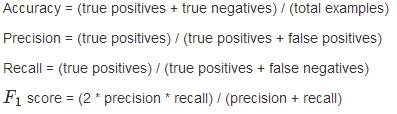转载自:https://blog.csdn.net/qq_38156052/article/details/78270458
经典算法
一、SVM(支持向量机)
(1)概念:支持向量机SVM(Support Vector Machine)是一个有监督的学习模型,通常用来进行模式识别、分类、以及回归分析。所谓支持向量,就是指距离分隔超平面最近的点。
(2)理论背景:Vapnik等人在多年研究统计学习理论基础上对线性分类器提出了另一种设计最佳准则。其原理也从线性可分说起,然后扩展到线性不可分的情况,甚至扩展到使用非线性函数中去。
(3)SVM的主要思想可以概括为两点:
1.它是针对线性可分情况进行分析,对于线性不可分的情况,通过使用非线性映射算法将低维输入空间线性不可分的样本转化为高维特征空间使其线性可分,从而使得高维特征空间采用线性算法对样本的非线性特征进行线性分析成为可能。
2.它基于结构风险最小化理论之上在特征空间中构建最优超平面,使得学习器得到全局最优化,并且在整个样本空间的期望以某个概率满足一定上界。
二、NMS(非极大值抑制)
(1)概念:非极大值抑制(Non-maximum suppression, NMS)的本质是搜索局部极大值,抑制非极大值元素。通常用来做边缘检测,在目标检测中常用来减少冗余框,提高精度。
三、PCA(Principal Component Analysis,主成分分析)
(1)概念:主成分分析是维数减少的主要线性技术,它将数据的线性映射到一个低维空间,从而使低维空间中数据的方差表示最大化。
四、 t-SNE(t-distributed stochastic neighbor embedding)
(1)理论背景:在介绍概念之前,了解一下流形学习方法(Manifold Learning),简称流形学习,通常可以分为线性、非线性两种。线性的有上面提到过的PCA,而t-SNE属于非线性。
(2)概念:t-SNE是流形学习的一种,属于非线性降维,主要是保证高维空间中相似的数据点在低维空间中尽量挨得近,是从SNE演化而来,SNE中用高斯分布衡量高维和地位空间数据点之间的相似性,t-SNE主要是为了解决SNE中的“拥挤问题”,用t分布定义低维空间低维空间中点的相似性。但是实际应用中SNE主要是为了可视化,以直观地了解数据的结构,并没有作为一种通用的降维方法使用。
(3)参考资料:链接1 :CSDN;链接2:知乎;链接3
名词解释
一、特征选择
概念:在机器学习和统计学中,特征选择也称为变量选择,属性选择或可变子集选择,是选择用于模型构建的相关特征(变量,预测变量)的子集的过程。
二、特征提取
概念:在机器学习、模式识别和图像处理过程中,特征提取从初始化测量数据开始,并构建出派生的价值(特征),旨在提供信息和非冗余,从而促进后续的学习和归纳步骤,在某些情况下会导致更好的人类解释。特征提取与降维有关。
三、正则化
(1)背景名词:
L0范数与L1范数
L0范数是指向量中非0的元素的个数。
L1范数是指向量中各个元素绝对值之和,也叫“稀疏规则算子”(Lasso regularization)。
总结:相对来说实际中更喜欢用L1范数,主要原因在于L0范数很难优化求解(NP难问题)
L2范数(||W||2),也叫“岭回归”(Ridge Regression)或“权值衰减weight decay”
L2范数是指向量各元素的平方和然后求平方根。
优点:L2范数有助于处理稳定性不好的情况下矩阵求逆很困难的问题。
欠拟合(underfitting,也称High-bias)、过拟合(overfitting,也称High variance)
(2)概念:通俗来说就是给需要训练的目标函数加上一些惩罚项(限制),让参数对整个目标函数的影响降低。
四、监督/无监督学习
监督学习一般可分为两类,一类为回归问题而另一类则称之为分类问题。回归问题是监督学习的一种,主要是用来对连续输出进行预测;分类问题主要是映射到离散类别
无监督学习一般分为聚类和非聚类,无监督的学习能够很少或根本不知道结果应该是什么样子。 可以从数据中推导出结构,不一定知道变量的影响,通过基于数据中变量之间的关系对数据进行聚类来推导出这种结构。
五、代价函数
预测值与真实值的差值的平方和
六、梯度下降
为了求得代价函数最小值,即最小化代价函数,提出一种梯度下降的算法来计算,即对代价函数求偏导得到使之最小的系数值。
特点:起点不同得到的局部最优解也不尽相同
七、特征缩放(feature scaling)/均值归一化(mean normalization)
在实际中往往有多个特征量,如果特征量的取值范围相差很大就容易出现梯度下降的很慢的情况,为此提出实用技巧将特征进行缩放,通常做法是将特征的取值约束到[-1,+1]范围内。

八、学习率(代价函数的更新规则)
通过画出迭代次数和代价函数值的曲线来判断如何调节学习率,一般来说如果学习率随迭代次数升高则说明学习率过大,随迭代次数下降的十分缓慢可能是学习率过小。
九、正规方程
也是求最优解,与梯度下降不同的是可以一次性求解参数值。
优点:不需要选择学习率;不需要迭代
缺点:要计算矩阵的逆,随着特征变量增加(10^4量级),计算量巨大。当样本数量比特征量少的时候容易出现矩阵不可逆的情况。删除多余或重复特征
十、精度(accuracy)/查准率(precision)/召回率(recall)