一、前言
冒泡排序是一种交换排序。
什么是交换排序呢?答曰:交换排序即两两比较待排序的关键字,并交换不满足次序要求的那对数,直到整个表都满足次序要求为止。
二、算法思想
它重复地走访要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。
这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端,故名冒泡排序
三、代码
# -*- coding: utf-8 -*-
"""
Created on Sat Mar 24 09:56:56 2018
@author: su
"""
def bubblesort(input_list):
if(len(input_list)==0):
return []
sort_list=input_list
for i in range(len(sort_list)-1):
print("第{}次排序".format(i+1))
for j in range(len(sort_list)-1):
if(sort_list[j+1]<sort_list[j]):
sort_list[j+1],sort_list[j]=sort_list[j],sort_list[j+1]
print(sort_list)
return sort_list
if __name__=='__main__':
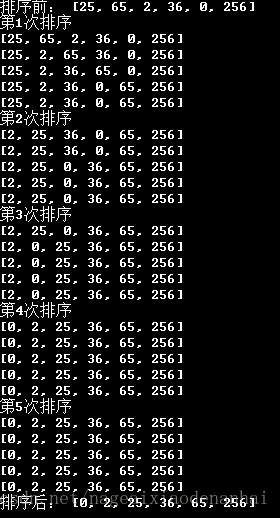
input_list=[25,65,2,36,0,256]
print('排序前:',input_list)
sort_list=bubblesort(input_list)
print('排序后:',sort_list)
运行结果:
四、算法分析
1.冒泡排序算法的性能

2.时间复杂度
若文件的初始状态是正序的,一趟扫描即可完成排序。所需的关键字比较次数C和记录移动次数M均达到最小值:Cmin = N - 1, Mmin = 0。所以,冒泡排序最好时间复杂度为O(N)。
但是上述代码,不能扫描一趟就完成排序,它会进行全扫描。所以一个改进的方法就是,当冒泡中途发现已经为正序了,便无需继续比对下去。改进方法一会儿介绍。
若初始文件是反序的,需要进行 N -1 趟排序。每趟排序要进行 N - i 次关键字的比较(1 ≤ i ≤ N - 1),且每次比较都必须移动记录三次来达到交换记录位置。在这种情况下,比较和移动次数均达到最大值:
Cmax = N(N-1)/2 = O(N^2)
Mmax = 3N(N-1)/2 = O(N^2)
冒泡排序的最坏时间复杂度为O(N^2)。
因此,冒泡排序的平均时间复杂度为O(N^2)。
总结起来,其实就是一句话:当数据越接近正序时,冒泡排序性能越好。
3.算法稳定性
冒泡排序就是把小的元素往前调或者把大的元素往后调。比较是相邻的两个元素比较,交换也发生在这两个元素之间。
所以相同元素的前后顺序并没有改变,所以冒泡排序是一种稳定排序算法。
五、优化
对冒泡排序常见的改进方法是加入标志性变量exchange,用于标志某一趟排序过程中是否有数据交换。
如果进行某一趟排序时并没有进行数据交换,则说明所有数据已经有序,可立即结束排序,避免不必要的比较过程。
代码:
# -*- coding: utf-8 -*-
"""
Created on Sat Mar 24 10:51:32 2018
@author: su
"""
def bubblesort(input_list):
if(len(input_list)==0):
return []
sort_list=input_list
for i in range(len(sort_list)-1):
bChange=False
print("第{}次排序".format(i+1))
for j in range(len(sort_list)-1):
if(sort_list[j+1]<sort_list[j]):
sort_list[j+1],sort_list[j]=sort_list[j],sort_list[j+1]
bChange=True
print(sort_list)
if not bChange:
break
return sort_list
if __name__=='__main__':
input_list=[0,65,2,36,25,256]
print('排序前:',input_list)
sort_list=bubblesort(input_list)
print('排序后:',sort_list)运行结果:
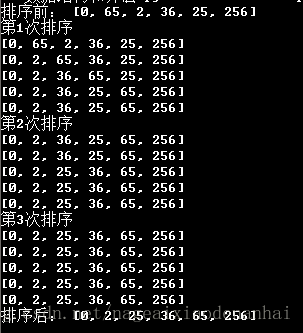
由运行结果可见,第三次排序已无数据交换,所以就结束排序。
参考:http://cuijiahua.com/blog/2017/12/algorithm_1.html