首先讲一个概念—-内存对齐
一种提高内存访问速度的策略,cpu在访问未对其的内存需要经过两次内存访问,而经过内存对齐一次就可以了。(?)
打个比方就是:操作系统在访问内存时,每次读取一定的长度(这个长度是系统默认的对其系数),程序中你也可以自己设定对齐系数,告诉编译器你想怎么对齐,可用#pargam pack(n),指定n为对其系数。但是当没有了内存对齐,cpu在访问一个变量时候,可能会访问两次,为什么呢?
32位cpu一次能最多处理的信息是32bit位,如果你没有指定对齐,我们假设这样的数据结构在内存中存在的情况,这也是我们后面要讨论的结构
对应的在内存中存放的方式可能是这样(假定32位下):
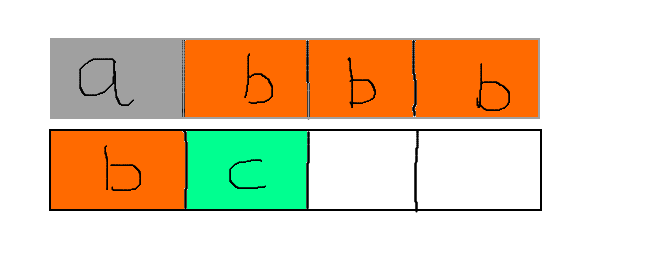
那么,这样一来,取得这个int型变量需要经过两次的寻址,拼凑成一个完整的4字节的数。这个过程还涉及到cpu指令集调用和总线的读写操作,如果真是没有对齐的话,效率会差到不知道哪儿去了。
所以这个内存对齐是必须遵守的,为了提高cpu访问效率和速度。
继续引入另外一个概念:内存的自然对齐:每一种数据类型都必须放在地址中的整数倍上
举个例子如下:
地址4可以放char(1)类型,可以放int(4)型,可以放short(2)型,但是不能存放double(8)型,仅仅因为4不是8的整数倍。
地址3能存放char型,但是其他int,short,double都不能存放。
有一个特殊地址,就是0,它可以是任何类型的整数倍,所以可以存放任何数据。
根据这个规则,那么在分配一大块包含很多变量的内存的时候,会产生很多碎片,具体到下面分析
接下来,我们对这个结构体来进行一个分析:
#include<stdio.h>
#include<stdlib.h>
typedef strutc test{
char a;
int b;
double c;
char d;
}
int main(void)
{
STU s;
printf("s的大小是 = %d\n",(int)sizeof(STU));
printf("s中a的起始地址是 %p\n",&(s.a));
printf("s中b的起始地址是 %p\n",&(s.b));
printf("s中c的起始地址是 %p\n",&(s.c));
printf("s中d的起始地址是 %p\n",&(s.d));
return 0;
}
/*64位下
s的大小是 = 24
s中a的起始地址是 0x7ffd01319d10
s中b的起始地址是 0x7ffd01319d14
s中c的起始地址是 0x7ffd01319d18
s中d的起始地址是 0x7ffd01319d20
*/依照简单的4字节对齐(gcc默认是4字节对齐),首先的char在0上(其实也就是某个4的整数倍数上),之后int b在地址4上,一直延续到8,double c就在地址8上,之后sizeof必须是8的整数倍,之前是4+4+8 == 16,那这个char就只能存入一个8大小的内存中了,也就是4+4+8+8 == 24
为什么这么算呢?
开始的可以根据内存的自然对齐求得,最后的char补7个空白是因为结构体的总大小,必须要是其内部最大成员的整数倍,不足的要补齐,像这里就是double 8个字节的整数倍,所以给最后的d补上了7个空白空间。这也是内存分配的3个原则之一。
关于内存分配的其他两个规则如下:
1.结构体或union联合的数据成员,第一个数据成员是要放在offset == 0的地方,如果遇上子成员,要根据子成员的类型存放在对应的整数倍的地址上
2.如果结构体作为成员,则要找到这个结构体中的最大元素,然后从这个最大成员的整数倍地址开始存储(strutc a中有一个struct b,b里面有char,int,double….那b应该从8的整数倍开始存储)
还需要注意一点:
typedef struct stu{
char a;
int b;
char ex;
double c;
char d;
}STU;
printf("STU的大小是 = %d\n",(int)sizeof(STU));
/*32位输出
STU的大小是 = 24
*/
/*64位输出
STU的大小是 = 32
*/计算一下出来的结果和输出是否正确:
32位:a( 4 )+b( 4 )+ex( 4 )+c( 4+4 )+d( 4 ) == 24
64位:a( 4 )+b( 4 )+ex( 8 )+c( 8 )+d( 8 ) == 32
而为什么会出现这样的结果呢?准确一点为什么32位中的double变成了2个4字节而不是一个8?
这需要结合之前说的内存的自然对齐,我们知道char遇到int型,产生3个空白,遇上double要产生7个空白。而这里32位中的char遇上double却只是产生了3个空白,是因为32位限制了一次只能读入4个字节数据处理,也就是说8字节的double被分成了2个4字节字符被处理,也可以说死了,32位平台下就定死了4字节对齐(当然你可以设定更小,但是没什么意义),接着说结构体,那结构体中最大的数就是4字节的了,sizeof(STU)也只需要遵守是4的整数倍即可。最后得到24字节。
64位就按正常的计算。
最后贴上这一段代码,是下面参考博文中某个作者总结的一段,只要能看懂这段代码就大抵上全部理解3个内存对其和分配原则了
typedef struct bb
{
int id; //[0]....[3]
double weight; //[8].....[15] 原则1
float height; //[16]..[19],总长要为8的整数倍,补齐[20]...[23] 原则3
}BB;
typedef struct aa
{
char name[2]; //[0],[1]
int id; //[4]...[7] 原则1
double score; //[8]....[15]
short grade; //[16],[17]
BB b; //[24]......[47] 原则2
}AA;
int main()
{
AA a;
cout<<sizeof(a)<<" "<<sizeof(BB)<<endl;
return 0;
}
/*输出
48 24
*/总结
内存对齐的目的和好处
内存自然对其的概念
内存对齐(分配)的3个原则
有什么错误还请指出
参考博文链接:
http://blog.csdn.net/hairetz/article/details/4084088
http://blog.csdn.net/msdnwolaile/article/details/50158463
http://www.cnblogs.com/xudong-bupt/archive/2013/05/13/3076024.html
http://blog.csdn.net/Ropyn/article/details/6568780