聊天记录分析算是自己一开始入门R接触的小案例,恰好有一个机会替一个神秘组织开八了聊天秘密,一些人留言想知道里面一些图表如何绘制,所以自己动起了写教程的念头。网上这类的资料有很多,但是自己也有一些新想法就写下来了。这是后续篇[聊天记录分析(二)]
这是用分析的结果写的群成员招募文章
(http://blog.csdn.net/qq_29737811/article/details/77248551)
开八!神秘数据组织里不得不说的小秘密
我们爬了这个神秘组织的聊天记录,发现惊天秘密!
这还有下篇:R || 聊天记录分析(二)
一、如何获取群聊天数据?
||微信群
安卓系统:需要root权限
苹果系统:可以下载同步助手
人工采集:长按信息发送到邮箱(简单粗暴但好用!)
人工收集到数据格式见下图:

(以上,请百度)
||QQ群
直接在QQ中的消息管理器中选择群导出全部聊天信息即可。
二、数据预处理(微信群信息)
(1)由于读取txt文档数据以读取 “\n “为一行数据,所以人工收集的数据中日期应与下一条信息空一行,并且文本最后一行必须是日期。
(2)提取用户名、时间、日期、聊天信息。
利用scan()函数导入文本数据,并将文本转换为向量;利用正则表达式识别并标记每行记录的时间和日期;提取聊天数据中的用户名以及对应的日期和时间
#导入文本数据
filedata <- scan(file = "message.txt",what = "",sep = "\n",encoding = "UTF-8")
#定义数据框和变量
data <- data.frame(user_name = c(),date = c(),date = c())
date <- vector(length=length(filedata))
time <- vector(length=length(filedata))
user_name <- vector(length=length(filedata))
text <- vector(length=length(filedata))
#截取用户名、时间和日期
pat1 = '[0-9]{4}-[0-9]{2}-[0-9]{2}' #表示日期的正则表达式
pat2 = '[0-9]+:[0-9]+' #表示时间的正则表达式
for(i in 1: length(filedata)){
dt_pattern1 <- grepl(pat1,filedata[i]) #grepl函数识别每条记录中的日期部分
dt_pattern2 <- grepl(pat2,filedata[i]) #grepl函数识别每条记录中的时间部分
if(dt_pattern1 == TRUE){
date[i] <- substr(filedata[i],nchar(filedata[i])-16,nchar(filedata[i])-6)
}
if(dt_pattern2 == TRUE){
time[i] <- substr(filedata[i],nchar(filedata[i])-4,nchar(filedata[i]))
user_name[i] <- substr(filedata[i],1,nchar(filedata[i])-nchar(time[i])-1)
}
}
data <- rbind(data, data.frame(Name = user_name,date = date,time = time))可以使用head(data)来看一下此时的数据框,可以看到此时数据框还缺少聊天内容,并且日期与用户名不对应。将两个用户名之间的内容作为前一个用户名的聊天内容;删除无用户名的行记录,并随后将字符串格式的日期转换为日期格式,还可以计算每条聊天记录的字符数等。
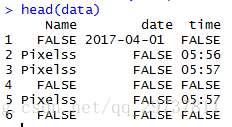
#-- 缺失的日期可以按照前一个日期补齐
datenum <- which(data$date != FALSE)
for(i in 1:length(filedata)){
for(j in 2:length(datenum)){
if( i > datenum[j-1] & i < datenum[j]){
data$date[i] = data$date[datenum[j-1]]
}
}
}
#获取每个用户的发言内容
namenum <- which(data$Name != FALSE)
length = length(namenum)-1
for(i in 1:length(filedata)){
for(j in 1:length){
if(i == namenum[j] & i+1 != namenum[j+1]){
k=i+1
p <- namenum[j+1]-1
for(t in 1:length(datenum)){
if(p == datenum[t]){
p=p-1
}
}
text[i] <- paste(filedata[k:p],collapse = " ")
}
}
}
text[namenum[length(namenum)]] <- paste(filedata[(namenum[length(namenum)]+1):(length(filedata)-1)],collapse = " ")
data <- transform(data,text = text)
data$text <- as.character(data$text)
data <- data[data$Name != FALSE,]
which(data$day %in% NA) #可以用来检查是否有错误
#将字符串转换为日期格式,还可以计算每条聊天记录的字符数
#取出时间戳 的年、月、日、时、分、秒部分
datetime <- paste(data$date,data$time)
