省值dotfiles是否对外输出文件名以点(.)开头的文件。可选值为 “allow”、“deny” 和 “ignore”String“ignore”etag是否启用 etag 生成Booleantrueextensions设置文件扩展名备份选项Array[]index发送目录索引文件,设置为 false 禁用目录索引。Mixed“index.html”lastModified设置 Last-Modified头为文件在操作系统上的最后修改日期。可能值为 true 或 false。BooleantruemaxAge以毫秒或者其字符串格式设置 Cache-Control 头的 max-age 属性。Number0redirect当路径为目录时,重定向至 “/”。BooleantruesetHeaders设置 HTTP 头以提供文件的函数。Function
下面的例子使用了 express.static 中间件,其中的 options 对象经过了精心的设计。
var options = {
dotfiles: 'ignore',
etag: false,
extensions: ['htm', 'html'],
index: false,
maxAge: '1d',
redirect: false,
setHeaders: function (res, path, stat) {
res.set('x-timestamp', Date.now());
}
}
app.use(express.static('public', options));
每个应用可有多个静态目录。
app.use(express.static('public'));
app.use(express.static('uploads'));
app.use(express.static('files'));
第三方中间件
通过使用第三方中间件从而为 Express 应用增加更多功能。
安装所需功能的 node 模块,并在应用中加载,可以在应用级加载,也可以在路由级加载。
下面的例子安装并加载了一个解析 cookie 的中间件: cookie-parser
$ npm install cookie-parser
// 建议使用淘宝镜像npm install -g cnpm --registry=https://registry.npm.taobao.org
var express = require('express');
var app = express();
var cookieParser = require('cookie-parser');
// 加载用于解析 cookie 的中间件
app.use(cookieParser());
Webpack
我觉得这个大佬的教程很详细,大家可以试试,附上机票
之前学习webpack配置好的代码,都有解释,下载机票

const path = require('path');
// JS压缩插件
const uglify = require('uglifyjs-webpack-plugin');
const htmlPlugin = require('html-webpack-plugin');
const webpack = require('webpack');
const extractTextPlugin = require('extract-text-webpack-plugin');
const glob = require('glob');
// 使用这个插件必须配合extract-text-webpack-plugin这个插件,
const PuryfyCssPlugin = require('purifycss-webpack');
const entry = require('./webpack_config/entry_webpack.js')
const copyWebpackPlugin = require('copy-webpack-plugin');
// const website = {
// publicPath: "http://192.168.226.70:1717/"
// };
if(process.env.type == "build") {
var website = {
publicPath: "http://192.168.226.70:1717/"
}
} else {
var website = {
publicPath: "http://cdn.jspang.com/"
}
}
module.exports={
// 打包文件模块
// devtool: 'cheap-module-eval-source-map',
//入口文件的配置项
entry:{
entry: entry.path,
jquery: 'jquery',
vue: 'vue'
},
//出口文件的配置项
output:{
//输出的路径,用了Node语法
path: path.resolve(__dirname,'dist'),
//输出的文件名称
filename: '[name].js',
// 静态图片路径
publicPath: website.publicPath
},
//模块:例如解读CSS,图片如何转换,压缩
module:{
rules: [
{
// 用于匹配处理文件的扩展名的表达式,这个选项是必须进行配置的
test: /\.css$/,
// loader名称,就是你要使用模块的名称,这个选项也必须进行配置,否则报错
// use: ['css-loader', 'style-loader'],
use: extractTextPlugin.extract({
// 在webpack.config.js文件的output选项中,主要作用就是处理静态文件路径的。
fallback: 'style-loader',
// use: 'css-loader'
use: [
{ loader: 'css-loader', options: { importLoaders: 1} },
'postcss-loader']
})
}, {
test: /\.less$/,
use: [{
loader: 'style-loader'
}, {
loader: 'css-loader'
}, {
