此处更新实现的内容有:
1、使用struts2实现全局登录拦截器验证
2、对用户个人信息的管理平台进行了管理实现
(1)用户可以查看自己上传至平台的书籍内容、并进行删除、修改
(2)用户可以查看自己的个人下载记录、历史
(3)用户可以进行新书籍的上传与发布
(4)用户可以对自己的账户个人信息进行设置
【以上对书籍进行操作的功能均需要管理员进行验证】
3、具体页面:
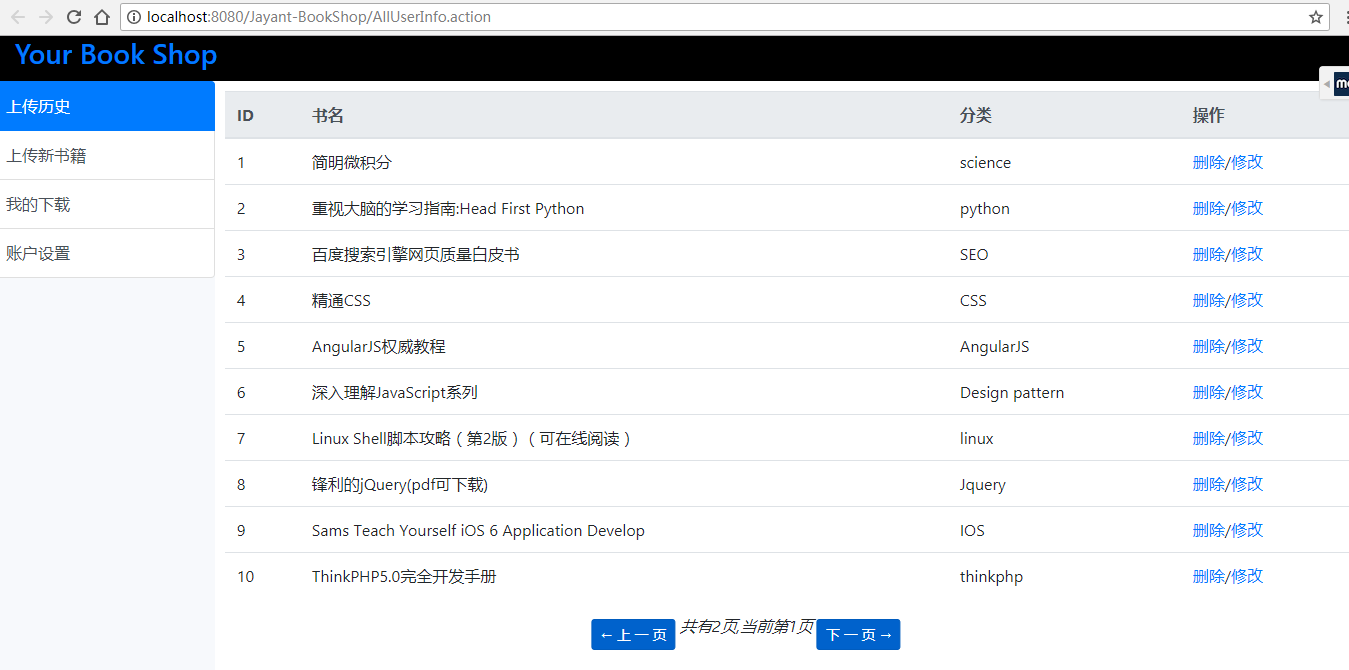
(1)查看个人上传记录、并提供删除,修改功能
