从神经网络到循环神经网络再到LSTM股市预测
一、 前言
本篇文章是用来做大作业的,会讲到神经网络基础、逆反馈算法推导、循环神经网络和LSTM基础(这里关于LSTM是参考【1】)以及它们的用于股市预测的实例。神经网络(NeuralNetworks)是一种用训练数据拟合目标函数的黑箱模型,只要数据量足够大,它可以拟合出输入到输出之间的任意函数关系,这在原理上是比较难解释的,但已经有许多工作从神经网络中抽取易于理解的符号规则用于改善神经网络的可解释性。传统的神经网络模型的输入是没有时间关联性的,一个输入对应一个输出,上一个输入不影响下一个输入,而循环神经网络(Recurrent neural Network)就是一种可以处理这种序列数据输入问题的神经网络结构模型,比如我们需要判断句子情感类型或者为电影每一帧画面贴标签都可以用RNN。
二、神经网络(Neural Network)
1.初识神经网络
神经网络是干什么的?它最重要的作用就是用于端到端的分类,图片的分类、文字的文类都是将需要将分类的内容以数值向量的形式输入给模型,然后通过我们上文说的黑箱操作进行分类得到一个数值或者向量的分类结果。举一个简单的例子,在识别手写数字的时候,输入层是28×28的图像像素点矩阵,输出层是[ 1., 0., 0., ..., 0., 0., 0.]这样的单行矩阵,第一列是1表示分类的结果是1,中间的隐层(hidden layer)就是我们的黑箱。
2.神经元模型
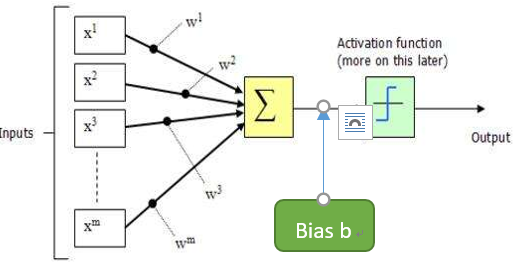
神经网络中的最基本的组成成分就是神经元(neuron),输入、输出的激活层中每一个最小的单位就是神经元,下图是神经元模型的过程分析,神经元收到外部m个输入信号(可能是一个,也有可能是多个由其他神经元传输过来的),首先对所有信号进行加权叠加然后判断是否大于神经元阙值,如果大于则送入激活函数进行输出,如下图就是一个神经元模型的网络结构。
3.单层网络
神经网络的学习规则就是通过调整权重和阙值去拟合函数,这种调整依赖于上一个神经元激励值的大小,如图就是一个单层神经网络(感知机),通过调整三个权重它可以去拟合一些简单的线性分类函数。

4.多层网络
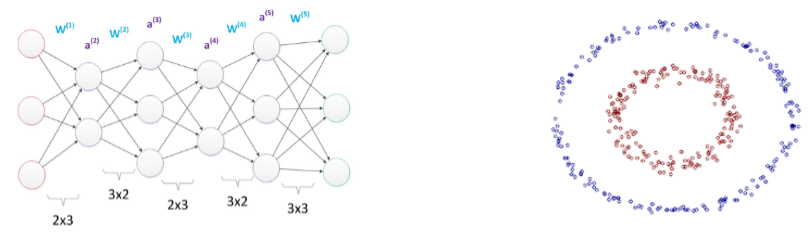
如果感知机只有一层,它的学习能力是非常有限的,在学习非线性问题时由于模型找不到合适的权重,会发生权重震荡的现象,如果考虑到非线性问题就需要用到多层网络,即在输入层和输出层之间加上若干隐层,换句话说多层网络就是通过激活函数不断地增加拟合函数的纬度,而用非线性函数分类明显更加容易,如图是一个含有四个隐层的多层网络(图引用于【2】)和一个线性不可分问题示例。
5.误差逆传播算法(BackPropagation)
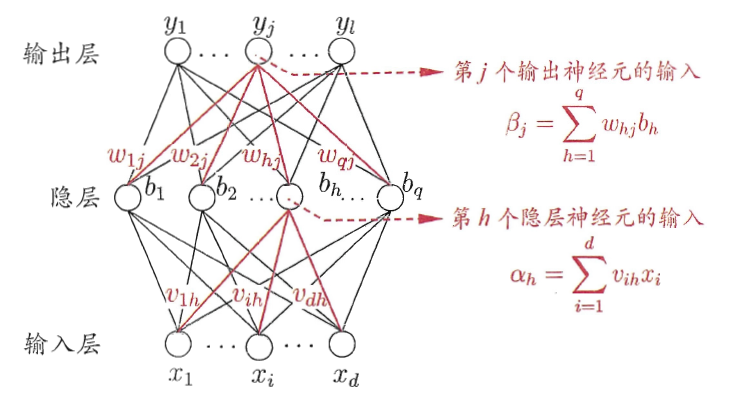
多层网络的学习能力较单层网络相比强得多,但是它的训练是非常麻烦的,常用的方法是误差逆传播算法也称反向传播算法,本节以下图含有一层隐层的网络为例介绍BP的原理。

