一、实验目的
1.掌握图的相关概念。
2.掌握用邻接矩阵和邻接表的方法描述图的存储结构。
3.掌握图的深度优先搜索和广度优先搜索遍历的方法及其计算机的实现。
4.理解最小生成树的有关算法
二、实验内容
1.用邻接表作为图的存储结构建立一个图,并对此图分别进行深度优先搜索和广度优先搜索遍历。
2.用邻接矩阵作为图的存储结构建立一个网,并构造该网的最小生成树(选做)。
三、实验要求
1、用邻接表作为图的存储结构建立一个图,并对此图分别进行深度优先搜索和广度优先搜索遍历。
(1)输入无向图的顶点数、边数及各条边的顶点对,建立用邻接表表示的无向图。
(2)对图进行深度优先搜索和广度优先搜索遍历,并分别输出其遍历序列。
2、用邻接矩阵作为图的存储结构建立一个网,构造该网的最小生成树。
(1)输入无向图的顶点数、边数及各条边的顶点序号对和边上的权值,建立用邻接矩阵表示的无向网。
(2)用Prim算法构造该无向网的最小生成树。
(3)在实现普里姆算法时,采用邻接矩阵cost表示给定的无向网,矩阵元素定义为:
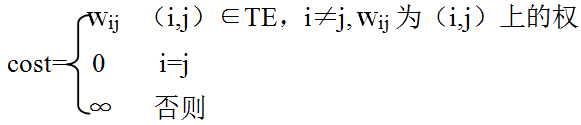
四、详细程序清单
//1.邻接表、DFS和BFS
#include <stdio.h>
#include <stdlib.h>
#define MAX_VERTEX_NUM 30
typedef struct arcnode//边表结点
{
int adjvex;//邻接点域,存储该顶点对应的下标
struct arcnode *nextarc;//链域,指向下一个邻接点
} arcnode,*Linkarc;
typedef struct//顶点表节点
{
arcnode *firstarc;//边表头指针
int tag;//0代表未被访问,1代表已被访问
}vexnode;
typedef struct//顶点数组
{
vexnode adjlist[MAX_VERTEX_NUM];
int vexnum,arcnum;//图中当前顶点数和边数
}Algraph;
typedef struct{//顺序队列
int *base;
int front;
int rear;
}Sqqueue;
Sqqueue Q;
void Initqueue(Sqqueue&Q)//初始化队列
{
Q.base=(int*)malloc(sizeof(int));
Q.front=Q.rear=0;
}
void Enqueue(Sqqueue &Q, int e)//入队列
{
Q.base[Q.rear]=e;
Q.rear=Q.rear+1;
}
int Dequeue(Sqqueue &Q)//出队列
{
int e;
e=Q.base[Q.front];
Q.front=Q.front+1;
return e;
}
void CreateUDG(Algraph*G)//创建无向图的邻接表
{
int i,j,k,w,v,s,d;
Linkarc p,q;
printf("输入顶点数:");
scanf("%d",&G->vexnum);
printf("输入边数:");
scanf("%d",&G->arcnum);
for (i=1;i<=G->vexnum;i++)//顶点表
{
G->adjlist[i].tag=0;//初始化为0
G->adjlist[i].firstarc=NULL;
}
for (k=1;k<=G->arcnum;k++)//顶点所包含的链表
{
printf("输入边%d的一对顶点:",k);
scanf("%d%d",&s,&d);
p=(arcnode*)malloc(sizeof(arcnode));