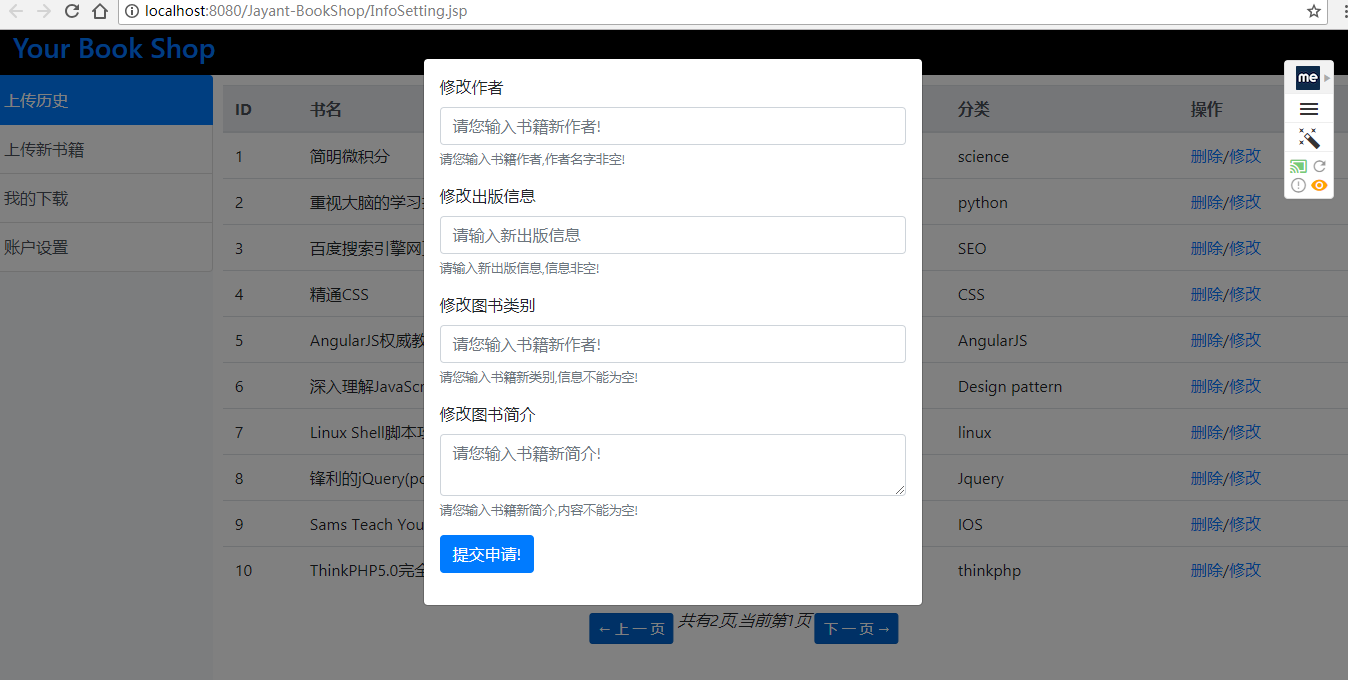
(1-1)点击修改书籍时,可对书籍具体内容进行修改
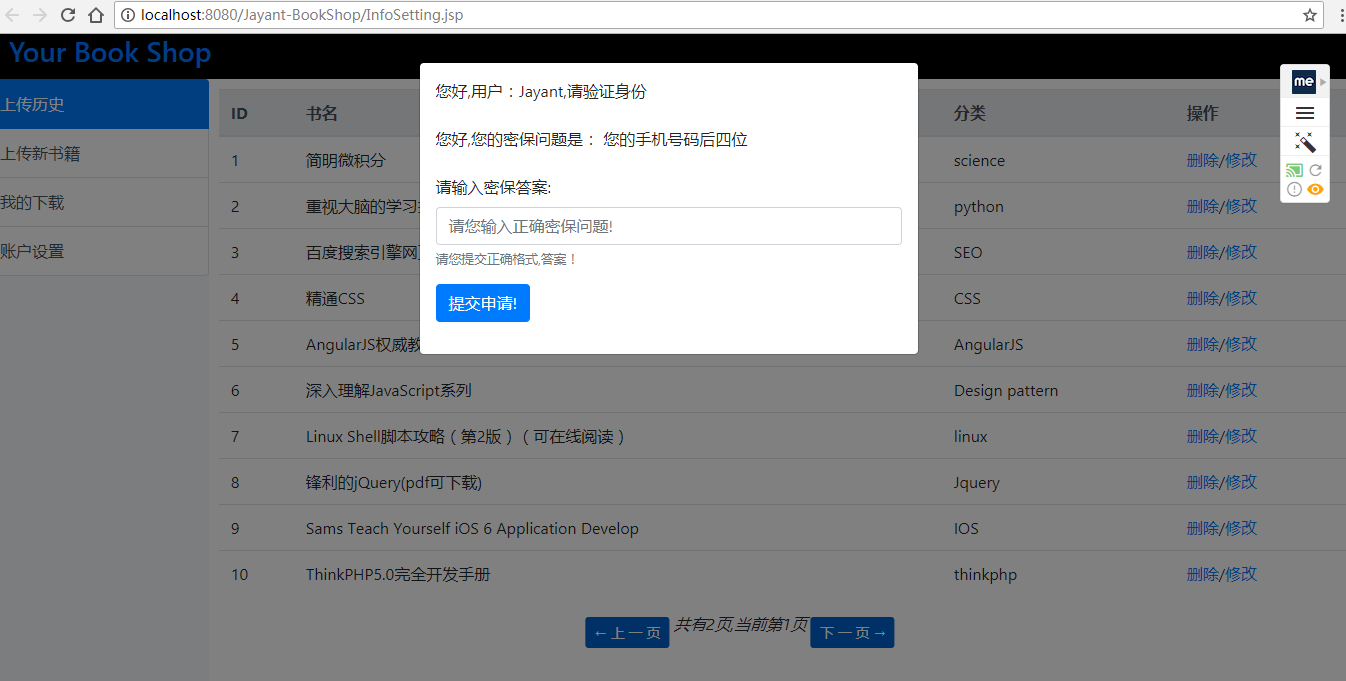
