AI有三大驱动因素:算法,算力,数据
近年来,由于深度学习的兴起,计算机各种顶会都渐渐被深度学习算法给攻占。计算机结构顶会也不例外,很大一部分论文都是有关AI计算的研究。
在今年世界级的计算机结构顶会ISCA中,共收录68篇paper,中国只有一篇一作。来自清华大学的魏少军教授团队。论文标题如下:
《RANA: Towards Efficient Neural Acceleration with Refresh-Optimized Embedded DRAM》
先以微电子背景介绍一下目前深度神经网络计算的一个困境,适用于各大公司(TPU,寒武纪,地平线,深鉴,华为等)的深度学习处理器:
以视觉任务(visual tasks)为例,任务越来越复杂,精度要求越来越高。这直接导致DNN模型非常庞大,就VGG网络来说,能够做ImageNet千分类,取多种精度(8b,12b等),模型参数也能达到500Mb;再比如做20类Object detection的YOLO_small网络的参数都可以达到300Mb。对于一般DNN处理器来说,要处理这种视觉任务,该怎么做呢?
根据散热,时钟频率等限制,芯片chip面积不能做得很大。理论上限制了500M这种存储体不能放在onchip。所以,参数需要放在片外memory上,片上小memory当缓存用,这样就以flow的形式实现大模型的AI计算。
这样做呢,有若干缺点:
首先,从片外拿数据是一个耗时耗力(功耗高)的操作,即使现在有比较好的通信(协议PCIe或者Nvlink等)。
其次,没有更好的利用非冯结构数字电路的并行性。这个并行性,怎么理解呢,就这么说吧,如果不考虑芯片面积和存储开销以及物理限制,理论上可以通过一个时钟周期计算整个CNN的inference操作,你怕不怕?
AI芯片的目的,无非就是加速计算。
所以很多研究就在想提高片上memory的容量。清华涂峰斌师兄的团队在ISCA2018的论文,就成为了提高片上memory的典范。
用eDRAM代替SRAM成为片上memory
eDRAM就是嵌入式DRAM,DRAM的物理结构是单管加电容模式,如下图:
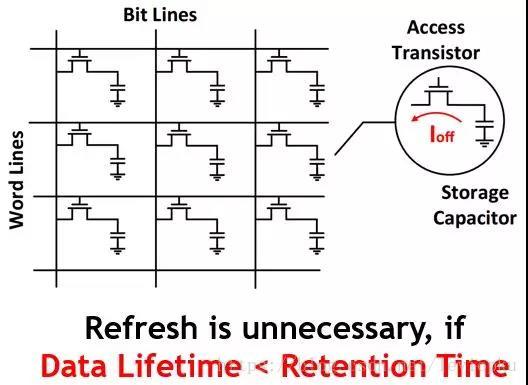
一个MOS管加一个电容就能存储1bit数据。利用电容充放电机制,MOS负责开关。
而SRAM通常是六管后者八管来存储一个bit,SRAM的示意图如下:
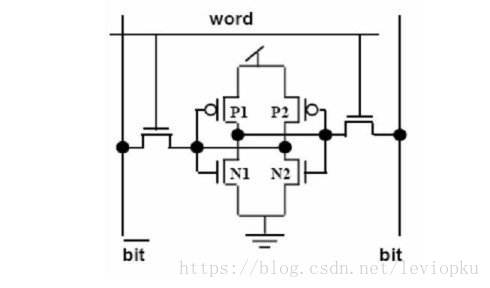
一个电容的体积相对一个MOS管的体积,可以说是忽略不计。所以DRAM在体积上有非常大的优势。
那为什么一般的AI芯片用的内部memory还是SRAM呢
因为DRAM容易掉电,需要定期刷新。
要用DRAM还要解决DRAM的缺点,这就是RANA框架的创新之处。
数据生存时间感知的神经网络加速框架(RANA)。框架采用 eDRAM 作为片上存储器,相比于传统 SRAM 具有更高的存储密度,大幅减少片外访存。同时,RANA 框架采用三个层次的技术:数据生存时间感知的训练方法,神经网络分层的混合计算模式和刷新优化的 eDRAM 控制器,分别从训练、调度和架构三个层面降低 eDRAM 刷新能耗,进而大幅优化整体系统能耗。
从多层面设计来解决一个问题:让数据生存时间小于DRAM刷新时间
在DRAM需要刷新之前,数据就已经用完了。这样一来,就可以不用刷新DRAM了。将刷新功耗降低了99%。
这也是软硬件协同优化的一个例子。事实上,单独优化硬件或者单独优化软件都是无法把系统做到最优,最好的系统一定是软硬件协同优化!