loader: 'less-loader'
}]
// use: extractTextPlugin.extract({
// use: [{
// loader: 'css-loader'
// }, {
// loader: 'less-loader'
// }, {
// // use style-loader in development
// fallback: 'style-loader'
// }]
// })
}, {
// /\.(png|jpg|gif)/是匹配图片文件后缀名称。
test: /\.(jpg|png|gif)$/,
// 是指定使用的loader和loader的配置参数。
use: [{
loader: 'url-loader',
options: {
// 是把小于500000B的文件打成Base64的格式,写入JS。
limit: 500000,
outputPath: 'images/'
}
}]
}, {
test: /\.(jsx|js)$/,
exclude: /node_modules/,
include: path.join(__dirname, 'src'),
use: [{
loader: 'babel-loader',
options: {
presets: [
'env', 'react'
]
}
}]
}, {
test: /\.(htm|html)$/i,
use: ['html-withimg-loader']
}
]
},
//插件,用于生产模版和各项功能
plugins:[
new HotModuleReplacementPlugin(),
new uglify(),
new htmlPlugin({
// 是对html文件进行压缩,removeAttrubuteQuotes是却掉属性的双引号。
minify: {
removeAttributeQuotes: true
},
// 为了开发中js有缓存效果,所以加入hash,这样可以有效避免缓存JS。
hash: true,
// 是要打包的html模版路径和文件名称。
template: './src/index.html'
}),
new extractTextPlugin("/css/index.css"),
// 使用这个插件必须配合extract-text-webpack-plugin这个插件,
new PuryfyCssPlugin({
// Give paths to parse for rules. These should be absolute!
paths: glob.sync(path.join(__dirname, 'src/*.html'))
}),
// ProvidePlugin是webpack自带的插件
new webpack.ProvidePlugin({
$: 'jquery'
}),
// 使用后会在JS中加上我们的版权或开发者声明。
new webpack.BannerPlugin('Rainy test~~~'),
// 优化组件
new webpack.optimize.CommonsChunkPlugin({
// name对应入口文件中的名字
name: ['jquery', 'vue'],
// 把文件打包到哪里,是一个路径
filename: 'assets/js/[name].js',
// 最小打包的文件模块数
minChunks: 2
}),
new copyWebpackPlugin([{
// 要打包的静态资源目录地址,这里的__dirname是指项目目录下,是node的一种语法,可以直接定位到本机的项目目录中。
from: __dirname + 'src/public',
// 要打包到的文件夹路径,跟随output配置中的目录。所以不需要再自己加__dirname。
to: './public'
}])
],
//配置webpack开发服务功能
devServer:{
// 设置基本目录结构
contentBase: path.resolve(__dirname, 'dist'),
// 服务器IP地址,可以使用IP或localhost
host: 'localhost',
// 服务器压缩是否开启
compress: true,
// 配置服务端口号
port: 1717
},
watchOptions: {
// 检测修改的时间,以ms为单位
poll: 1000,
// 防止重复保存而发生重复编译错误
aggregeateTimeout: 500,
// 不监听的目录
ignored: /node_modules/
}
}
ES6
阮一峰的ES6教程
JSPang的ES6教程
表严肃的视频教程(很简单的讲解一些知识,可用来入门学习)

个人建议先来看JSPang或者我表哥的教程,简单易懂,入门比较容易,待自己有了基础,再去看阮一峰或官方文档。
Proxy
概述
Proxy 用于修改某些操作的默认行为,等同于在语言层面做出修改,所以属于一种“元编程”(meta programming),即对编程语言进行编程。
Proxy 可以理解成,在目标对象之前架设一层“拦截”,外界对该对象的访问,都必须先通过这层拦截,因此提供了一种机制,可以对外界的访问进行过滤和改写。Proxy 这个词的原意是代理,用在这里表示由它来“代理”某些操作,可以译为“代理器”。
var obj = new Proxy({}, {
get: function (target, key, receiver) {
console.log(`getting ${key}!`);
return Reflect.get(target, key, receiver);
},
set: function (target, key, value, receiver) {
console.log(`setting ${key}!`);
return Reflect.set(target, key, value, receiver);
}
});
上面代码对一个空对象架设了一层拦截,重定义了属性的读取(get)和设置(set)行为。这里暂时先不解释具体的语法,只看运行结果。对设置了拦截行为的对象obj,去读写它的属性,就会得到下面的结果。
obj.count = 1
// setting count!
