异常
在程序开发中,如果对某些代码的执行不确定(程序的语法完全正确)
可以增加try来捕获异常
try:
尝试执行的代码
except:
出现错误的处理例如:
try:
num = int(raw_input('请输入一个整数: '))
except:
print '请输入正确的整数'
# 无论是否输入错误额,程序都会正常得执行
print '*' * 50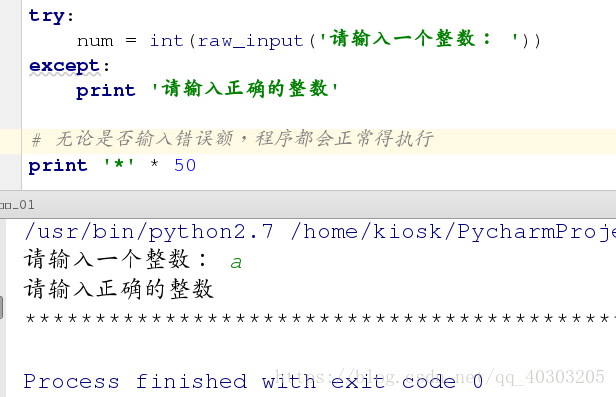
当python解释器抛出异常时,最后一行错误信息的第一个单词,就是错误类型
# 1.提示用户输入一个整数
# 2.使用8除以用户输入的整数并且输出
try:
num = int(raw_input('请输入一个整数: '))
result = 8 / num
print result
except ZeroDivisionError:
print '除0错误 0不能做除数'
except ValueError:
print '请输入正确的整数'
# 1.输入的不是数字
# 2.0不能做除数

捕获未知错误
在开发的时候,要判断所有可能出现的错误,是有一定难度的
如果希望程序无论出现任何错误,都不会因python解释器抛出异常而终止
可以再增加一个except
try:
num = int(raw_input('请输入一个整数: '))
result = 8 / num
print result
# 捕获未知异常
# result:一个变量名,可以随便起名
except Exception as result:
print '未知错误 %s' % result
完整格式:
try:
# 尝试执行的代码
pass
except 错误类型1:
pass
except 错误类型2:
pass
except Exception as result:
else:
# 没有异常才会执行的代码
pass
finally:
# 无论是否有异常,都会执行的代码
pass例如:
try:
num = int(raw_input('请输入一个整数: '))
result = 8 / num
print result
# 捕获未知异常
# result:一个变量名,可以随便起名
except Exception as result:
print '未知错误 %s' % result
# 只有在没有异常的时候,才会执行的代码
else:
print '尝试成功!'
# 无论是否有异常,都会执行的代码
finally:
print '*' * 30

异常的传递
异常的传递–当函数/方法执行出现异常,会将异常传递给函数/方法调用的一方
如果传递到主程序,依旧没有异常处理,程序才会终止,可以在主程序中增加异常捕获,
而在主函数中调用其他函数,只要出现异常,都会传递到主函数的异常捕获中,
这就不需要在代码中,增加大量的异常捕获,能够保证代码的整洁
例如:
def demo1():
return int(raw_input('请输入一个整数: '))
def demo2():
return demo1()
# 利用异常的传递性,在主程序中捕获异常
try:
print demo2()
except Exception as result:
print '未知错误 %s' % result
练习:
判断用户输入的密码
1.<8 错误
2.>=8 返回输入的密码
def input_passwd():
# 提示用户输入密码
pwd = raw_input('请输入密码: ')
# 判断密码的长度 >=8,就返回用户输入的密码
if len(pwd) >= 8:
return pwd
# <8主动抛出异常
# print '主动抛出异常'
# 创建异常对象(可以添加错误信息)
ex = Exception('密码长度不够')
raise ex
# 注意:只抛出异常而不捕获异常,代码会出错
try:
print input_passwd()
except Exception as result:
print result
# 先创建异常对象,再抛出异常,再在主函数中捕获异常
断言
可以理解为提前预言,让人更好的知道错误原因
示例:
def func(num, div):
assert (div != 0), 'div不能为0'
return num / div
print func(10, 0)
模块
Python 模块(Module),是一个 Python 文件,以 .py 结尾,包含了 Python 对象定义和Python语句。