(1-2)点击删除书籍时,需要验证个人信息:密保,才可提交删除请求
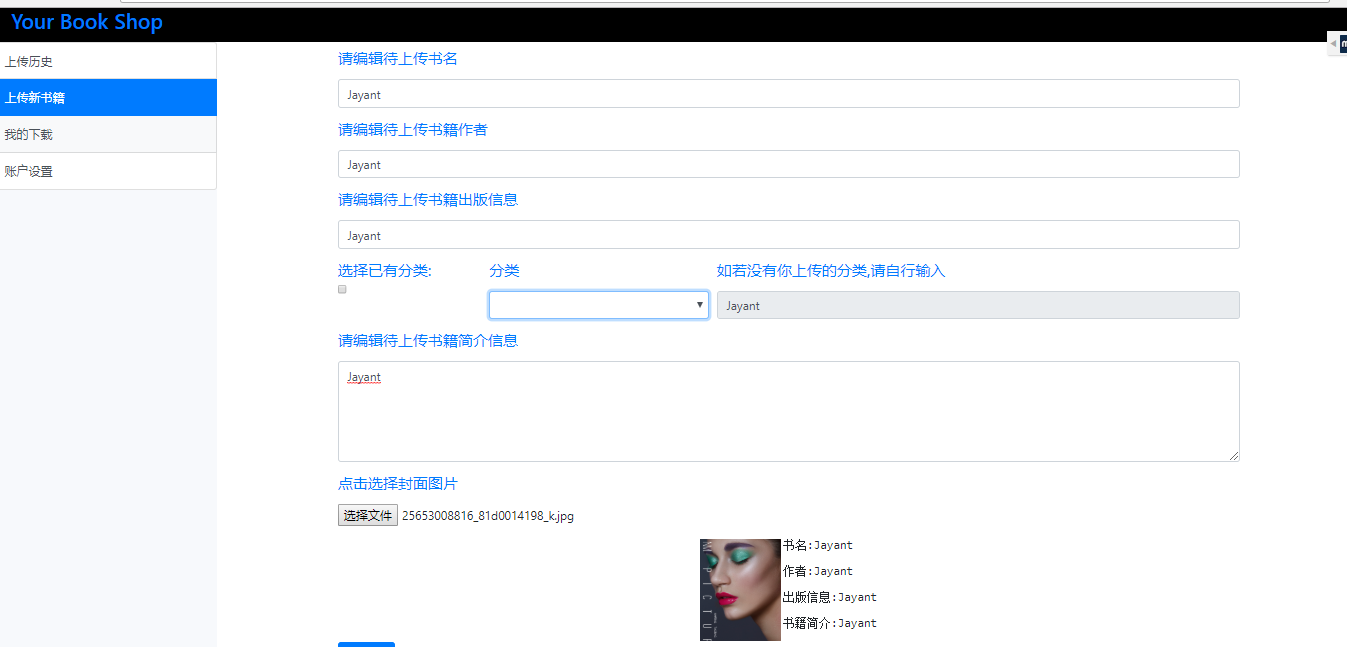
(2-1)上传新书籍
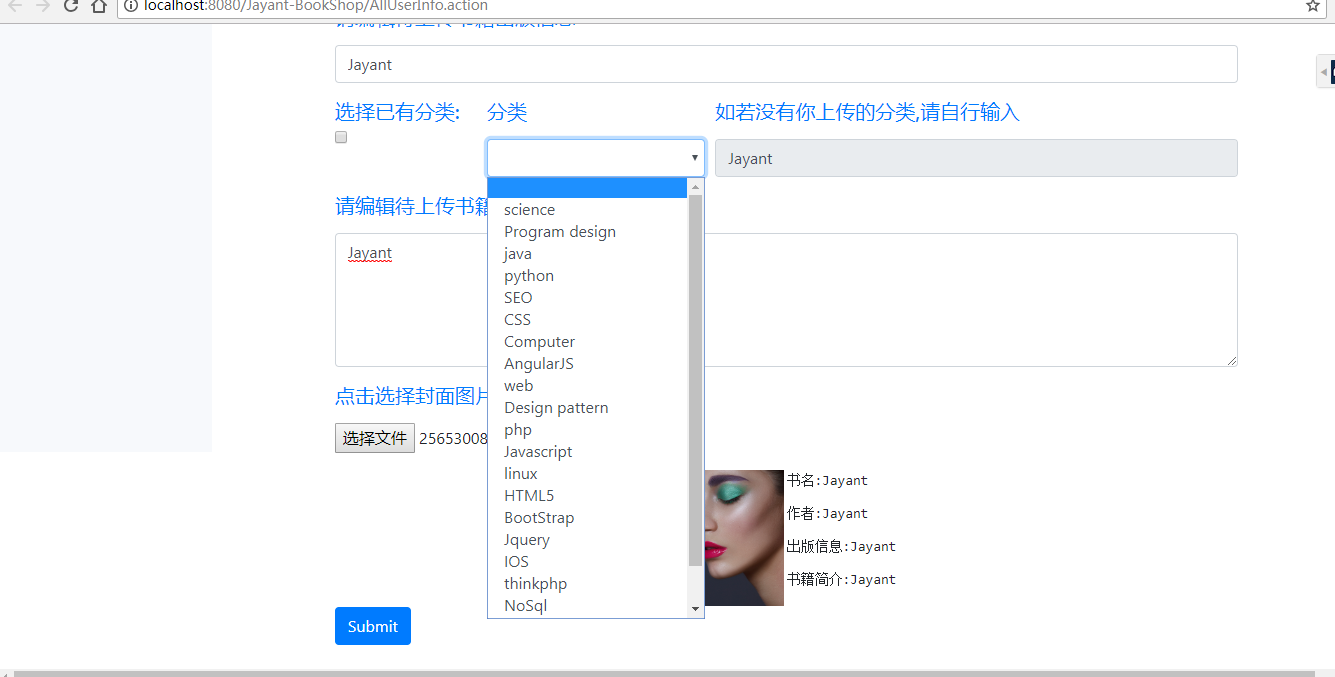