datetime <- strptime(datetime,format="%Y-%m-%d %H:%M") #-- 将字符串转换为日期格式
data <- transform(data,year = datetime$year + 1900,
month = datetime$mon + 1,
day = datetime$mday,
hour = datetime$hour,
min = datetime$min)
textnum <- c() #-- 计算每条聊天记录的字符数
for(i in 1 : length(data[,1])){
textnum[i] <- nchar(data$text[i])
}
data <- transform(data,textnum =textnum)
此时数据框为:

因为手动收集的数据存储在txt文件中无法显示图片,故聊天数据中有一些缺失值,这里显示为FALSE,可以修改为NA,但这对后续分析无影响,所以我未做处理。
三、数据分析
首先可以用sql语句做一些简单的分析,并绘制一些图表
(1)统计每月每天总的聊天频数
library(sqldf)
FreByDay <- sqldf('select month,day,count(*) Freq from data group by month,day')
#绘制聊天热度图,每月每天总的聊天频数
library(ggplot2)
p1 <- ggplot(data = FreByDay,mapping = aes(x = factor(day),
y = factor(month),fill = Freq))+xlab("day") + ylab("month")
p1 <- p1 + geom_tile() + scale_fill_gradient(low = 'grey',high = 'red') +
theme(axis.text.x = element_text(size = 8,face ="bold",colour = "grey"),
axis.text.y = element_text(size = 12,face ="bold",colour = "grey"),
axis.title.x = element_text(size = 15,face ="bold",colour = "black"),
axis.title.y = element_text(size = 15,face ="bold",colour = "black"),
axis.line=element_line(colour="black"),
panel.grid.major = element_line(colour = NA),
panel.grid.minor = element_line(colour = NA),
panel.border = element_blank())
p1
可以根据聊天频率绘制热度图:
(2)统计每个用户的聊天频次,可以挑出发言量前12的群员;统计全员不同时间段的活跃度。
###统计每个用户的聊天频次,挑出发言量前12的群员
df <- as.data.frame(table(name=data$Name))
top <- df[order(df$Freq, decreasing = TRUE),]
top12 <- df[order(df$Freq, decreasing = TRUE),][1:12,]#这里挑出发言量前12的群员
newtop12 <- top12
#“话痨们“的活跃时间段 #这群活跃的人都喜欢什么时候发言
top12bytime <- sqldf('select Name,hour,count(*) Freq from data where Name in
(select name from newtop12) group by Name, hour')
#全员不同时间段的活跃度,分一天24小时,一周七天的情况
MesPerHour <- as.data.frame(table(data$hour))
names(MesPerHour)[1] <-c("Hour")
date <- as.POSIXlt(data$date)
week <- weekdays(date)
data <- transform(data,week = week)#-- 新增一个变量【星期】#weekdays()可以计算当天是星期几
MesPerWeek <- as.data.frame(table(data$week))
names(MesPerWeek)[1] <- c("week")
MesPerWeek$week = factor(MesPerWeek$week,levels = c("星期一","星期二","星期三","星期四","星期五","星期六","星期日"))
#-- R中排序按照拼音来,故需要对中文星期自定义排序
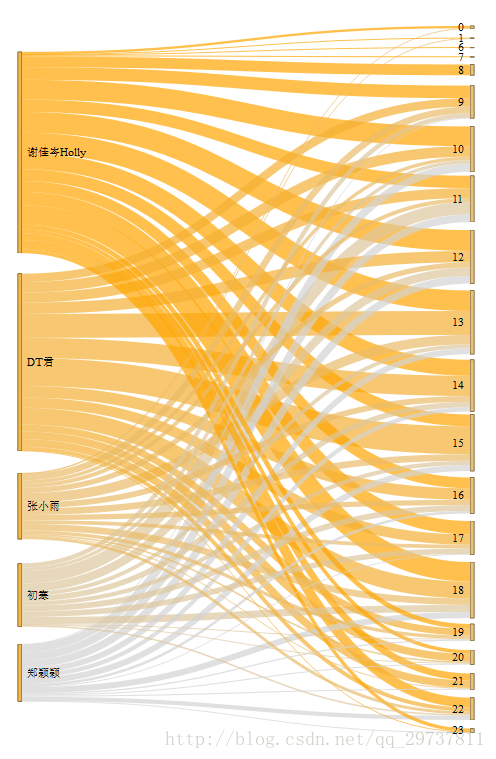
根据得出的数据可以绘制一些条形图、折线图、这些比较简单就不展示,下面展示一下桑基图如何绘制。
library(networkD3)
library(RColorBrewer) #设置颜色的包
colors <- colorRampPalette(c("orange", "lightgray"))(length(unique(edges$name)))
domain <- unique(edges$name)
color_scale <- data.frame(colors = colors,domain = domain,stringsAsFactors = FALSE) # 需给出每条边对应的颜色
sankey <- sankeyNetwork(Links = edges, Nodes = node_name, Source = "source",