++obj.count
// getting count!
// setting count!
// 2
上面代码说明,Proxy 实际上重载(overload)了点运算符,即用自己的定义覆盖了语言的原始定义。
ES6 原生提供 Proxy 构造函数,用来生成 Proxy 实例。
var proxy = new Proxy(target, handler);
Proxy 对象的所有用法,都是上面这种形式,不同的只是handler参数的写法。其中,new Proxy()表示生成一个Proxy实例,target参数表示所要拦截的目标对象,handler参数也是一个对象,用来定制拦截行为。
下面是另一个拦截读取属性行为的例子。
var proxy = new Proxy({}, {
get: function(target, property) {
return 35;
}
});
proxy.time // 35
proxy.name // 35
proxy.title // 35
上面代码中,作为构造函数,Proxy接受两个参数。第一个参数是所要代理的目标对象(上例是一个空对象),即如果没有Proxy的介入,操作原来要访问的就是这个对象;第二个参数是一个配置对象,对于每一个被代理的操作,需要提供一个对应的处理函数,该函数将拦截对应的操作。比如,上面代码中,配置对象有一个get方法,用来拦截对目标对象属性的访问请求。get方法的两个参数分别是目标对象和所要访问的属性。可以看到,由于拦截函数总是返回35,所以访问任何属性都得到35。
注意,要使得Proxy起作用,必须针对Proxy实例(上例是proxy对象)进行操作,而不是针对目标对象(上例是空对象)进行操作。
如果handler没有设置任何拦截,那就等同于直接通向原对象。
var target = {};
var handler = {};
var proxy = new Proxy(target, handler);
proxy.a = 'b';
target.a // "b"
上面代码中,handler是一个空对象,没有任何拦截效果,访问proxy就等同于访问target。
一个技巧是将 Proxy 对象,设置到object.proxy属性,从而可以在object对象上调用。
var object = { proxy: new Proxy(target, handler) };
Proxy 实例也可以作为其他对象的原型对象。
var proxy = new Proxy({}, {
get: function(target, property) {
return 35;
}
});
let obj = Object.create(proxy);
obj.time // 35
上面代码中,proxy对象是obj对象的原型,obj对象本身并没有time属性,所以根据原型链,会在proxy对象上读取该属性,导致被拦截。
同一个拦截器函数,可以设置拦截多个操作。
var handler = {
get: function(target, name) {
if (name === 'prototype') {
return Object.prototype;
}
return 'Hello, ' + name;
},
apply: function(target, thisBinding, args) {
return args[0];
},
construct: function(target, args) {
return {value: args[1]};
}
};
var fproxy = new Proxy(function(x, y) {
return x + y;
}, handler);
fproxy(1, 2) // 1
new fproxy(1, 2) // {value: 2}
fproxy.prototype === Object.prototype // true
fproxy.foo === "Hello, foo" // true
对于可以设置、但没有设置拦截的操作,则直接落在目标对象上,按照原先的方式产生结果。
下面是 Proxy 支持的拦截操作一览,一共 13 种。
- get(target, propKey, receiver):拦截对象属性的读取,比如
proxy.foo和proxy['foo']。 - set(target, propKey, value, receiver):拦截对象属性的设置,比如
proxy.foo = v或proxy['foo'] = v,返回一个布尔值。 - has(target, propKey):拦截
propKey in proxy的操作,返回一个布尔值。 - deleteProperty(target, propKey):拦截
delete proxy[propKey]的操作,返回一个布尔值。 - ownKeys(target):拦截
Object.getOwnPropertyNames(proxy)、Object.getOwnPropertySymbols(proxy)、Object.keys(proxy),返回一个数组。该方法返回目标对象所有自身的属性的属性名,而Object.keys()的返回结果仅包括目标对象自身的可遍历属性。 - getOwnPropertyDescriptor(target, propKey):拦截
Object.getOwnPropertyDescriptor(proxy, propKey),返回属性的描述对象。 - defineProperty(target, propKey, propDesc):拦截