q=(arcnode*)malloc(sizeof(arcnode));
p->adjvex=d; q->adjvex=s;
p->nextarc=G->adjlist[s].firstarc;G->adjlist[s].firstarc=p;
q->nextarc=G->adjlist[d].firstarc;G->adjlist[d].firstarc=q;
}
}
void Dfs(Algraph*G,int v) //深度优先遍历
{
int w;
arcnode *p;
printf("%5d",v);
G->adjlist[v].tag=1;
p=G->adjlist[v].firstarc;
while(p!=NULL)
{
w=p->adjvex;
if(G->adjlist[w].tag==0)
Dfs(G,w);
p=p->nextarc;
}
}
void Bfs(Algraph*G,int v) //广度优先遍历
{
int v1,w;
arcnode *p;
Q.base=NULL;
Initqueue(Q);
printf("%5d",v);
G->adjlist[v].tag=1;
Enqueue(Q,v);
while(Q.front!=Q.rear)
{
v1=Dequeue(Q);
p=G->adjlist[v1].firstarc;
while(p!=NULL)
{
w=p->adjvex;
if(G->adjlist[w].tag==0)
{
printf("%5d",w);
G->adjlist[w].tag=1;
Enqueue(Q,w);
}
p=p->nextarc;
}
}
}
int main()
{
int v=1;//题目没有规定,默认从1结点开始遍历
Algraph*G=(Algraph*)malloc(sizeof(Algraph));
CreateUDG(G);
printf("深度优先遍历为:");
Dfs(G,v);
for (int i=1;i<=G->vexnum;i++)
G->adjlist[i].tag=0;//将全部tag重新赋0
printf("\n广度优先遍历为:");
Bfs(G,v);
return 0;
} //2.邻接矩阵和prim
#include<stdio.h>
#include<stdlib.h>
#define INFINITY 0x7FFFFFFF //定义最大值∞
#define MAX_VEX_NUM 50
#define MAX_VERTEX_NUM 2500
typedef struct
{
int vexs[MAX_VERTEX_NUM];//顶点名
int cost[MAX_VEX_NUM][MAX_VEX_NUM];//各边权值
int vexnum,arcnum;
}Mgraph;
Mgraph G;
typedef struct ///辅助数组
{
int lowcost; //权值
int closest; //点序号
}Closedge;
Closedge closedge[MAX_VEX_NUM];
int LocateVex(Mgraph &G,int x)
{
for(int i=1;i<=G.vexnum;i++)
{
if(x==G.vexs[i])
return i;
}
}
void CreateUDN(Mgraph &G) //在邻接矩阵存储结构上,构造无向网G
{
int i,j,k,w;
int v1,v2;
printf("输入顶点数和边数:");
scanf("%d%d",&G.vexnum,&G.arcnum);//读入顶点和边数目
printf("输入各顶点名\n");