模块让你能够有逻辑地组织你的 Python 代码段。
把相关的代码分配到一个模块里能让你的代码更好用,更易懂。
模块能定义函数,类和变量,模块里也能包含可执行的代码。
例如:写两个简单的模块 test1 test2
test1:
title = '模块1'
# 函数
def say_hello():
print '我是%s' % title
# 类
class Cat(object):
passtest2:
title = '模块2'
# 函数
def say_hello():
print '我是%s' % title
# 类
class Dog(object):
pass模块的引入
模块定义好后,我们可以使用 import 语句来引入模块
例如:
import test1
import test2
test1.say_hello()
test2.say_hello()
cat = test1.Cat()
print cat
dog = test2.Dog()
print dog
使用as指定模块的别名(大驼峰命名法)
# 使用as指定模块的别名(大驼峰命名法)
import test1 as CatModule
import test2 as DogModule
CatModule.say_hello()
DogModule.say_hello()
cat = CatModule.Cat()
print cat
dog = DogModule.Dog()
print dogfrom…import 语句
Python 的 from 语句让你从模块中导入一个指定的部分到当前命名空间中
例如:
from test1 import Cat
from test2 import say_hello
from test1 import say_hello as test1_say_hello
say_hello()
test1_say_hello()
miaomiao = Cat()
print miaomiaopython的解释器在导入模块的时候,会:
- 搜索当前目录指定的模块文件,如果有就直接导入
- 如果没有,再搜索系统目录
注意:在开发时,给文件起名,不要和系统模块文件重名
在很多python文件中会看到以下格式的代码
# 导入模块
# 定义全部变量
# 定义类
# 定义函数
# 在代码的下方
def main():
pass
if __name__ == '__main__'
main()__name__属性
__name__属性可以做到,测试模块的代码只在测试情况下被运行,而在被导入时不会
__name__是python的一个内置属性,记录着一个字符串
- 如果是被其他文件导入时,
__name__就是模块名 - 如果时当前执行的程序,
__name__就是__main__
例如:写一个简单模块test:
# 全局变量,函数,类,直接执行的代码不是向外界提供的工具
def say_hello():
print 'hello'
# 如果直接在模块中输入,得到的时__main__
if __name__ == '__main__':
print __name__
# 文件被导入的时候,能够直接被执行的代码不需要被执行
print 'lily'
say_hello()调用这个模块,不会执行能够直接被执行的代码

文件
操作文件的函数/方法
在python中要操作文件需要记住的1个函数和3个方法
python中一切皆对象
- open :打开文件,并且返回文件操作对象
- read :将文件内容读取到内存
- write:将指定内容写入文件
- close:关闭文件
open函数负责打开文件,并且返回文件对象
read/write/close三个方法都需要通过文件对象来调用
read方法–读取文件
open函数的第一个参数是要打开的文件名(文件名区分大小写)
如果文件存在,返回文件操作对象
如果文件不存在,会抛出异常
read方法可以一次性读入并返回文件的所有内容
close方法负责关闭文件
例如:
# 打开文件
file = open('README')
# 操作文件 读/写
# read方法:读取文件内容(一次性返回文件的所有内容)
text = file.read()
print text
# 关闭文件
# close 方法:负责关闭文件
file.close()
# 在开发中,通常会先编写打开和关闭的代码文件指针:
文件指针标记从哪个位置开始读取数据
第一次打开文件时,通常文件指针会指向文件的开始位置
当执行了read方法后,文件指针会移动到读取内容的末尾
