1.修改网络文件deploy.prototxt
(以一个简单地卷积网络结构为例,主要修改input层和输出softmax层)
layer {#修改这里1
name: "data"
type: "Input"
top: "data"
input_param { shape: { dim: 1 dim: 3 dim: 224 dim: 224 } }
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
convolution_param {
num_output: 20
kernel_size: 5
weight_filler {
type: "xavier"
}
}
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv2"
type: "Convolution"
bottom: "pool1"
top: "conv2"
convolution_param {
num_output: 50
kernel_size: 5
weight_filler {
type: "xavier"
}
}
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "fc1"
type: "InnerProduct"
bottom: "pool2"
top: "fc1"
inner_product_param {
num_output: 500
weight_filler {
type: "xavier"
}
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "fc1"
top: "fc1"
}
layer {
name: "score"
type: "InnerProduct"
bottom: "fc1"
top: "score"
inner_product_param {
num_output: 10
weight_filler {
type: "xavier"
}
}
}
#修改这里2
layer {
name: "prob"
type: "Softmax"
bottom: "score"
top: "prob"
}2.加载训练好的caffemodel模型预测
(预测代码如下:)
# -*- coding: UTF-8 -*-
import caffe
import numpy as np
def test(my_project_root, deploy_proto):
caffe_model = my_project_root + 'mnist_iter_9380.caffemodel' #caffe_model文件的位置
img = my_project_root + 'mnist/test/6/09269.png' #随机找的一张待测图片
labels_filename = my_project_root + 'mnist/test/labels.txt' #类别名称文件,将数字标签转换回类别名称
net = caffe.Net(deploy_proto, caffe_model, caffe.TEST) #加载model和deploy
#图片预处理设置
transformer = caffe.io.Transformer({'data': net.blobs['data'].data.shape}) #设定图片的shape格式(1,3,28,28)
transformer.set_transpose('data', (2,0,1)) #改变维度的顺序,由原始图片(28,28,3)变为(3,28,28)
transformer.set_raw_scale('data', 255) # 缩放到【0,255】之间
transformer.set_channel_swap('data', (2,1,0)) #交换通道,将图片由RGB变为BGR
im = caffe.io.load_image(img) #加载图片
net.blobs['data'].data[...] = transformer.preprocess('data',im) #执行上面设置的图片预处理操作,并将图片载入到blob中
out = net.forward() #执行测试
labels = np.loadtxt(labels_filename, str, delimiter='\t') #读取类别名称文件
prob = net.blobs['prob'].data[0].flatten() #取出最后一层(Softmax)属于某个类别的概率值
order = prob.argsort()[-1] #将概率值排序,取出最大值所在的序号
print '图片数字为:',labels[order] #将该序号转换成对应的类别名称,并打印
if __name__ == '__main__':
my_project_root = "/home/Jack-Cui/caffe-master/my-caffe-project/" #my-caffe-project目录
deploy_proto = my_project_root + "mnist/deploy.prototxt" #保存deploy.prototxt文件的位置
test(my_project_root, deploy_proto)可得运行结果如下:(贴的别人的,我没有保存这步的图)
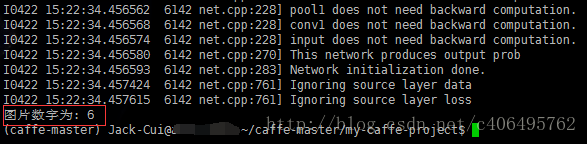
注意注意:做到这一步不知道大家有没有得到满意预测结果反正我没有,下面分点阐述我的修改:
先贴我的修改后代码:
import os
import sys
import numpy as np
import matplotlib.pyplot as plt
import struct
caffe_root = '/home/hsm/project/facialexpress/caffe/'
sys.path.insert(0, caffe_root + 'python')
import caffe
MODEL_FILE = '/your_prototxt_path/sedstage_deploy.prototxt' #网络文件路径
PRETRAINED = '/your_caffemodel_path/secdstage_train4_iter_10000.caffemodel'
ROOT_PATH = '/your_image_path/su/' #图片存放路径(1)
mean_file = '/your_mean_file_path/mmi_train4_mean.npy'#均值文件路径(2)
labels_filename = '/your_classfile_path/mmi_class.txt'#类名文件,按行写你的类别就行
net = caffe.Net(MODEL_FILE, PRETRAINED, caffe.TEST)
sum = np.zeros(6)
with open("/home/hsm/project/facialexpress/input/MMI/10_folds/valid4_labels.txt","a") as f:#将预测值和标签写入文件,自己后续画图需要
for root, dir, names in os.walk(ROOT_PATH):
for name in names:
# print(os.path.join(root, name))
transformer = caffe.io.Transformer({'data': net.blobs['data'].data.shape})
transformer.set_transpose('data', (2,0,1))
transformer.set_mean('data', np.load(mean_file))(2)
transformer.set_raw_scale('data', 255)
transformer.set_channel_swap('data', (2,1,0))
input_image = caffe.io.load_image(os.path.join(root, name))
net.blobs['data'].data[...] = transformer.preprocess('data',input_image)
out = net.forward()
labels = np.loadtxt(labels_filename, str, delimiter='\t')
prob = net.blobs['prob'].data[0].flatten()
print(prob)
order = prob.argsort()[-1]
print labels[order]
sum[order] = sum[order] + 1
f.write(labels[order] + ' ' + 'Su\n')
print sum[0:6]
结果图:
(1)实现多图预测:
对应代码中的(1),加循环,遍历图片路径中的图片
(2)我要解决的主要问题:均值问题(训练时验证精度高,同样的验证集放在这里测试精度明显不准确,所有图片都分为某几类)
首先这里是否需要减均值,要和训练过程保持一致,训练减就减,否则就不减;
我的实验训练阶段是3通道图片减均值,所以不减均值就会精度不准确;
增加下面俩句均值操作:
mean_file = '/your_mean_file_path/mmi_train4_mean.npy'#均值文件路径(2.1)
transformer.set_mean('data', np.load(mean_file))(2.2) #逐通道减均值注意(2.1)这里的mean文件格式为:numpy格式,转换操作详见链接:
https://blog.csdn.net/hyman_yx/article/details/51732656
生成结果:

注意(2.2)加载mean文件是会报错:Mean shape incompatible with input shape
解决:修改caffe/python/caffe/io.py代码253-254行如下:
if ms != self.inputs[in_][1:]:
print(self.inputs[in_])
in_shape = self.inputs[in_][1:]
m_min, m_max = mean.min(), mean.max()
normal_mean = (mean - m_min) / (m_max - m_min)
mean = resize_image(normal_mean.transpose((1,2,0)),in_shape[1:]).transpose((2,0,1)) * (m_max - m_min) + m_min
#raise ValueError('Mean shape incompatible with input shape.')另外:单通道图的减均值操作,将(2.2)改为:(无需修改caffe/python/caffe/io.py文件)
transformer.set_mean('data', np.load(mean_file).mean(1).mean(1)) #只减去一个值参考链接:https://www.cnblogs.com/denny402/p/5111018.html
附上我的类文件class.txt