5.存在问题
神经网络的隐层数量足够就可以拟合任何复杂的函数,但是经常会出现过拟合的现象,解决这样的问题一般由两种策略:一是通过设置训练集和验证集,当训练集误差降低但验证集误差升高则停止训练;第二种则是正则化,可以在损失函数上加L1或者L2正则化项,用于描述算法复杂度,具体可以参考李航老师的《统计学习方法》。
三、循环神经网络(RecurrentNeural Network)
1.循环神经网络结构
循环神经网络是用于预测序列数据的(比如文本、语音、视频、图像、气象和股票数据等),传统的神经网络隐层到输出层之间是全连接,但是当我们的数据是一组有关联的时间序列信息时我们需要在隐层实现内部神经元间的相互作用,即系统隐层的输出会保留在网络里,和系统下一刻的输入一起共同决定下一刻的输出,而每一个输入神经元就是一个时刻的信息。如下图中,每个时间点输入信息包含了上一层隐层和信息和此时间点的信息。
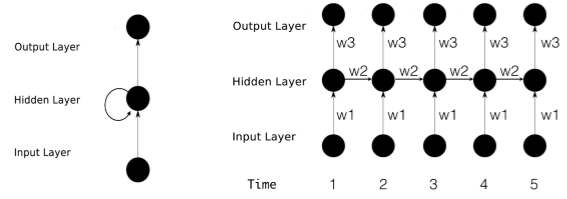
对每个隐层神经元内部进行分析,每神经元都会对原始输入和上一个时间点(神经元)的输入进行加工(tanh激活函数),如下图:
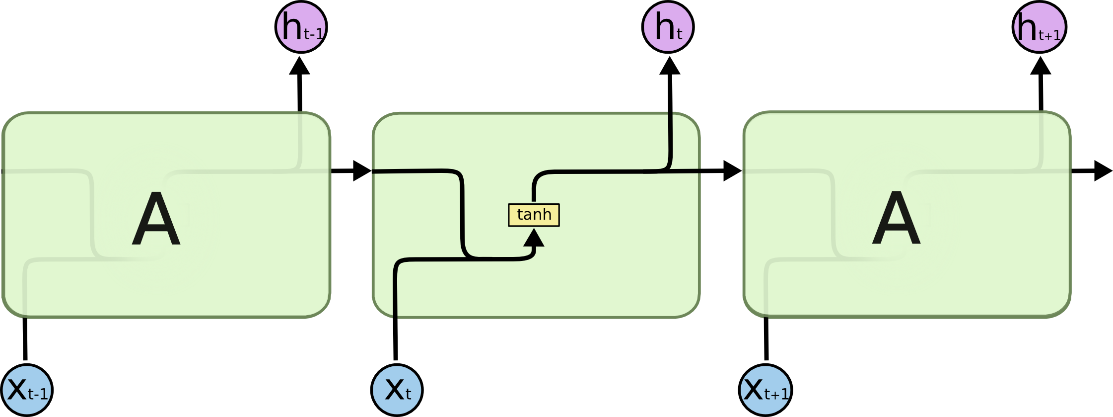
2. 基于时间的反向传播算法BPTT(Back Propagation Trough Time)
在讲RNN的训练之前首先需要讲一下RNN用到的activation function tanh,其实很简单就是双曲正切函数,它和sigmoid的区别在于它在(-1,1)区间函数值变化没有前者那么敏感,用于梯度求解更不容易发生梯度弥散的现象。对于RNN的训练和传统的神经网络相似,前向传播只需要依次按照时间的顺序计算每个时间点的输出值就行,反向传播需要在BP算法上加时序变化, 从最后一个时间将累积的残差传递回来。
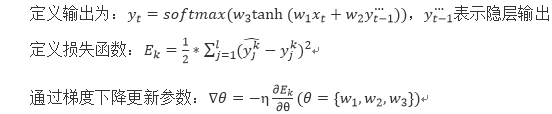
3.存在问题
上文也说了,为了解决梯度弥散或者梯度爆炸的现象我们选择用tanh而不用sigmoid,但只能在网络层次较低的时候降低发生概率,一般解决这个问题有两种策略:1.换用如今神经网络常用的激活函数relu;2.改进网络结构,如:LSTM,GRU.同时LSTM也有利于解决长期依赖问题,就是说当相关信息和当前预测位置之间的间隔变大了之后RNN的感知能力就会下降。
四、LSTM(Long Short-Term Memory)
1.LSTM网络结构总叙述
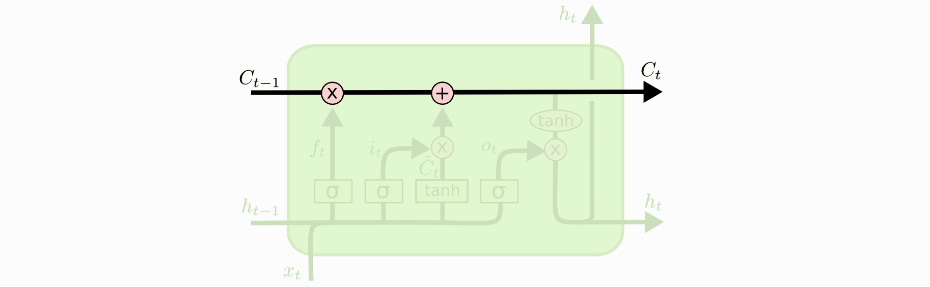
LSTM是一种时间递归神经网络,适合于处理和预测时间序列中间隔和延迟相对较长的事件, 基于 LSTM 的系统可以学习翻译语言、控制机器人、图像分析、文档摘要、语音识别图像识别、手写识别、控制聊天机器人、预测疾病、点击率和股票、合成音乐等等任务。LSTM之所以可以解决延迟相对较长的输入信息是因为它加入了一种用于信息选择的Cell,每个Cell中含有三种门控结构和一个状态参数Cell State(细胞状态),门控结构来去除或者增加信息到细胞状态的能力,它包含一个 sigmoid 神经网络层和一个pointwise 乘法操作。接下来就结合下图讲解一下三种门控结构和细胞状态以及详细的网络结构(本小结主要参考【1】,这是原论文的译文,讲解的十分清楚):

