1、 循环队列的长度
我们把队列的这种头尾相接的顺序存储结构称为循环队列。
当空队列时,front==rear,而当队列满时,还是front==rear,那么如何判断此时的队列究竟是空还是满呢?
办法一:设置一个标志变量flag,当front==rear且flag=0时为队列空,当front==rear且flag=1时为队列满。
办法二:当队列空时,条件就是front=rear,当队列满时,我们修改其条件,保留一个元素空间。也就是说,队列满时,数组中还有
一个空闲单元。队列满的条件是:(rear+1)%QueueSize==front(队列的最大尺寸是QueueSize)
当rear>front时,此时队列的长度为rear-front.
当rear<front时,队列的长度分为两段,一段是QueueSize-front,另一段是0+rear,总长度是: rear-front+QueueSize
因此,通用的计算队列长度公式是:(rear-front+QueueSize)% QueueSize
2、 异步IO和同步IO
I/O 既输出/输入 (Input/Output)
同步 当一个IO操作进行时,系统停下来等待这个IO的操作完成后才会继续进行下面的计算。
异步 当一个IO操作进行时,通过多线程等方法,当CPU去处理那些不需要依赖IO执行结果的计算,充分的利用CPU的运算能力。当IO操作执行完毕时,继续执行后续的操作。
一般情况下,作为单机程序或者IO反应速度非常快等待时间非常短,使用“同步”方式对于编程的稳定性、简单性都是很好的选择,一个操作完成后再去执行其他的操作。
但是如果IO的等待时间比较长,比如打印机、慢速网络,“异步”方式就会显得非常重要了。比如打印机开始打印Word就不能进行任何的操作,用户岂不是要等的心发慌?
异步操作往往是和多线程并行密切相关的,也是目前多路、多核CPU能够释放威力的强大武器。
异步I/O的优点:异步I/O是和同步I/O相比较来说的,如果是同步I/O,当一个I/O操作执行时,应用程序必须等待,直到此I/O执行完。相反,异步I/O操作在后台运行,I/O操作和应用程序可以同时运行,提高了系统性能;使用异步I/O会提高I/O流量,如果应用是对裸设备进行操作,这种优势更加明显, 因此像数据库,文件服务器等应用往往会利用异步I/O,使得多个I/O操作同时执行。
3、 进程和线程
进程是系统进行资源分配和调度的基本单位,是操作系统结构的基础,而线程是CPU调度的基本单元。
进程的个体间是完全独立的,而线程间是彼此依存的。多进程环境中,任何一个进程的终止,不会影响到其他进程。而多线程环境中,父线程终止,全部子线程被迫终止(没有了资源)。而任何一个子线程终止一般不会影响其他线程,除非子线程执行了exit()系统调用。任何一个子线程执行exit(),全部线程同时灭亡。
进程的创建调用fork或者vfork,而线程的创建调用pthread_create,进程结束后它拥有的所有线程都将销毁,而线程的结束不会影响同个进程中的其他线程的结束。
4、 时间片轮转法