(2-2)上传书籍,获取分类的实现以及预览所选照片的实现
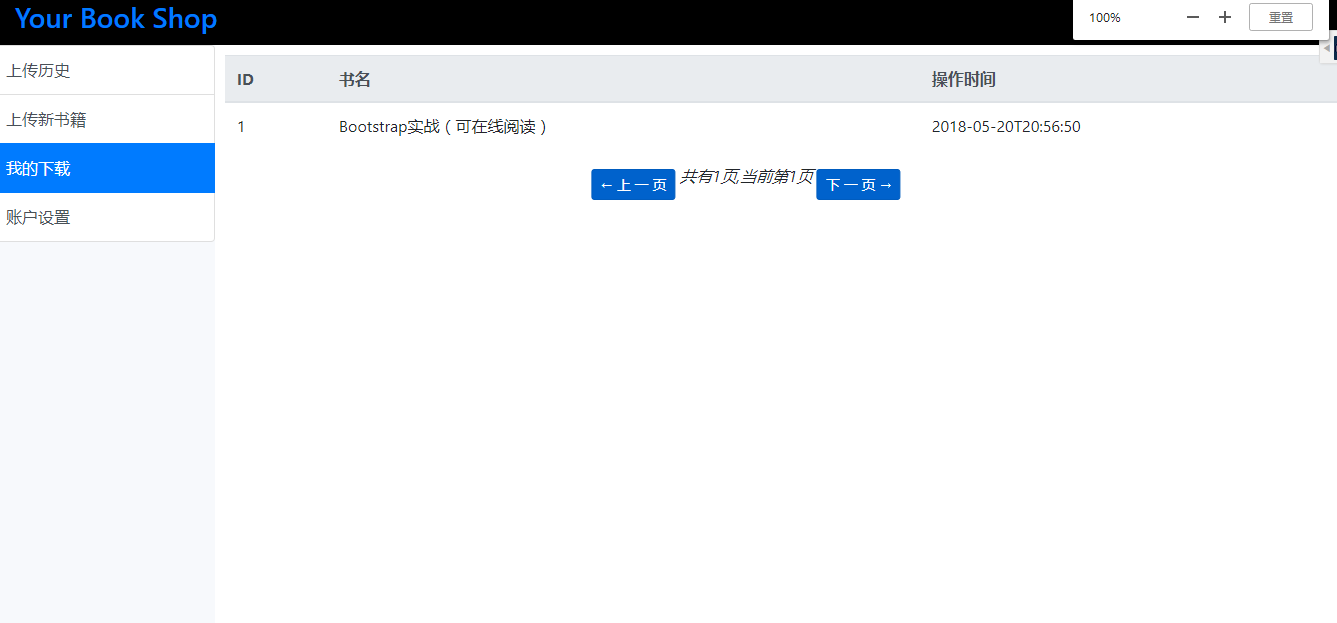
(3)查看用户个人下载记录
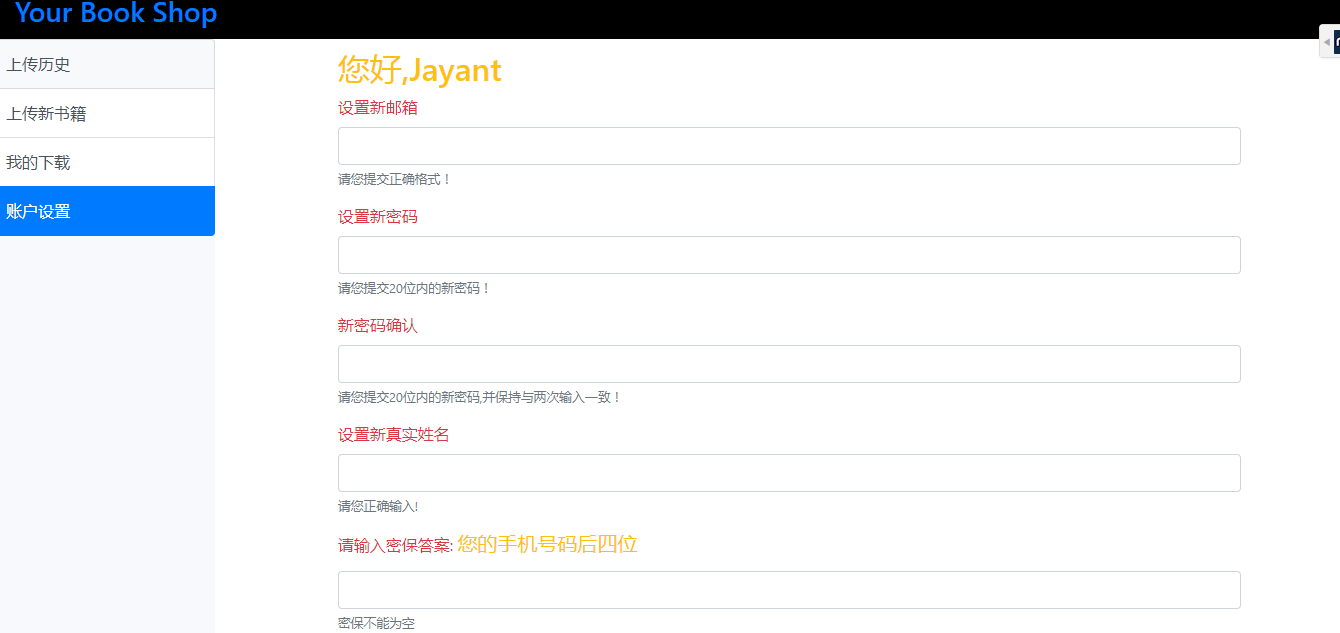
(4)账户设置
Ok!
