Lecture 10:Logistic Regression
Logistic Regression Problem
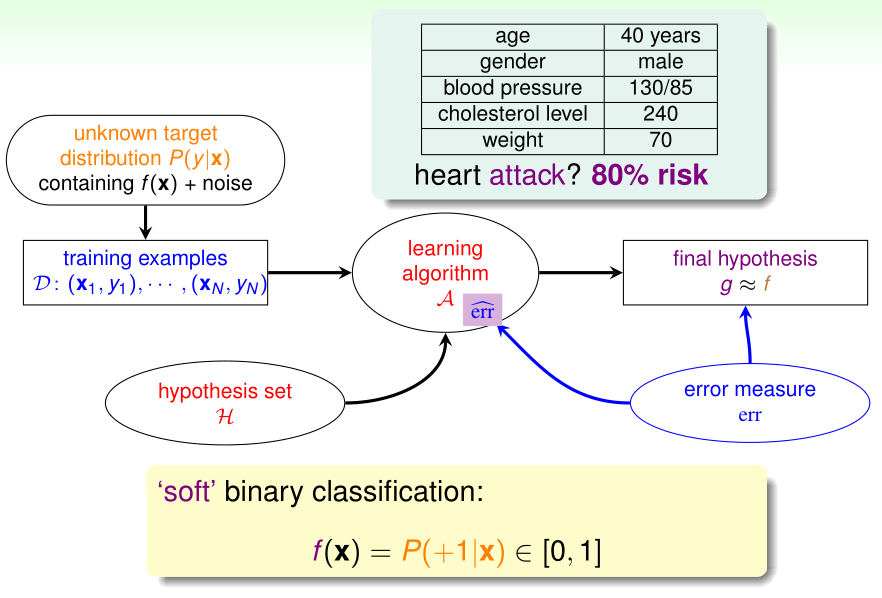
在之前使用PLA/口袋算法实现线性二分类时,我们理想的目标函数\(f(x)\)的输出\(\in\{1,-1\}\)
而逻辑回归理想的目标函数\(f(x)=P(y=1|x)\)(给定x时其标签y=1的概率),\(f(x)\in\{1,-1\}\)