Object.defineProperty(proxy, propKey, propDesc)、Object.defineProperties(proxy, propDescs),返回一个布尔值。 - preventExtensions(target):拦截
Object.preventExtensions(proxy),返回一个布尔值。 - getPrototypeOf(target):拦截
Object.getPrototypeOf(proxy),返回一个对象。 - isExtensible(target):拦截
Object.isExtensible(proxy),返回一个布尔值。 - setPrototypeOf(target, proto):拦截
Object.setPrototypeOf(proxy, proto),返回一个布尔值。如果目标对象是函数,那么还有两种额外操作可以拦截。 - apply(target, object, args):拦截 Proxy 实例作为函数调用的操作,比如
proxy(...args)、proxy.call(object, ...args)、proxy.apply(...)。 - construct(target, args):拦截 Proxy 实例作为构造函数调用的操作,比如
new proxy(...args)。
实例:Web 服务的客户端
Proxy 对象可以拦截目标对象的任意属性,这使得它很合适用来写 Web 服务的客户端。
const service = createWebService('http://example.com/data');
service.employees().then(json => {
const employees = JSON.parse(json);
// ···
});
上面代码新建了一个 Web 服务的接口,这个接口返回各种数据。Proxy 可以拦截这个对象的任意属性,所以不用为每一种数据写一个适配方法,只要写一个 Proxy 拦截就可以了。
function createWebService(baseUrl) {
return new Proxy({}, {
get(target, propKey, receiver) {
return () => httpGet(baseUrl+'/' + propKey);
}
});
}
同理,Proxy 也可以用来实现数据库的 ORM 层。
Promise
含义
Promise 是异步编程的一种解决方案,比传统的解决方案——回调函数和事件——更合理和更强大。它由社区最早提出和实现,ES6 将其写进了语言标准,统一了用法,原生提供了Promise对象。
所谓Promise,简单说就是一个容器,里面保存着某个未来才会结束的事件(通常是一个异步操作)的结果。从语法上说,Promise 是一个对象,从它可以获取异步操作的消息。Promise 提供统一的 API,各种异步操作都可以用同样的方法进行处理。
Promise对象有以下两个特点。
(1)对象的状态不受外界影响。Promise对象代表一个异步操作,有三种状态:pending(进行中)、fulfilled(已成功)和rejected(已失败)。只有异步操作的结果,可以决定当前是哪一种状态,任何其他操作都无法改变这个状态。这也是Promise这个名字的由来,它的英语意思就是“承诺”,表示其他手段无法改变。
(2)一旦状态改变,就不会再变,任何时候都可以得到这个结果。Promise对象的状态改变,只有两种可能:从pending变为fulfilled和从pending变为rejected。只要这两种情况发生,状态就凝固了,不会再变了,会一直保持这个结果,这时就称为 resolved(已定型)。如果改变已经发生了,你再对Promise对象添加回调函数,也会立即得到这个结果。这与事件(Event)完全不同,事件的特点是,如果你错过了它,再去监听,是得不到结果的。
有了Promise对象,就可以将异步操作以同步操作的流程表达出来,避免了层层嵌套的回调函数。此外,Promise对象提供统一的接口,使得控制异步操作更加容易。
Promise也有一些缺点。首先,无法取消Promise,一旦新建它就会立即执行,无法中途取消。其次,如果不设置回调函数,Promise内部抛出的错误,不会反应到外部。第三,当处于pending状态时,无法得知目前进展到哪一个阶段(刚刚开始还是即将完成)。
如果某些事件不断地反复发生,一般来说,使用 Stream 模式是比部署Promise更好的选择。
基本使用
ES6 规定,Promise对象是一个构造函数,用来生成Promise实例。
下面代码创造了一个Promise实例。
const promise = new Promise(function(resolve, reject) {
// ... some code
if (/* 异步操作成功 */){
resolve(value);
} else {
reject(error);
}
});
Promise构造函数接受一个函数作为参数,该函数的两个参数分别是resolve和reject。它们是两个函数,由 JavaScript 引擎提供,不用自己部署。
resolve函数的作用是,将Promise对象的状态从“未完成”变为“成功”(即从 pending 变为 resolved),在异步操作成功时调用,并将异步操作的结果,作为参数传递出去;reject函数的作用是,将Promise对象的状态从“未完成”变为“失败”(即从 pending 变为 rejected),在异步操作失败时调用,并将异步操作报出的错误,作为参数传递出去。