2.细胞状态
细胞状态就是 Ct,类似于细胞状态类似于传送带,信息直接在整个链上运行,只有一些少量的线性交互。
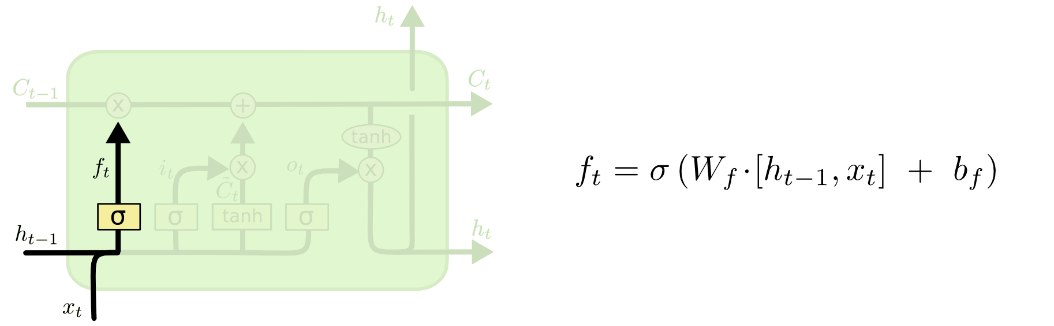
3.遗忘门

4.输入门
输入门决定什么信息应该被存入细胞状态,输入门由两部分组成,第一部分使用了sigmoid激活函数,输出为 it,第二部分使用了tanh激活函数,输出为Ct' , 两者的结果后面会相乘再去更新细胞状态。
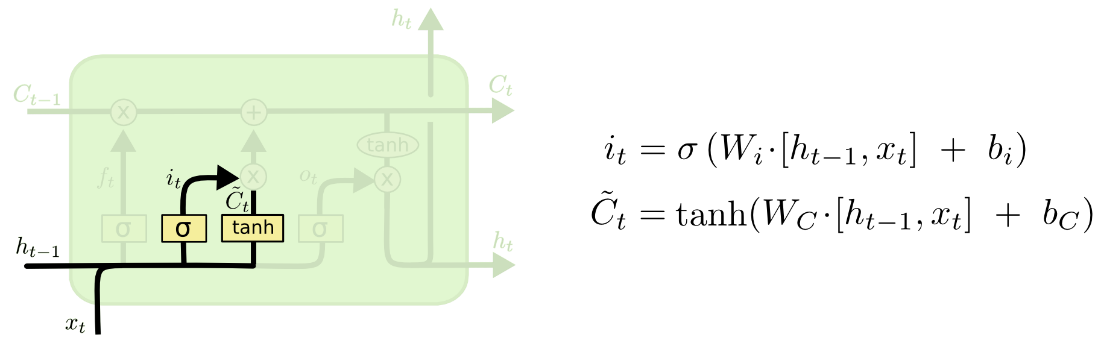
5.更新细胞状态
旧细胞状态与舍弃信息 ft相乘,再加上输入门中两种信息的乘积,得到下一个时间的细胞信息Ct。
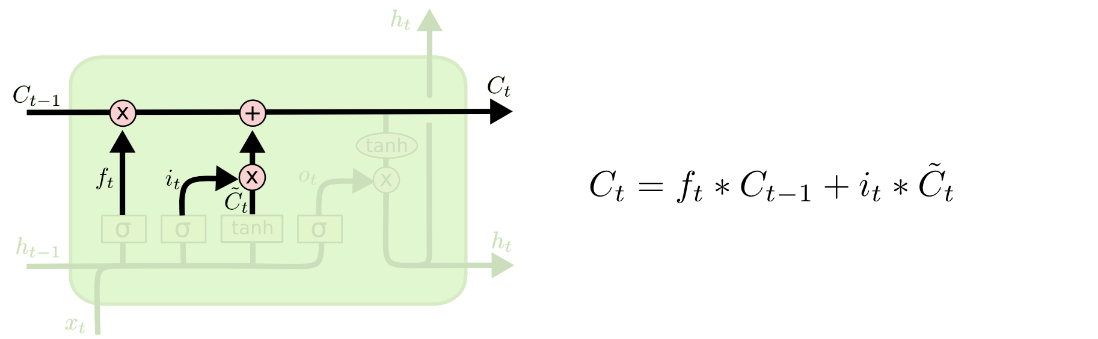
6.输出门
输出门确定输出什么值,这个输出将会基于我们的细胞状态,但是也是一个过滤后的版本。首先,我们运行一个 sigmoid 层来确定细胞状态的哪个部分将输出出去。接着,我们把细胞状态通过 tanh 进行处理(得到一个在 -1 到 1 之间的值)并将它和sigmoid 门的输出相乘,最终我们仅仅会输出我们确定输出的那部分。
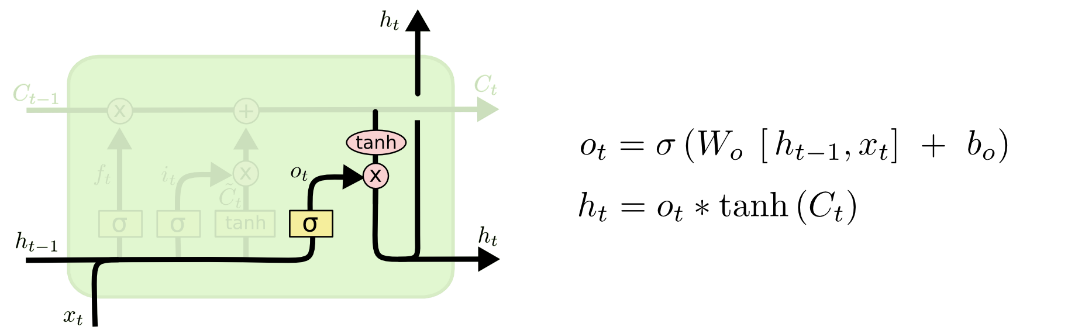
四、LSTM实例:股票分析
1.介绍
此实验是基于五百支股票的每分钟报价得到的标准普尔500指数(SP500)对下一分钟的SP500进行预测,标准普尔500指数具有采样面广、代表性强、精确度高、连续性好等特点,被普遍认为是一种理想的股票指数期货合约的标的。本次实验数据来自【3】团队在STATWORX上进行协作,Google Finance API抓取了每分钟的标准普尔500指数。
2.代码分析
#——————————————————数据分析——————————————————————
data = pd.read_csv('data_stock.csv')
sp500=data['SP500']
stock_value=data.iloc[1]
stock_value_example=stock_value.values[2:]
plt.figure(figsize=(12,4),dpi=80)
plt.title('Examples of stock price volatility')
plt.plot(stock_value_example, 'y.')
plt.show()
plt.figure(figsize=(12,4),dpi=80)
plt.title('Examples of stock sp500 value')
plt.plot(sp500, 'r-')
plt.show()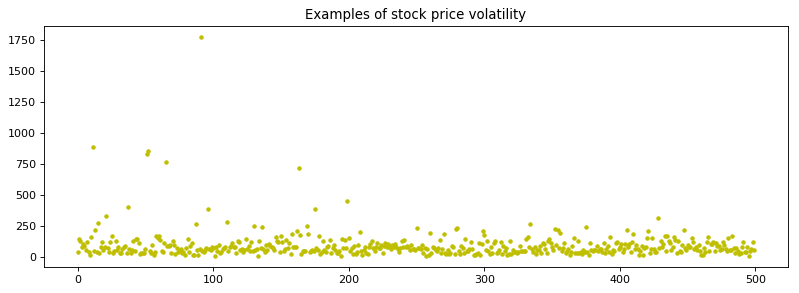