主要用于分时系统中的进程调度。为了实现轮转调度,系统把所有就绪进程按先入先出的原则排成一个队列。新来的进程加到就绪队列末尾。每当执行进程调度时,进程调度程序总是选出就绪队列的队首进程,让它在CPU上运行一个时间片的时间。时间片是一个小的时间单位,通常为10~100ms数量级。当进程用完分给它的时间片后,系统的计时器发出时钟中断,调度程序便停止该进程的运行,把它放入就绪队列的末尾;然后,把CPU分给就绪队列的队首进程,同样也让它运行一个时间片,如此往复。
5、 基于优先级的抢占式调度
每个任务赋予唯一的一个优先级(有些操作系统可以动态地改变任务的优先级)。
假如有几个任务同时处于就绪状态,优先级最高的那个将被运行。
只要有一个优先级更高的任务就绪,它就可以中断当前优先级较低的任务的执行。
6、 计算机执行指令
计算机执行指令一般分为两个阶段。第一阶段,将要执行的指令从内存取到CPU内。第二阶段,CPU对取入的该条指令进行分析译码,判断该条指令要完成的操作。然后向各部件发出完成该操作的控制信号,完成该指令的功能。当一条指令执行完后就进入下一条指令的取指操作。一般将第一阶段取指令的操作称为取指周期,将第二阶段称为执行周期。程序由一系列指令的有序集合构成,计算机按照程序设定的顺序完成一系列相关操作直到程序终止的过程叫做程序的执行过程。但是最初的电脑是是没有内存的,CPU处理的数据全部直接读取硬盘内的数据,所以程序可以不通过内存也可以运行。当程序或者操作者对CPU发出指令,这些指令和数据暂存在内存里,在CPU空闲时传送给CPU,cpu忙碌时内存等待cpu处理结束。CPU处理后把结果输出到输出设备上,内存虽然容量大,但是速度没有cpu速度快。数据也保存在内存里,如果内存不足,那么系统自动从硬盘上划分一部分空间作为虚拟内存来用。但写入和读取的速度跟物理内存差的很远很远,所以,在内存不足的时候,会感到机器反应很慢,硬盘一直在响
7、 归并排序
归并排序采用了分治策略(divide-and-conquer),就是将原问题分解为一些规模较小的相似子问题,然后递归解决这些子问题,最后合并其结果作为原问题的解。

归并排序中一个很重要的部分是两个已排序序列合并的过程,这里需要另外开辟一块新的空间来作为存储这两个已排序序列的临时容器。
比如将上面(a[0]=38 a[1]=49 a[2]=65 a[3]=97)和(a[4]=13 a[5]=27 a[6]=49 a[7]=76)两组数合并。
将两组数分别复制两个新的数组中b[4], c[4]中,并用原数组a[8]来存放合并后的数。
定义两个指针i, j分别指向b[0]和c[0]。再定义下标k = 0;
比较i和j指向的大小(b[0]和c[0])的大小。
若i<j,则a[k] = b[0]; i++; k++
若i>j,则a[k] = c[0]; j++; k++
8、 快速排序
基本思想是:通过一躺排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一不部分的所有数据都要小,然后再按次方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