以上就是实现了的具体功能,因为功能不外乎就那么操作,接下来介绍一下,在实现过程中遇到的问题,以及解决思路
一、Bootstrape4提供了tab-pane可以用于帮助实现左右结构的布局以及管理
二、Angular.js的$http与后台数据交互的时候,关于数据格式的问题,与ajax不同,我们需要对数据进行“改造”
headers: { 'Content-Type': 'application/x-www-form-urlencoded' },
transformRequest: function (dataName) {
return $.param(dataName);
}三、上传信息,数据的字符串清洗,用于避免以及初步筛选出不需要或者指定的格式
四、上传新书籍部分;采用了ajaxfileupload.js模块进行上传,具体可以百度实现方式;或者formdata的形式也是可行的
五、在页面显示所选择的图片:
eleFile.addEventListener('change', function() {
var file = this.files[0];
// 确认选择的文件是图片
if(file.type.indexOf("image") == 0) {
var reader = new FileReader();
reader.readAsDataURL(file);
reader.onload = function(e) {
// 图片base64化
var newUrl = this.result;
preview.style.backgroundImage = 'url(' + newUrl + ')';
};
}
});具体实现是依靠:filereader()方法进行操作
FileReader提供了如下方法:
| readAsArrayBuffer(file) | 按字节读取文件内容,结果用ArrayBuffer对象表示 |
| readAsBinaryString(file) | 按字节读取文件内容,结果为文件的二进制串 |
| readAsDataURL(file) | 读取文件内容,结果用data:url的字符串形式表示 |
| readAsText(file,encoding) | 按字符读取文件内容,结果用字符串形式表示 |
| abort() | 终止文件读取操作 |
------JAVA部分------
一、实现后台传回对象组,我们可以将查询结果装载入相应的对象List中,返回前台后,使用Angular.js提供的ng-repeat对二位数组进行扫描与提取
二、文件的写入/上传/保存:
//传入的图片文件
private File file; //文件
public File getFile() {
return file;
}
public void setFile(File file) {
this.file = file;
}
private String fileFileName; //文件名
public String getFileFileName() {
return fileFileName;
}
public void setFileFileName(String fileFileName) {
this.fileFileName = fileFileName;
}
private String filePath; //文件路径
public String getFilePath() {
return filePath;
}
public void setFilePath(String filePath) {
this.filePath = filePath;
}
public String UpBook(){
System.out.println(newuobookowner);
String path = "F:\\Myeclipse2017-10\\Jayant-BookShop\\WebRoot\\Pic\\BookPicUrl";
//System.out.println(path);
File file = new File(path); // 判断文件夹是否存在,如果不存在则创建文件夹
if (!file.exists()) {
file.mkdir();
}
try {
if (this.file != null) {
//**
File f = this.getFile();
// 保存在硬盘中的文件名
String name = newupbookname+ fileFileName.substring(fileFileName.lastIndexOf("."));
PicUrl = name;
//System.out.println(name);
FileInputStream inputStream = new FileInputStream(f);
FileOutputStream outputStream = new FileOutputStream(path+ "\\" + name);
//分配1024个字节内存给buf
byte[] buf = new byte[1024];
int length = 0;
while ((length = inputStream.read(buf)) != -1) {
outputStream.write(buf, 0, length);
}
inputStream.close();
outputStream.flush();
//文件保存的完整路径 比如:D:\tomcat6\webapps\eserver\\upload\a0be14a1-f99e-4239-b54c-b37c3083134a.png
filePath = path+"\\"+name;
//System.out.println(filePath);
//**
return "success";
}
} catch (Exception e) {
e.printStackTrace();
}
return "error";
}-***************************-
结束,其他的可以操作【1】博文中提供的项目地址,下载后,进行了解
---------
问题:
在项目中,我遇到一个问题是:
HQL语句查询时,如果提供中文条件无法查询出结果:
1、事实打印出HQL语句后,并没有错误,并且将语句提供至数据库进行查询,可以得到正确结果********也就是语句本身没有错误
2、编码,按照网上搜索到的解决方案,修改了编码形式,指定一致的数据库编码以及代码文件编码等,依然无法准确查询出搜索答案
【所以在此请问是否有小伙伴有遇到过类似的问题,以及最终的解决方案是什么,可能问题描述有些含糊,希望有相似经历的朋友们可以提供一下帮助,谢谢】