#——————————————————数据读入——————————————————————
data = data.drop(['DATE'], 1)
row = data.shape[0]
col = data.shape[1]
data_value = data.values
print(row,col,'\n',data_value,'\n')
train_start = 0
train_end = int(np.floor(0.8*row))
test_start = train_end
test_end = row
data_train = data_value[np.arange(train_start, train_end), :]
data_test = data_value[np.arange(test_start, test_end), :]
print(data_train.shape,data_test.shape)
#———————————————数据归一处理———————————————————
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(data_train)
data_train = scaler.transform(data_train)
data_test = scaler.transform(data_test)
print(data_train)
#—————————————————设置超参数—————————————————————
lr = 1e-3
lr_decay = 0.5 # 学习速率衰减
batch_size = 100
input_size = 500
time_step = 100#时间步
hidden_size = 20
layer_num = 2
class_num = 1
#用于dropout.每批数据输入时神经网络中的每个单元会以1-keep_prob的概率不工作
keep_prob = 0.8
cell_type="lstm"#———————————————数据划分————————————————
X_train,y_train,batch_index=[],[],[]
for i in range(len(data_train)-time_step):
if i % batch_size==0:
batch_index.append(i)
x=data_train[i:i+time_step,1:]
y=data_train[i:i+time_step,0]
X_train.append(x.tolist())
y_train.append(y.tolist())
batch_index.append((len(data_train)-time_step))
X_test,y_test=[],[]
for i in range(len(data_test)-time_step):
x=data_test[i:i+time_step,1:]
