一。图解
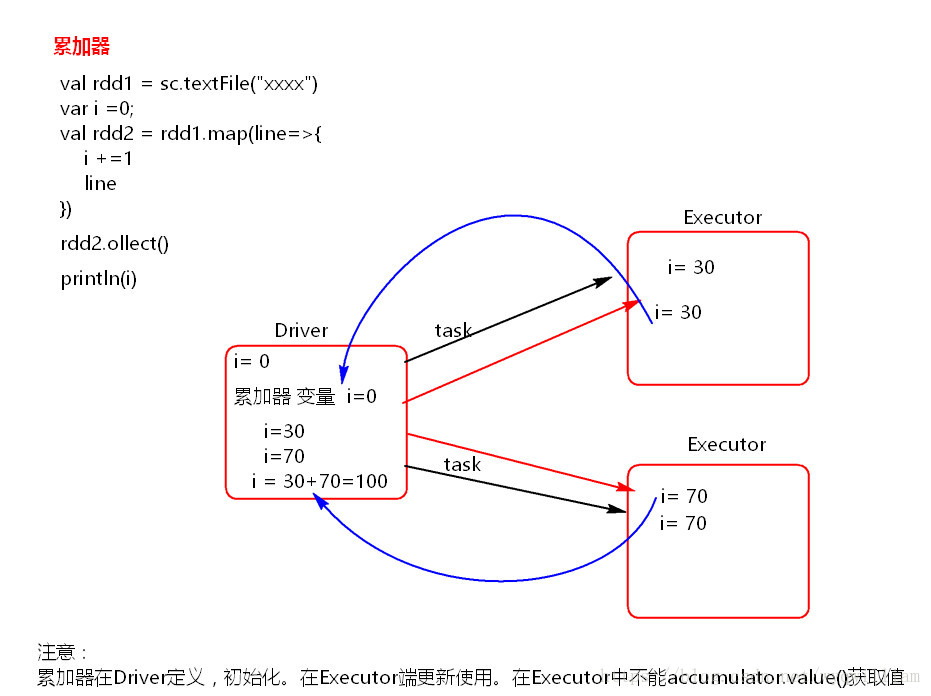
二。原理
累加器在Driver端定义赋初始值,累加器只能在Driver端读取,在Excutor端更新。
三。代码
package com.bjsxt
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
object Scala {
def main(args: Array[String]): Unit = {
/**
* 累加求和
*/
val conf=new SparkConf().setAppName("test").setMaster("local")
val sc=new SparkContext(conf)
val rdd1=sc.textFile("./words")
/**
* 初始化
* i=0
* 常量的初始化用var
*/
var i=0
rdd1.map(line=>{
/**
* 这个i是在executor端去执行的
* map 是一对一的
* 是一遍一遍地区处理的
*/
i+=1
println("Executor is ="+i)
line
}).collect()//此处的collect是为了触发执行,没有别的意思
println("Driver i ="+i)//这个i是在driver端,不会进入Executor端去执行
/**
* 或者可以自定义累加求和(如下所示)
*/
val accumulator=sc.accumulator(0)
rdd1.map(lin=>{
accumulator.add(1)
}).collect()
println("Driver accumulator ="+accumulator.value)
}
}