Target = "target", Value = "Freq", NodeID = "name",
LinkGroup = "group",NodeGroup = "nodegroup",
height=600,width=400,colourScale = JS(
sprintf(
'd3.scaleOrdinal().domain(%s).range(%s)', jsonlite::toJSON(color_scale$domain),
jsonlite::toJSON(color_scale$colors) #每条边对应的颜色
)
),
fontSize = 11, nodeWidth = 4)
sankey
得到的桑基图如下:
(3)统计谁发的表情包最多
#谁是表情帝,
#-- 手动采集的数据中,所有的表情包显示为[表情],且不包括自带的小黄脸表情
emot <- c()
for(i in 1:length(data[,1])){
t <- enc2utf8(data$text[i])
c <- grepl("[表情]",t)
emot[i] <- as.numeric(c)
}
myvars3 <- c("Name")
emotdata <- data[myvars3] #生成新的数据集
emotdata <- transform(emotdata,emot = emot)
emotdata_Name <- sqldf('select Name,sum(emot) as Fre from emotdata group by Name')
emotdata_Name <- emotdata_Name[order(emotdata_Name$Fre, decreasing = TRUE),](4)分析群聊天的话题——词云分析
#Rwordseg分词
library(rJava) #安装rJava需要java环境,如果未安装java环境需提前安装
library(Rwordseg) #需要另外下载,并且该包需要用到rJava
#分析群聊天的话题——词云分析
message <- as.character(data$text)
message <- enc2utf8(message) #转utf-8
message <- message[Encoding(message) != 'unknown'] #-- 删除无法识别的字符
insertWords(c("捂脸","DT君","Dt君","dt君","设计师小哥哥","小黄车","应用消息","ofo"),save = TRUE)
deleteWords(c("共享单车","大数据"),save=TRUE) #-- 如何不想要“共享单车”这个词频,则它被拆分成共享 和 单车
word.message <- segmentCN(message) #-- 将每条聊天记录进行分词
stop_words = readLines('ChineseStopWord.txt') #-- 停词可百度下载
target_words <- unlist(word.message) #-- 将列表转换为向量
seg_word = target_words[which(is.element(target_words,stop_words) == FALSE)]#删除停用词
#-- 可以自行删掉一些无用的词汇
seg_word = gsub(pattern = "[NA]","",seg_word)
seg_word = gsub(pattern = "[捂]","",seg_word)
#-- 分词结束,现在开始统计词频
library(dplyr) # %>% 等管道函数需要用dplyr包
WordFreq = as.data.frame(table(unlist(seg_word))) %>% arrange(desc(Freq))
WordCloud <- wordcloud2(WordFreq,shape = "round",minSize = 5,color = 'random-light')
WordCloud(5)每七天的新旧面孔的比例。
(也就是统计这周的发言人中有多少是上周也发言的)首先给出时间节点,如以5月1日为起点,每七天为一周,统计每周的发言人,与上周进行比较,统计新出现的发言人的数量。而新面孔定义为在第二个时间段内发言而在上个时间段未发言的人。
#每七天的新旧面孔比例,绘制堆积直方图
x <- data[day,2] #-- 横坐标为每七天的时间节点
user <- data.frame(x=x,namesum=namesum,new=new)
old <- user[,2]-user[,3]
user$old <- old
meltuser <- melt(user[,-2],id="x") #melt()函数
p6 <- ggplot(meltuser,aes(x,value,fill=variable))+
geom_bar(stat="identity")+
theme( axis.title.x=element_blank(),
axis.title.y=element_blank(),
legend.position="none")
p6四、参考资料
http://mp.weixin.qq.com/s/BJVt0joD11isdCxD-EZzHw
http://blog.sina.com.cn/s/blog_ec9e85e20102vwl7.html
https://zhuanlan.zhihu.com/p/25171755
http://blog.csdn.net/csqazwsxedc/article/details/52118977
http://www.jianshu.com/p/9f1166916960