字典树(trie)这个东西真的是特别好理解,先看一下它的模板题吧:
有n个单词,一个句子,问在句子中有多少个单词出现过。
字典树,顾名思义,肯定查询功能特别发达,那么它具体怎么实现呢,在字典树中,有一个root节点,也就是整棵树的根,字典树的每一个节点(包括root)都向下连出了26条边,也就是对应的26个字母(注意!字典树中字母是记录在边上的),但每一条边下不一定都有儿子,于是,对于这道例题,可以将所有单词建一棵字典树,在每一个节点上多设置一个end变量,表示以这个节点与它父亲之间的边上的字母作为最后一个字母的单词的数量,换一种说法就是能以root到这个节点的路径上的所有字母按顺序组合成的单词数量,虽然end的意思我琢磨了很久,但我觉得还是没解释清楚啊。。那我用一幅图来解释吧
假如给出以下单词
love
lol
loop
apple
app
air
那么构建出来的字典树就是这样的(红字为end的值):
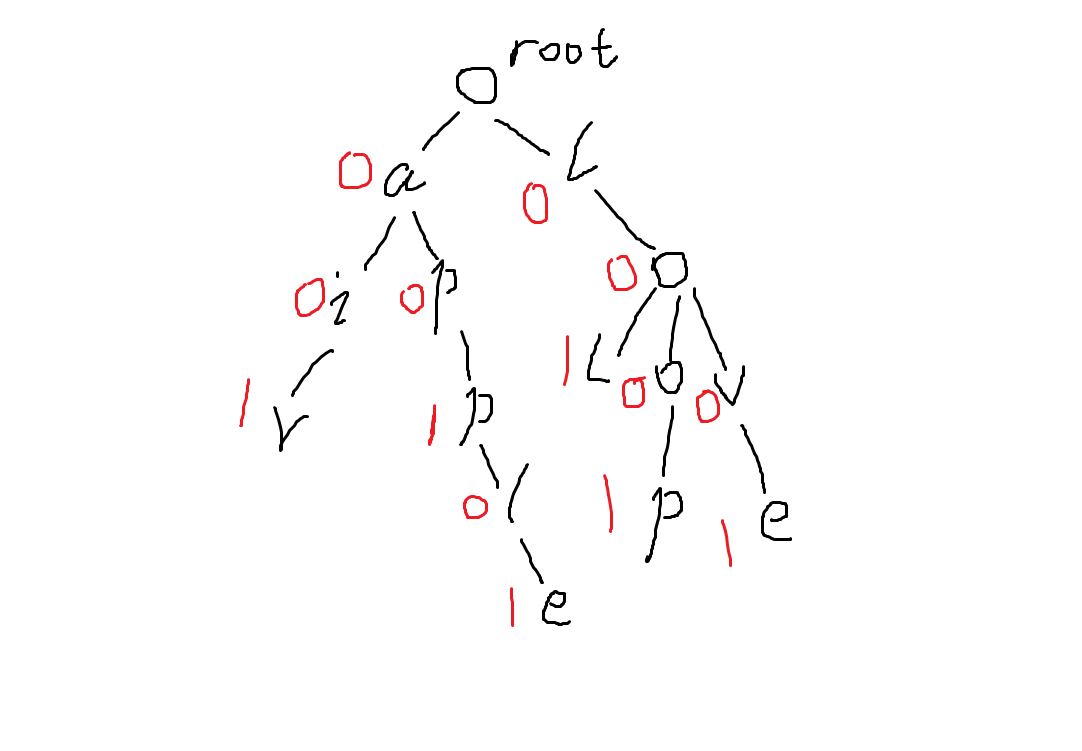
这样总明白了吧。。。
为什么我要如此强调end这个东西呢,因为有关字典树的题一般都会用到它,那么,查询就很简单了,每次将一个单词与这颗字典树匹配一次,字典树先从root开始,单词s先从第1个字母开始,看root是否有s[1]这个儿子,有就往下走,一旦出现没有的情况,说明匹配失败,那接下来看代码吧(代码可能有误,欢迎指正。。):
#include <cstdio>
#include <cstring>
struct node{int son[27],end;};
node tree[100010];//字典树
int n,len=1;//len记录树中节点数量
int ch(char x){return x-'a'+1;}//将a~z转成1~26来存
char chb(int x){return x+'a'-1;}
void build(char ss[],int y)//构造字典树
{
int now=0;
for(int i=0;i<y;i++)
{
if(tree[now].son[ch(ss[i])]!=-1)now=tree[now].son[ch(ss[i])];//如果有ss[i]这个儿子,就继续往下走
else//否则新建一个儿子
{
len++;
tree[len].end=0;
tree[now].son[ch(ss[i])]=len;
now=len;
}
}
tree[now].end++;//表示以此结尾的单词数量+1
}
char w[10010];//文本串
int main()
{
scanf("%d",&n);
memset(tree[0].son,-1,sizeof(tree[0].son));//初始化root节点
tree[0].end=0;
for(int i=1;i<=n;i++)
{
char s[1010];
scanf("%s",s);
build(s,strlen(s));
}
int ans=0;
getchar();
gets(w);
int m=strlen(w);
for(int i=0;i<m;i++)
{
if(w[i]>='a'&&w[i]<='z')//假如遇到了单词
{
int now=0;
while(tree[now].son[ch(w[i])]!=-1)//假如有这个儿子
{
now=tree[now].son[ch(w[i])];i++;//往下走
if(tree[now].end!=0&&(w[i]==' '||i==m))//假如发现了一个单词
{
ans+=tree[now].end;
tree[now].end=0;
}
if(i==m||w[i]<'a'||w[i]>'z')break;
}
while(w[i]>='a'&&w[i]<='z')i++;//如果前面匹配失败了,那么后面连着的字母也没用了
}
}
printf("%d",ans);
}
/*测试数据
5
love
lol
like
hot
hole
dog like hot hole and love hot dog,lollll
ans=4
*/