首先给出自己实践后的结果:
_CSVRead:是依靠线程实现参数化,每个线程使用不同的参数;
CSV Data Set Config:是依靠循环次数实现参数化,每次使用不同的参数。
为了对比,创建两个相同的HTTP请求
A.使用函数助手配置如下(后面简称A):


B.使用CSV Data Set Config(后面简称B):
添加配置原件:

设置参数;

3.两个请求使用同一个的CSV文件:
csv表格内容(不需要列名):

4.配置线程数为5,循环次数为1,查看不同结果:

A的结果:

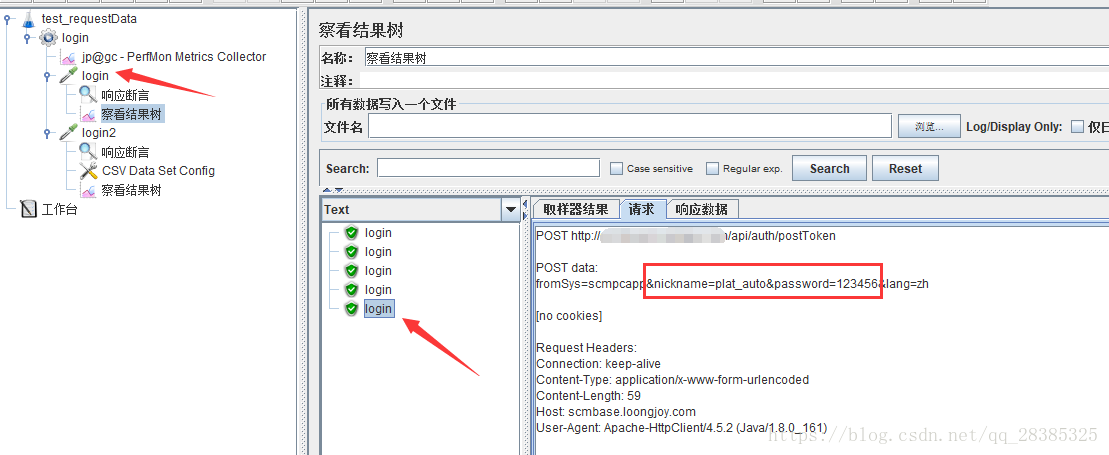
两个结果的请求数据不同,有正常循环
B的结果:
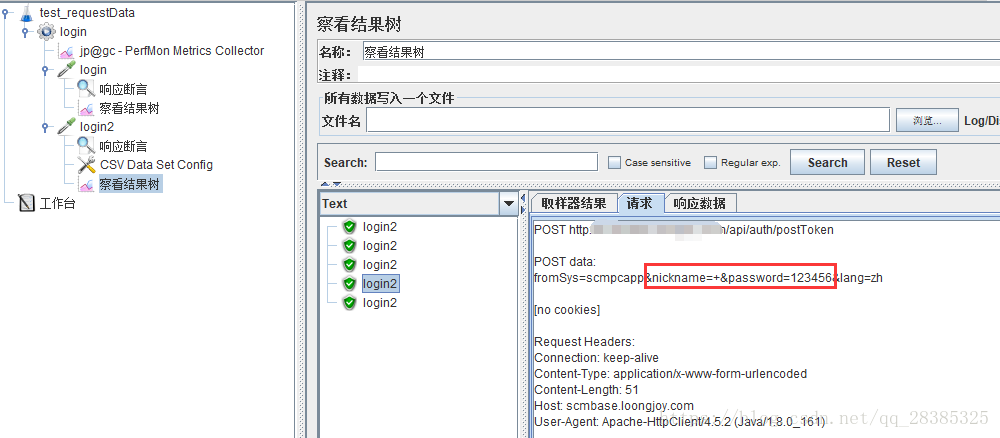

每次循环的相同数据
5.配置线程数为1,循环次数为5:
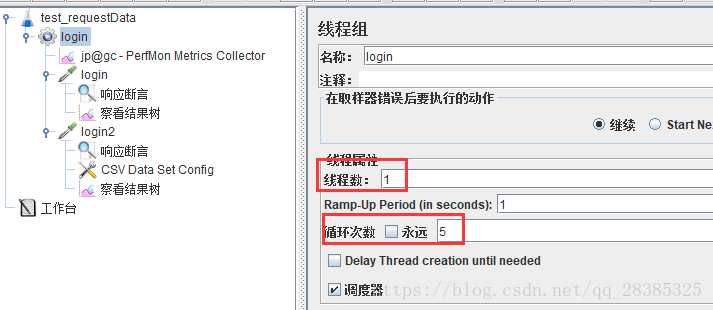
A的结果:


发现,每次循环的相同数据;
B的结果:

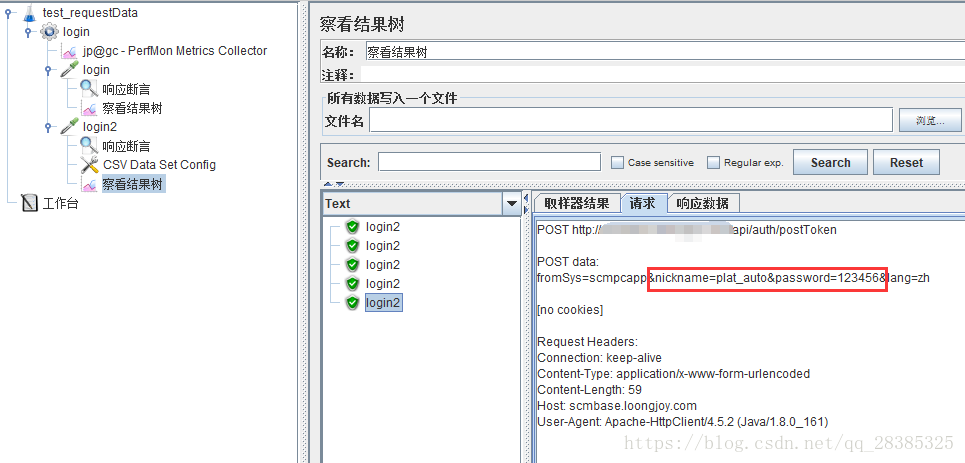
两个结果的请求数据不同,有正常循环。
由此可以得出结论。
这只是我部分实践后得出的结论,如果大家有不同的看法请与我交流,多谢!
PS:关于参数为空时,为什么发送的请求是显示的“+”,还未找到原因