例如:
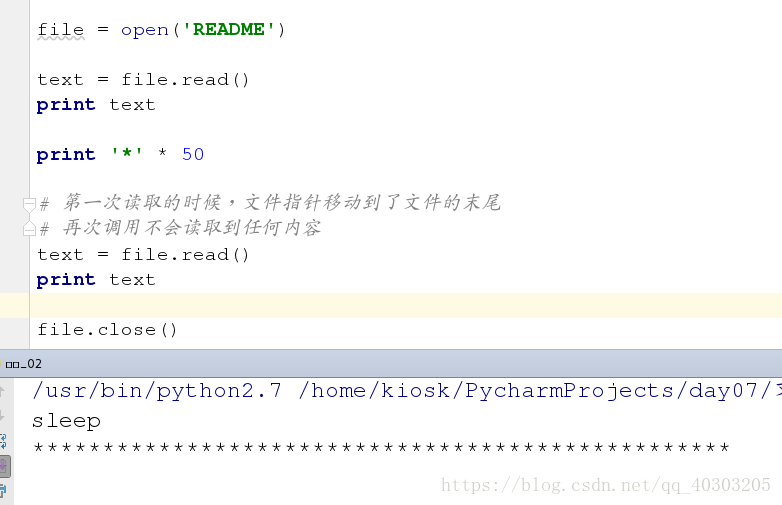
file = open('README')
text = file.read()
print text
print '*' * 50
# 第一次读取的时候,文件指针移动到了文件的末尾
# 再次调用不会读取到任何内容
text = file.read()
print text
file.close()
打开文件的方式:
name = open(‘文件名’, ‘访问方式’)
例如:
以写的方式打开文件
# 以写的方式打开文件,如果文件存在会被覆盖,如果文件不存在,创建新文件
file = open('README', 'w')
file.write('sleep')
file.close()以追加方式打开文件
# 以追加方式打开文件
# 如果该文件存在,文件指针会放在文件的末尾
# 如果文件不存在,创建文件并写入
file = open('README', 'a')
file.write('zZZ')
file.close()按行读取文件
read方法默认会把文件的所有内容一次性读到内存
如果文件太大,对内存的占用会非常严重
readline方法:
readline方法可以一次性读取一行内容
方法执行后,会把文件指针移动到下一行,准备再次读取
例如:
# 读取大文件的正确姿势
file = open('README')
# 为什么要写成死循环:因为我们不知道要读取的文件有多少行
while True:
text = file.readline()
# 如果文件指针到文件的最后一行,那么就读不到内容了
if not text:
break
# 每读取一个行,末尾都已经有了一个\n
print text
file.close()拷贝文件:
# 源文件以只读的方式打开
file_read = open('README')
# 目标文件以写的方式打开ia
file_write = open('README_COPY', 'w')
# 从源文件中读取内容
text = file_read.read()
# 将读取到的内容写到目标文件中
file_write.write(text)
# 关闭文件
file_read.close()
file_write.close()按行拷贝文件:
file_read = open('README')
file_write = open('README_COPY', 'w')
while True:
text = file_read.readline()
if not text:
break
file_write.write(text)
file_read.close()
file_write.close()with结构
关键字with在不需要访问文件狗将其关闭,在这个程序中,
我们调用了open( ),但没有调用close( );你也可以调用open()和close( )来打开和关闭文件,但这样做时,如果程序存在bug,导致close( )语句没有执行,
文件将不会关闭,未妥善地关闭文件可能会导致数据丢失或受损,
如果在程序中过早的调用close( )
你会发现需要使用文件时它已经(无法访问),
这会导致更多的错误,你并非在任何情况下都能轻松的确定关闭文件的恰当时机
通过使用with结构,可以使python去确定,
你只管打开文件,并且在需要时使用它,
python会在合适的时候自动将其关闭
例如:
with open('haha') as file_object:
contents = file_object.read()
print contents按行读取文件
filename = 'haha'
with open(filename) as file_object:
for line in file_object:
print line拷贝文件:
filename = 'linux'
with open(filename, 'w') as file_object:
file_object.write('I love python./n')
file_object.write('I love linux.')将一个文件的内容追加到另一个文件:
filename = 'linux'
with open(filename, 'a') as file_object:
file_object.write('I love python./n')
file_object.write('I love linux.')