y=data_test[i:i+time_step,0]
X_test.append(x.tolist())
y_test.append(y.tolist())
y_train=np.reshape(y_train,[1500,100,1])
y_test=np.reshape(y_test,[300,100,1])
print(np.shape(y_train))
print(np.shape(X_train)
#—————————————————网络结构—————————————————————
from tensorflow.contrib import rnn
X_input=tf.placeholder(tf.float32, shape=[None,time_step,input_size])
Y_input=tf.placeholder(tf.float32, shape=[None,time_step,1])
W= tf.Variable(tf.truncated_normal([hidden_size, class_num], stddev=0.1), dtype=tf.float32)
bias = tf.Variable(tf.constant(0.1,shape=[class_num]), dtype=tf.float32)
#步骤1:定义输入层
X=X_input
#步骤2:定义LSTM_cell
def lstm_cell(cell_type, num_nodes, keep_prob):
if cell_type == "lstm":
cell = tf.contrib.rnn.BasicLSTMCell(num_nodes)
else:
cell = tf.contrib.rnn.LSTMBlockCell(num_nodes)
cell = tf.contrib.rnn.DropoutWrapper(cell, output_keep_prob=keep_prob)
return cell
# 步骤3:调用 MultiRNNCell 来实现多层 LSTM
mlstm_cell = tf.contrib.rnn.MultiRNNCell([lstm_cell(cell_type, hidden_size, keep_prob) \
for _ in range(layer_num)], state_is_tuple = True)
# 步骤4:初始化state
init_state = mlstm_cell.zero_state(batch_size, dtype=tf.float32)#—————————————————隐层输出—————————————————————
outputs=[]
state = init_state
with tf.variable_scope('RNN'):
for timestep in range(time_step):
if timestep > 0:
tf.get_variable_scope().reuse_variables()
(cell_output, state) = mlstm_cell(X[:, timestep, :], state)
outputs.append(cell_output)
h_state =outputs#——————————————————训练模型——————————————————
#预测值
y_pre=[]
for i in range(100):
pre = tf.matmul(h_state[i], W) + bias
y_pre.append(pre)
#损失函数
loss_function=tf.reduce_mean(abs(Y_input-y_pre))
train_op=tf.train.AdamOptimizer(lr).minimize(loss_function)
correct_prediction = tf.equal(y_pre,Y_input)
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(500):
for step in range(len(batch_index)-1):
cost,acc,_= sess.run([loss_function, accuracy, train_op], feed_dict={\
X_input:X_train[batch_index[step]:batch_index[step+1]],\
Y_input: y_train[batch_index[step]:batch_index[step+1]]})
if (i % 50) == 0:
print('The current step is',i,'the loss function value is' ,cost,'\n')
save_path = saver.save(sess,"LSTM_model/lstm_mode.ckpt") 3.训练结果
通过500次迭代,每次迭代选择100分钟的时间序列,输入是一个[100,500,100]的三维矩阵,输出是一个[100,100,1]的三位矩阵,损失函数选择两个矩阵之差的均值,可以看到损失函数的总体呈下降趋势,同时没有陷入局部最优点。

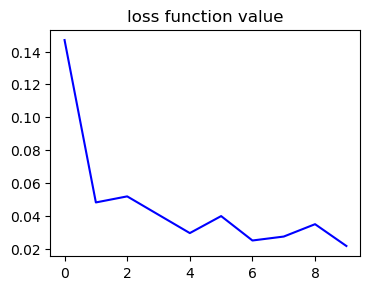
4.结果分析
以1600到1650分钟的SP500指数为例,分析预测结果,发现实际结果和预测结果大致趋势相同:

同时分析1到1600分钟的500支股票价格的变化浮动得到涨跌幅排行榜:
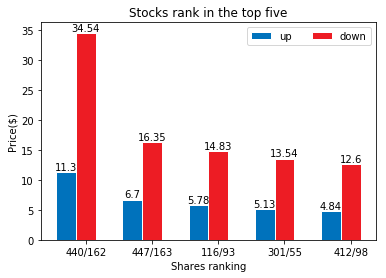
参考文献:【1】https://www.jianshu.com/p/9dc9f41f0b29
【2】https://www.cnblogs.com/maybe2030/p/5597716.html
【3】https://cloud.tencent.com/developer/article/1042820