Promise实例生成以后,可以用then方法分别指定resolved状态和rejected状态的回调函数。
promise.then(function(value) {
// success
}, function(error) {
// failure
});
then方法可以接受两个回调函数作为参数。第一个回调函数是Promise对象的状态变为resolved时调用,第二个回调函数是Promise对象的状态变为rejected时调用。其中,第二个函数是可选的,不一定要提供。这两个函数都接受Promise对象传出的值作为参数。
下面是一个Promise对象的简单例子。
function timeout(ms) {
return new Promise((resolve, reject) => {
setTimeout(resolve, ms, 'done');
});
}
timeout(100).then((value) => {
console.log(value);
});
上面代码中,timeout方法返回一个Promise实例,表示一段时间以后才会发生的结果。过了指定的时间(ms参数)以后,Promise实例的状态变为resolved,就会触发then方法绑定的回调函数。
Promise 新建后就会立即执行。
常用方法:
Promise.then() 为 Promise 实例添加状态改变时的回调函数。
getJSON("/posts.json").then(function(json) {
return json.post;
}).then(function(post) {
// ...
});
Promise.catch() 用于指定发生错误时的回调函数。
getJSON('/posts.json').then(function(posts) {
// ...
}).catch(function(error) {
// 处理 getJSON 和 前一个回调函数运行时发生的错误
console.log('发生错误!', error);
});
Promise.all() 用于将多个 Promise 实例,包装成一个新的 Promise 实例。
const p1 = new Promise((resolve, reject) => {
resolve('hello');
})
.then(result => result)
.catch(e => e);
const p2 = new Promise((resolve, reject) => {
throw new Error('报错了');
})
.then(result => result)
.catch(e => e);
Promise.all([p1, p2])
.then(result => console.log(result))
.catch(e => console.log(e));
// ["hello", Error: 报错了]
上面代码中,p1会resolved,p2首先会rejected,但是p2有自己的catch方法,该方法返回的是一个新的 Promise 实例,p2指向的实际上是这个实例。该实例执行完catch方法后,也会变成resolved,导致Promise.all()方法参数里面的两个实例都会resolved,因此会调用then方法指定的回调函数,而不会调用catch方法指定的回调函数。
如果p2没有自己的catch方法,就会调用Promise.all()的catch方法。
Promise.race()
const p = Promise.race([
fetch('/resource-that-may-take-a-while'),
new Promise(function (resolve, reject) {
setTimeout(() => reject(new Error('request timeout')), 5000)
})
]);
p.then(response => console.log(response));
p.catch(error => console.log(error));
上面代码中,如果 5 秒之内fetch方法无法返回结果,变量p的状态就会变为rejected,从而触发catch方法指定的回调函数。
Promise.resolve() 有时需要将现有对象转为 Promise 对象,Promise.resolve方法就起到这个作用。
Promise.resolve方法的参数分成四种情况。
(1)参数是一个 Promise 实例
如果参数是 Promise 实例,那么Promise.resolve将不做任何修改、原封不动地返回这个实例。
(2)参数是一个thenable对象
thenable对象指的是具有then方法的对象,比如下面这个对象。
let thenable = {
then: function(resolve, reject) {
resolve(42);
}
};
Promise.resolve方法会将这个对象转为 Promise 对象,然后就立即执行thenable对象的then方法。
let thenable = {
then: function(resolve, reject) {
resolve(42);
}
};
let p1 = Promise.resolve(thenable);
p1.then(function(value) {
console.log(value); // 42
});