假设要排序的数组是A[1]……A[N],首先任意选取一个数据(通常选用第一个数据)作为关键数据,然后将所有比它的数都放到它前面,所有比它大的数都放到它后面,这个过程称为一躺快速排序。
一躺快速排序的算法是:
1)、设置两个变量I、J,排序开始的时候I:=1,J:=N;
2)以第一个数组元素作为关键数据,赋值给X,即X:=A[1];
3)、从J开始向前搜索,即由后开始向前搜索(J:=J-1),找到第一个小于X的值,两者交换;
4)、从I开始向后搜索,即由前开始向后搜索(I:=I+1),找到第一个大于X的值,两者交换;
5)、重复第3、4步,直到I=J;
例如:待排序的数组A的值分别是:(初始关键数据X:=49)
A[1] A[2] A[3] A[4] A[5] A[6] A[7]:
49 38 65 97 76 13 27
第一次: 27 38 65 97 76 13 49
按照3步骤,27小于49,所以27和49交换。
第二次: 27 38 49 97 76 13 65
按照4步骤,65大于49,所以65和49交换。
第三次: 27 38 13 97 76 49 65
重复第3步,13小于49,所以13和49交换。
第四次: 27 38 13 49 76 97 65
重复第4步,97大于49,所以97和49交换。
此时重复3步骤时,发现i=j,所以这一轮快速排序结束。
结果是: 27 38 13 49 76 97 65
即所以大于49的数全部在49的后面,所以小于49的数全部在49的前面。
快速排序就是递归调用此过程——再以49为中点分割这个数据序列,分别对前面一部分和后面一部分进行同样的快速排序,从而完成全部数据序列的快速排序,最后把此数据序列变成一个有序的序列。
9、 基数排序
基数排序简单来说就是先把一组数先按个位的数字大小排序,然后再按十位的数字大小排序,依次类推。
比如: 23 6 5654 87五个数。
先建一个数组a[10][100]。因为考虑到会有某位数相同的数出现,比如546和756的个位相同,所以要用二维数组。
把个位数位0的给a[0]; 把个位位1的给a[1]……,所以结果
a0为空 a1为空 a2为空 a3有23 a4有54
a5为空 a6有6和56 a7有87 a8为空 a9为空
然后再按十位排序
a0有6(十位为0) a1为空 a2有23 a3为空 a4有46
a5 有54 a6为空 a7为空 a8有87 a9为空
所以结果出来了 6 23 46 54 87
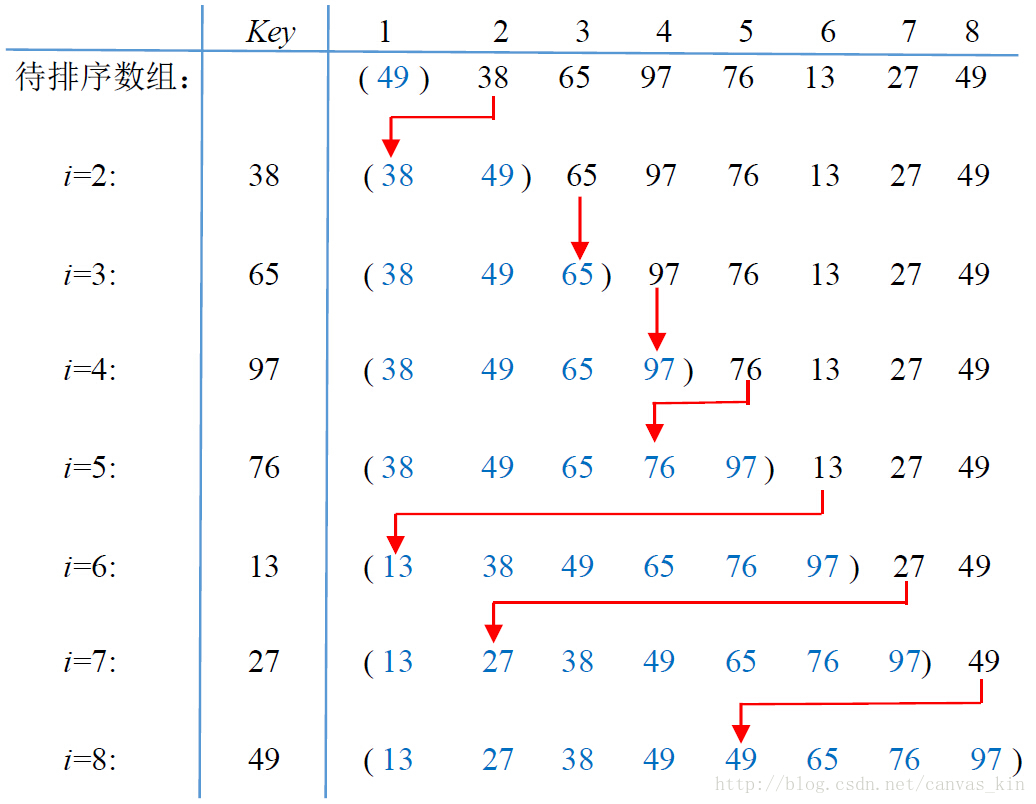
10、插入排序
插入排序的思想非常简单,给定待排序的数组A[1..n],依次对数组A的第2个到第n个元素执行插入操作。当对第j个元素(称为关键字,key)进行插入操作时,假设A[1..j-1]已经是有序序列了(前面元素的插入操作已经使之有序),则只需在A[1..j-1]中从后往前搜索,找到第一个小于等于A[j]的元素,将A[j]插入到这个元素后面即可。具体排序过程如下图所示: