文章参照 从零开始学python网络爬虫 所写,本人也是刚刚接触爬虫
网络连接
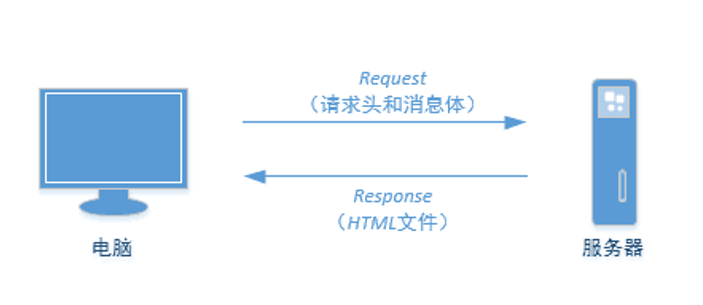
网络连接像是在自助饮料售货机上购买饮料一样:购买者只需选择所需饮料,投入硬币,自助饮料售货机就会弹出相应的商品。网络连接也正是如此,如下图所示,本机电脑(购买者)带着请求头和消息体(硬币和所需饮料)向服务器(自助饮料售货机)发起一次Requests请求(购买),相应的服务器(自助饮料售货机)会返回本机电脑相应的HTML文件作为Response(相应的商品)。
网络连接原理图
爬虫原理
网络连接需要电脑的一次Requests请求和服务器端的Response回响,爬虫需要做的也是两件事:
(1)模拟电脑对服务器发起Requests请求。
(1)接收服务器端的Response的内容并解析提取响应中自己所需要的信息
但是网上的网页错综复杂,一次的请求和回应不能够批量获取网页的数据,这时需要设计爬虫的流程,这里主要介绍两种爬虫所需的流程:多页面和跨页面爬虫流程。(如下图)
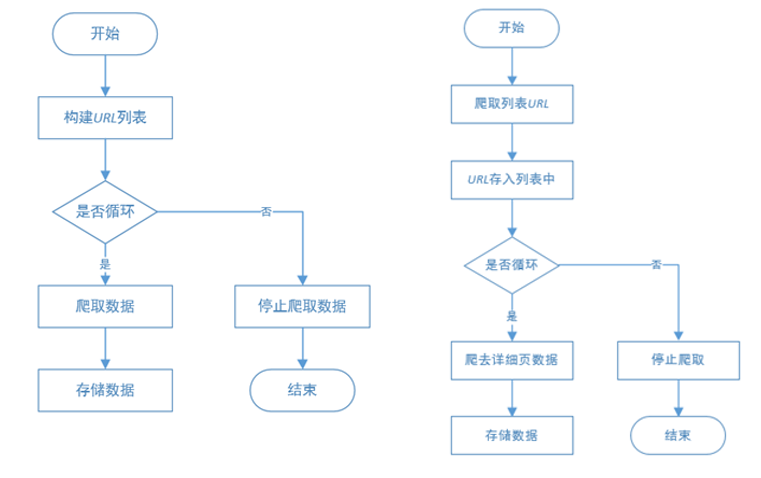
多页面网页爬虫流程 跨页面网页爬虫流程