这次博客我们主要讨论机器学习系统设计的主要问题,以及怎样巧妙的构建一个复杂的机器学习系统。
我们先用一个例子引入机器学习系统的设计:
以一个垃圾邮件分类器算法为例:

对于该问题,我们首先要做的是怎样选择并且表达特征向量x。我们可以选择100个词所构成的列表(这个词不仅包括垃圾邮件里面的词同时还包括非垃圾邮件里面的词,我们这里是手动选择的100个词,而在真正的算法中我们一般选择出现频率最高的10000~50000个词),这些词在邮件中出现标为1,不出现标为0,所以我们构建好了特征向量,尺寸为100*1。
例如上述我们选择的词包括:deal、buy、discount、andrew,now等词汇,则对于左图我们构建的特征向量为x=[1;1;0;0;1;…]。
上述构建算法的过程中,我们会有很多问题去考虑,比如:
1. 收集更多的数据,获取更多的垃圾邮件和非垃圾邮件;
2. 基于邮件的路径信息开发出更加复杂的特征;
3. 基于邮件的正文信息开发出更加复杂的特征;
4. 为探测可以的拼写错误开发成复杂的特征。
考虑了上述这些问题之后,我们仍然面对一个难题,那就是如何系统的从上述考虑的问题选择其中的一个或者多个,使得算法的性能得到提升,我们在下面会进行详细的讨论。
误差分析以及构建学习系统的一般方法:
误差分析我们在前面的博客中已经讲述过,它主要包括训练集误差、交叉验证集误差、测试集误差以及学习曲线等误差分析的方法。它可以衡量一个学习系统性能的好坏,同时促进你对该学习系统的改进。
我们设计机器学习系统的一般流程为:
1. 从一个简单的能快速实现的算法开始,实现该算法并用交叉验证集数据测试这个算法
2. 绘制学习曲线(可以通过分析训练集误差和交叉验证集误差,判断该算法处于过拟合阶段还是欠拟合阶段),决定是增加更多数据(过拟合阶段),或者添加更多特征(欠拟合阶段)
3. 进行误差分析:人工检查交叉验证集中我们算法中产生预测误差的实例,看看这些实例是否有某种系统化的趋势(比如某种词汇很容易错分等),确定了系统化的趋势之后,改进分类器(比如加入某些缺少的特征等)
我们简答解释一下为什么这样构建学习系统:
1.为什么从一些简单的能快速实现的算法开始?在我们设计机器学习系统时,刚开始确定使用哪些复杂的特征时很困难的,所以我们可以先采用一些简单的比较明显的特征构建系统;
2.为什么绘制学习曲线?从上面步骤构建的系统肯定性能不是很高(仅仅采用了一些比较明显的特征),我们可以绘制出学习曲线,判断上述构建的分类器是处于过拟合阶段还是欠拟合阶段,并针对所处的阶段进行相应的处理(过拟合阶段,收集更多的训练样本,欠拟合阶段,去补充更多特征);
3.为什么进行误差分析:通过上述构建的系统,分析一下误差产生的来源,对预测错误的实例进行分析,同时观察是否具有某些规律,然后对显示出来的规律进行进一步的改进,使得算法的性能进一步提高。
为了量化改进前后的性能的改变,我们可以使用交叉验证错误率来衡量,可以直观的帮助我们判断对算法进行修改前后性能的变化。
其中,
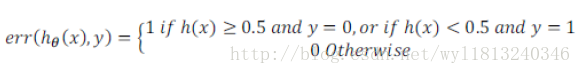
误差分析也不是总能帮助我们判断采取什么行动,有时候也需要我们尝试不同的模型,也就是我们前面讲述的将数据集划分为训练集、交叉验证集和测试集,从不同的模型中选择最优的模型,具体实现的过程可以参考这篇博客
类偏斜的误差度量:
上述我们讲述了误差分析以及误差度量值,来帮助选择模型以及改进学习系统,其中选择合适的度量值是至关重要的,下面我们来讨论偏斜类问题以及该问题合适的误差度量。
所谓的偏斜类问题也就是对于我们的数据集中,某一类占据绝对的主导地位,而其他类别占据很少的一部分。比如我们前面讨论的肿瘤问题,数据集中绝大多数都是良性肿瘤(约占99.5%),只有很少一部分是恶性肿瘤(约占0.5%)。