上面代码中,thenable对象的then方法执行后,对象p1的状态就变为resolved,从而立即执行最后那个then方法指定的回调函数,输出 42。
(3)参数不是具有then方法的对象,或根本就不是对象
如果参数是一个原始值,或者是一个不具有then方法的对象,则Promise.resolve方法返回一个新的 Promise 对象,状态为resolved。
const p = Promise.resolve('Hello');
p.then(function (s){
console.log(s)
});
// Hello
上面代码生成一个新的 Promise 对象的实例p。由于字符串Hello不属于异步操作(判断方法是字符串对象不具有 then 方法),返回 Promise 实例的状态从一生成就是resolved,所以回调函数会立即执行。Promise.resolve方法的参数,会同时传给回调函数。
(4)不带有任何参数
Promise.resolve方法允许调用时不带参数,直接返回一个resolved状态的 Promise 对象。
所以,如果希望得到一个 Promise 对象,比较方便的方法就是直接调用Promise.resolve方法。
const p = Promise.resolve();
p.then(function () {
// ...
});
上面代码的变量p就是一个 Promise 对象。
需要注意的是,立即resolve的 Promise 对象,是在本轮“事件循环”(event loop)的结束时,而不是在下一轮“事件循环”的开始时。
setTimeout(function () {
console.log('three');
}, 0);
Promise.resolve().then(function () {
console.log('two');
});
console.log('one');
// one
// two
// three
上面代码中,setTimeout(fn, 0)在下一轮“事件循环”开始时执行,Promise.resolve()在本轮“事件循环”结束时执行,console.log('one')则是立即执行,因此最先输出。
Promise.reject() 会返回一个新的 Promise 实例,该实例的状态为rejected。
const thenable = {
then(resolve, reject) {
reject('出错了');
}
};
Promise.reject(thenable)
.catch(e => {
console.log(e === thenable)
})
// true
上面代码中,Promise.reject方法的参数是一个thenable对象,执行以后,后面catch方法的参数不是reject抛出的“出错了”这个字符串,而是thenable对象。
两个有用的附加方法
done()
Promise 对象的回调链,不管以then方法或catch方法结尾,要是最后一个方法抛出错误,都有可能无法捕捉到(因为 Promise 内部的错误不会冒泡到全局)。因此,我们可以提供一个done方法,总是处于回调链的尾端,保证抛出任何可能出现的错误。
asyncFunc()
.then(f1)
.catch(r1)
.then(f2)
.done();
它的实现代码相当简单。
Promise.prototype.done = function (onFulfilled, onRejected) {
this.then(onFulfilled, onRejected)
.catch(function (reason) {
// 抛出一个全局错误
setTimeout(() => { throw reason }, 0);
});
};
从上面代码可见,done方法的使用,可以像then方法那样用,提供fulfilled和rejected状态的回调函数,也可以不提供任何参数。但不管怎样,done都会捕捉到任何可能出现的错误,并向全局抛出。
finally()
finally方法用于指定不管 Promise 对象最后状态如何,都会执行的操作。它与done方法的最大区别,它接受一个普通的回调函数作为参数,该函数不管怎样都必须执行。
下面是一个例子,服务器使用 Promise 处理请求,然后使用finally方法关掉服务器。
server.listen(0)
.then(function () {
// run test
})
.finally(server.stop);
它的实现也很简单。
Promise.prototype.finally = function (callback) {
let P = this.constructor;
return this.then(
value => P.resolve(callback()).then(() => value),
reason => P.resolve(callback()).then(() => { throw reason })
);
};
上面代码中,不管前面的 Promise 是fulfilled还是rejected,都会执行回调函数callback。
Sass
sass的话,我没用过,但是我用过less和stylus,附上机票自己学习吧

React


PureComponen
PureComponent 是在 react v15.3.0 中新加的一个组件,从 React 源码中可以看到它是继承了 Component 组件:
/**
* Base class helpers for the updating state of a component.