for(i=1;i<=G.vexnum;i++)//顶点名
{
printf("点%d:",i);
scanf("%d",&G.vexs[i]);
}
for(i=1;i<=G.vexnum;i++) //邻接矩阵初始化
for(j=1;j<=G.vexnum;j++)
{
if(i==j) G.cost[i][j]=0;
else G.cost[i][j]=INFINITY;
}
printf("输入各顶点对和权值\n");
for(k=1;k<=G.arcnum;k++)//构造邻接矩阵
{
scanf("%d%d%d",&v1,&v2,&w);
i=LocateVex(G,v1); j=LocateVex(G,v2);//确定v1、v2在图中的位置
G.cost[i][j]=w;
G.cost[j][i]=G.cost[i][j];
}
}
void Prim(Mgraph G,int v)
{
int i,j,k,min,x,y;
int sum=0;//总权值
x=LocateVex(G,v);
for(i=1;i<=G.vexnum;i++)//初始化数组closedge
{
if(i!=x)
{
closedge[i].lowcost=G.cost[x][i];
closedge[i].closest=G.vexs[x];
}
}
closedge[x].lowcost=0; //初始U={v}
for(i=1;i<G.vexnum;i++)
{
min=INFINITY;
for(j=1;j<=G.vexnum;j++)
if(closedge[j].lowcost!=0&&closedge[j].lowcost<min)
{
min=closedge[j].lowcost;
k=j;
}
printf("%d-%d:%d\n",closedge[k].closest,k,min); //输出最小边
sum+=min;
closedge[k].lowcost=0;
for(j=1;j<=G.vexnum;j++)
if (closedge[j].lowcost!=0&&G.cost[k][j]<closedge[j].lowcost)
{
closedge[j].lowcost=G.cost[k][j];
closedge[j].closest=k;
}
}
printf("总权值为%d\n",sum);
}
int main()
{
int v=1;//题目没有规定,默认从A结点开始遍历
CreateUDN(G);
printf("最小生成树为:\n");
Prim(G,v);
}
五、程序运行结果
1. 邻接表、DFS和BFS
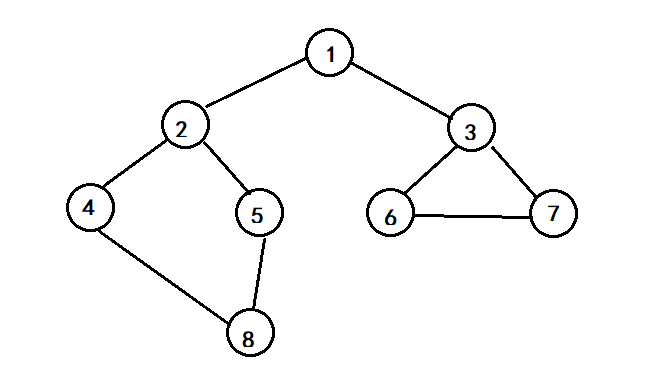

//其实遍历结果有很多种,不一定是这个,我凑巧和书上一样了。。。
2. 邻接矩阵和prim
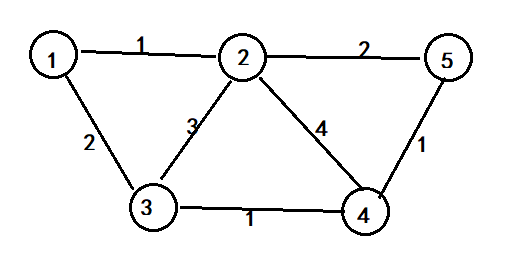

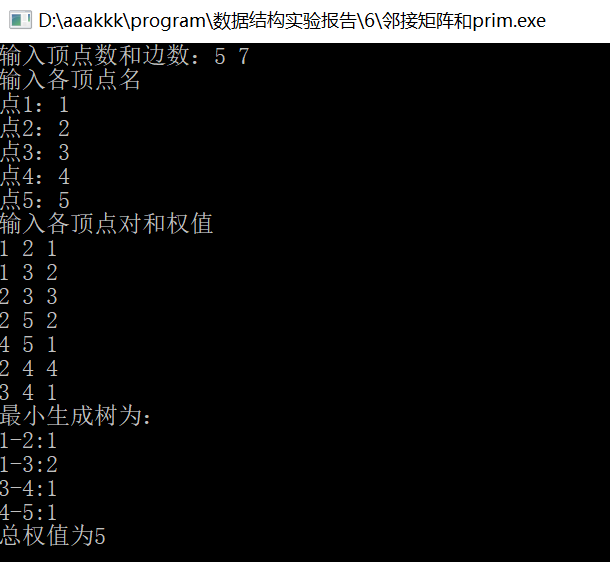
六、实验心得体会
1. 在存储稀疏图的时候,用邻接表比邻接矩阵更省空间。
2. 在邻接表上容易找到任一顶点的第一个邻接点和下一个邻接点,但要判断任一两个点之间是否相连,则需搜索第i或第j个链表,此时用邻接矩阵更方便。
3. DFS和BFS的遍历结果不一定唯一。
4. C语言是没有无穷大的,因此,一般用一个很大的数来近似替代无穷大:#define INFINITY 0x7FFFFFFF。
5. Prim算法的时间复杂度为O(n²),与网的边数无关,于是适合于稠密图;而Kruskal算法的时间主要取决于边数,于是更适合于稀疏图。