如果对上述问题采用分类精度作为度量,我们在进行学习之后得到一个很好的模型,它正确划分的精度为1%;而如果我们不进行训练,将所有的样本均判断为良性的,分类精度可以达到0.5%,从上述可以看出,针对偏斜类问题,用分类精度作为误差的度量,存在着问题,明显训练得到的1%的误差比不训练得到的0.5%更能代表这个数据集。
所以我们使用另一种误差度量的方法:查准率(Precision)和查全率(Recall,也叫召回率),我们先将预测的结果分为四种情况,然后给出查准率和查全率的表达式:
1. 正确肯定(True Positive, TP): 预测为真,实际为真;
2. 正确否定(True Negative, TN): 预测为假,实际为假;
3. 错误肯定(False Positive, FP): 预测为真,实际为假;
4. 错误否定(False Negative, FN): 预测为假,实际为真
查准率P:
它表示的是在所有预测为恶心肿瘤的样本中,实际真正患有恶性肿瘤的百分比,对于训练的模型来说,P越高训练的模型越好。
查全率R:
它表示的是所有实际真正患有恶性肿瘤的样本中,预测为恶性肿瘤的百分比,对于训练的模型来说,R越高训练的模型越好。
值得注意的是,对于在查准率和查全率的定义中,我们习惯将少量的类用标签1表示。
例如我们上述的情况,将所有的样本全部判别为良性,由于TP=0,同时
查全率和查准率的权衡:
上述我们谈论了查准率和查全率,在很多应用中我们希望查全率和查准率达到相对平衡。
还是以肿瘤预测为例,进行下一步的探讨。假设我们的算法输出的结果在0~1之间,我们使用阈值0.5来预测真假。
如果我们想要更高的查准率,即在非常确信的情况下才判断为恶性肿瘤,我们可以将上述的阈值调高,可以将阈值设置为比0.5大的数值,比如0.7、0.9等,这样做可以减少错误判断为恶性肿瘤的情况,但是同时也会增加未能成功预测肿瘤为恶性的情况,即FP降低,FN增加。
如果我们想要更高的查全率,即尽可能的让所有可能是恶性肿瘤的病人得到进一步的检查,我们可以将阈值设置小于0.5,比如0.3等,这样做会减少错误将恶性肿瘤判断为良性的情况,但是同时增加了实际为良性肿瘤,却判断为恶性肿瘤的情况,即FN增加,FP降低。
为了权衡查全率和查准率,我们绘制出在不同阈值下的查全率和查准率曲线,曲线的形状会根据数据的不同而不同:
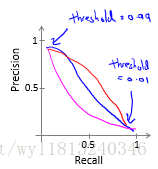
上述三条曲线都是查准率和查全率曲线,具体是哪一条取决于数据。
为了找到一个最佳的查全率和查准率的折中,我们一般通过计算F1值(F1 Score)确定,计算公式为:
我们在不同阈值下,分别计算出P和R,进而计算出F1的值,找到一个最大的F1值(F1值越大,表示该模型越好),即为最优的查全率和查准率的折中,同时对应的阈值为最优的阈值。
我们在极端情况下,看看F1值是否适用:
1. 当P和R很小时,即说明模型的性能不是很好,此时的F1值为0,表示性能不好,所以F1值可以适用于该种情况;
2. 当P和R的值均为1时,说明此时的模型性能很好,此时的F1值为1,表示性能很好,所以F1值同样适用于这种情况。
机器学习的数据:
下面我们来讨论一下机器学习系统设计的另一个内容:用于训练的数据有多少。
一般我们认为得到大量的数据并在某种类型的学习算法中进行训练,可以是一种有效的获得一个具有良好性能的学习算法。而这种情况往往出现在这些条件对于你的问题都成立,并且拥有大量数据的情况下。我们下面对于这些条件进行讨论。
大量数据获得好性能的基本原理:
1. 要求特征值x包含足够多的信息,这些信息可以帮助我们用来准确的预测y,这种模型保证了该算法是低偏差(多种特征)模型,防止了欠拟合,它能够拟合出非常复杂的函数,使得训练误差很小。
2. 同时要求大量的训练数据,训练数据大于参数的数量(防止产生过拟合过拟合),保证较低的方差,使得训练集的损失函数与测试集的损失函数大致相等,又通过上述步骤1,使得训练集的损失函数和测试集的损失函数都很小。

步骤一防止欠拟合,保证了较低的偏差,步骤二防止过拟合,保证了较低的方差,通过上述两个步骤就构建出了性能很好的机器学习算法。