*/
function ReactPureComponent(props, context, updater) {
// Duplicated from ReactComponent.
this.props = props;
this.context = context;
this.refs = emptyObject;
// We initialize the default updater but the real one gets injected by the
// renderer.
this.updater = updater || ReactNoopUpdateQueue;
}
function ComponentDummy() {}
ComponentDummy.prototype = ReactComponent.prototype;
var pureComponentPrototype = (ReactPureComponent.prototype = new ComponentDummy());
pureComponentPrototype.constructor = ReactPureComponent;
// Avoid an extra prototype jump for these methods.
Object.assign(pureComponentPrototype, ReactComponent.prototype);
pureComponentPrototype.isPureReactComponent = true;
同时在 shouldComponentUpdate 函数中有一段这样的逻辑:
if (type.prototype && type.prototype.isPureReactComponent) {
return (
!shallowEqual(oldProps, newProps) || !shallowEqual(oldState, newState)
);
}
PureReactComponent 组件和 ReactComponent 组件的区别就是它在 shouldComponentUpdate 中会默认判断新旧属性和状态是否相等,如果没有改变则返回 false,因此它得以减少组件的重渲染。
优点
- 在 shouldComponentUpdate 生命周期做了优化会自动 shadow diff 组件的 state 和 props,结合 immutable 数据就可以很好地去做更新判断;
- 隔离了父组件与子组件的状态变化;
缺点:
- shouldComponentUpdate 中的 shadow diff 同样消耗性能;
- 需要确保组件渲染仅取决于 props 与 state ;
Dumb components(木偶组件):
Dumb 组件又称为 木偶组件,它负责展示作用以及响应用户交互,它一般是无状态的(在如 Modal 等类组件中可能会维护少量自身状态);
一般而言 Dumb 组件会拆分为一个个可复用、功能单一的组件;
因此 Dumb 组件使用函数式组件定义,当其需要对重渲染进行优化时则可以使用 PureComponent。
-它必须能独立运作,不能依赖依赖这个app的actions 或者 stores 部分
- 可以允许有this.props.children,这样的话有助于这个组件有修改弹性
- 接受数据和数据的改变只能通过props來处理,不必也不能用state。
- 组件的外观能用一个css來维护(这样才更容易重用,类似支付宝的ant)
- 很少用到state,(一般呈现动画的时候可能会用到。。比如控制下拉框的展开或者收起)
- 也许会用到其他的dumb components
- 比如说: Page, Sidebar, Story, UserInfo, List,像这些都是dumb components.
smart components(智能组件):
Smart 组件又称为 容器组件,它负责处理应用的数据以及业务逻辑,同时将状态数据与操作函数作为属性传递给子组件;
一般而言它仅维护很少的 DOM,其所有的 DOM 也仅是作为布局等作用。
- 一定包含至少一个Smart 或者 Dumb的元件,(这肯定啊。。不然他干的啥)
- 负责把从flux(or redux等)接收到的state传给dumb component
- 负责call action,并把它的callback传給dumb component
- 它应该只有结构没有外观(这样的话。。改个样式只需要改dumb 组件 就好了。。他写着。。他写那里 不然很累啊)
- 比如说: UserPage, FollowersSidebar, StoryContainer,
FollowedUserList.
这样做的好处
- 有助理你分离关注点,这样的话更有助于理解你的app的业务逻辑 和 它的ui
- 更有助于复用你的dumb组件,你可以将你的dumb组件复用于别的state下,而且这两个state还完全不同
- 本质上dumb 组件 其实 就是你的app的调色版。。你可以将它们放到一个页面上。。然后让设计师除了app的业务逻辑,样式随便怎么改,
所以 Smart 组件更多关注与数据以及业务逻辑,而 Dumb 组件与数据和业务解耦,主要复杂 UI 层面的展示与交互。
正在学习ing,求带
以上就是我对在项目中大概看到的东西的总结