在逻辑回归中,理想中没有噪声的训练样本的\(y^{(i)}\)应该是\(P(y=1|x^{(i)})\),但实际上给出的有噪声的训练样本的\(y^{(i)}\)则是服从概率分布\(P(y|x^{(i)})\)的随机变量的观测值
设输入特征为\(x=(x_0,\cdots,x_d)^T,x_0=1\),逻辑回归的假设函数为\(h(x)=\theta(w^Tx),\theta(x)\)是sigmoid函数
Logistic Regression Error
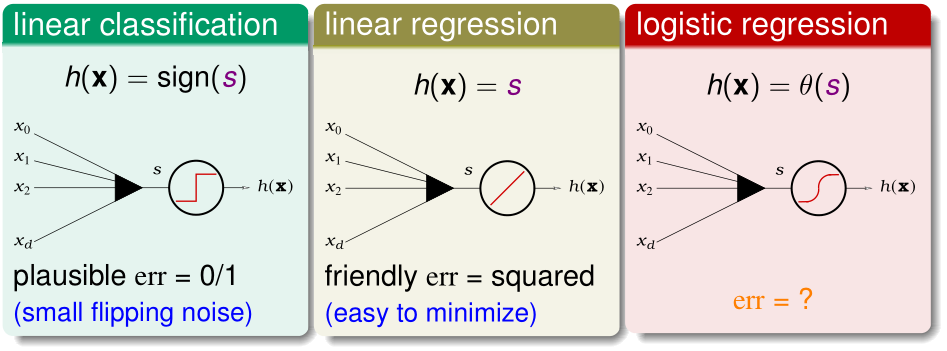
PLA/口袋算法、线性回归、逻辑回归的假设函数都可以视为输入特征的加权之和\(w^Tx\),经激励函数h(x)处理后得到的结果。
- PLA/口袋算法的h(x)就是sign(x),误差函数err为0/1误差;
- 线性回归的h(x)就是y=x,误差函数err为平方误差;
- 逻辑回归的h(x)就是sigmoid(x),下面用极大似然估计的方法得到它的误差函数
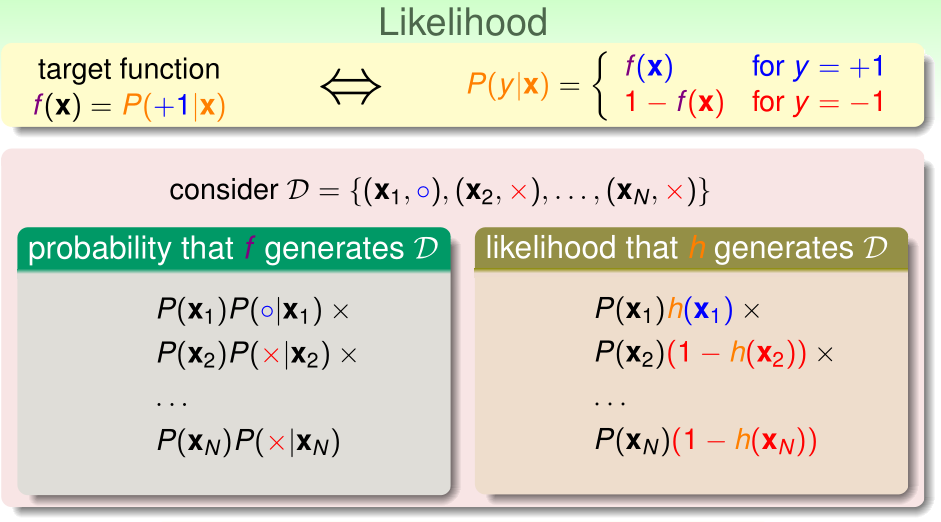
首先介绍似然性(likelihood)。对于目标函数\(f(x)=P(y=1|x)\),给出\(x^{(1)},\cdots,x^{(n)}\),通过这个目标函数随机得到\(y^{(1)},\cdots,y^{(n)}\)的概率为
\[\prod_{i=1}^n P(x^{(i)})P(y=y^{(i)}|x^{(i)})\]
似然性直白地讲,就是用我们的假设函数h(x)代替理想的目标函数f(x),产生\(y^{(1)},\cdots,y^{(n)}\)的概率
学习算法找到的假设函数h越接近理想的f(x),似然性就越大。所以学习算法的优化目标就是最大化似然函数
逻辑回归的假设函数\(h(x)=\theta(w^Tx)\),\(1-h(x)=h(-x)\),这个式子之后会大大方便简化表达式
对于假设函数h而言,其似然函数:
\[\mathcal L(h)=\prod _{i=1}^n P(x^{(i)})h(y^{(i)}x^{(i)})\]
\[\arg \max_{h} \prod _{i=1}^n P(x^{(i)})h(y^{(i)}x^{(i)})=\arg \max_{h}\prod _{i=1}^n h(y^{(i)}x^{(i)})\]
而\(\arg \max_{h}\prod _{i=1}^n h(y^{(i)}x^{(i)})\)就是要找到\(\arg \max_{w}\prod _{i=1}^n \theta(y^{(i)}w^Tx^{(i)})\),对该优化目标取对数
\[\arg \max_{w}\prod _{i=1}^n \theta(y^{(i)}w^Tx^{(i)})=\arg \max_{w}\sum _{i=1}^n \ln \theta(y^{(i)}w^Tx^{(i)})\]
\[=\arg \min_{w}\frac 1 n \sum _{i=1}^n -\ln \theta(y^{(i)}w^Tx^{(i)})\]
\[=\arg \min_{w}\frac 1 n \sum _{i=1}^n \ln (1+\exp(-y^{(i)}w^Tx^{(i)}))\]
err(w,x,y)=\(\ln (1+\exp(-y^{(i)}w^Tx^{(i)}))\),这被称为交叉熵误差
Gradient of Logistic Regression Error
根据之前使用极大似然估计的推导,
\[E_{in}(w)=\frac 1 n \sum _{i=1}^n \ln (1+\exp(-y^{(i)}w^Tx^{(i)}))\]
\(E_{in}(w)\)是连续、二阶可微的凸函数,我们令\(\nabla E_{in}(w)=0\)即可得到最优的参数\(w\)

Gradient Descent
直接令\(\nabla E_{in}(w)=0\)是得不到解析解的,我们只能考虑使用迭代的方式最优化这个参数w
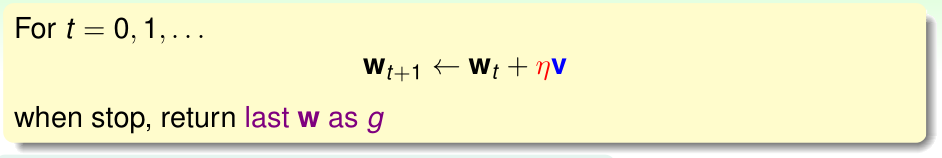
这里的向量v是单位方向向量,\(\eta\)是学习率(步长),我们知道,沿着与梯度相反的方向走,下降速度是最快的。所以这里v取与梯度相反方向的方向向量:

将这个v代入上式: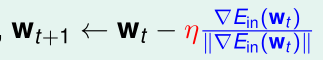
此时每次下降的步长都是相同的(步长为\(\eta\)),而我们希望随着越接近"谷底",步长越小,令\(\eta'=\frac \eta {\|\nabla E_{in}(w_t)\|}\),则:
\[w_{t+1}\gets w_t -\eta '\nabla E_{in}(w_t)\]
\(\eta'\)不变,则越是接近谷底,\(\|\nabla E_{in}(w_t)\|\)越小,步长也就越小