下面是关于在使用SQL时,我们尽量应该遵守的规则,这样可以避免写出执行效率低的SQL
1、当只需要一条数据时,使用limit 1
在我们执行查询时,如果添加了 Limit 1,那么在查询的时候,在筛选到一条数据时就会停止继续查询,但是如果没有添加limit 1即使只有一条数据,也会尝试去查询下一条满足条件的数据。
2、对于搜索的字段创建索引
如果当前数据量很大的情况下,需要根据一定的条件进行筛选,对筛选列添加索引,但是一个表当中的索引不建议过多,对于索引的创建规则以及哪些情况下索引失效,可以参照 MySQL索引相关内容汇总
3、是进行join时,尽量使用索引列进行join
如果两张表或者多张表进行关联,确保进行join关联的列类型相同,并且分别是索引列。
4、尽量为每张表都添加一个ID
数据库当中尽量设置主键或者说是一个ID,主键的话,其类型最好是int类型。
5、对于区分度比较低的列,可以使用Enum来代替Varchar
如果这个列只有几种情况的,比如性别,比如文章类型等,这些区分度很低,我们尽量使用枚举类型来代替Varchar, 枚举类型保存的是tinyint,但是对外显示的字符串。

6、垂直分割
对于一些存储比较大的列,并且不需要直接访问的,可以进行垂直分割,比如对于文章或者新闻的信息存储,我们只需要把文章的基本信息,比如标题,作者,创建日期,类型等基础信息存放在一张表中,文章内容存放在另外一张表中,这样查询时,在用到的时候再查询。
7、对于limit分页的优化
比如我们直接写分页查询select * from tbl limit 100000,10 这个查询时间很长,如果我们设置id为主键,然后在查询时只查询主键 select id from tbl limit 100000 , 10 ,这条语句就比上条节省了大量的时间,但是我们需要的是整张表的数据,
接着优化改为:select * from tbl where id >= (select id from tbl limit 100000,1) limit 20
这个时候如果我们需要添加一个筛选条件,比如type=1, 在原有的基础上面,
select id, title from tbl where type = 1 order by id limit 1000000,10 对这条语句,发现在数据量上百万的时候,执行速度很慢,原因在于where条件当中使用了非索引的列,导致进行了全表扫描
这个时候我们可以考虑创建组合索引(type,id)将where条件中的列放在第一位,limit当中的主键放在第二位,进行查询,同时只查询id,速度会非常快。
分库分表
分库其实就是将原来一个数据库当中的数据,分到多个数据库当中,分表就是将原来一个表当中的数据拆分成两个表存储。
垂直切分
将数据库当中的不同模块的数据表放在不同的数据库上,比如人员管理模块(member , role, user等),商品管理模块(product, number, baseInfo等),将不同模块的表放在不同的数据库上面,这样其中一个模块式数据库出问题了,也不会影响其他模块的使用。
水平切分
比如当我们用户注册数量已经达到千万时,这个时候,就需要把User表进行一个水平切分,分别创建user1和user2,这两张表的结构完全相同,同时创建一个存储引擎为Merge的allUser表,用户在查询时,通过allUser表来查询,具体的数据分别存储在user1和user2表当中。
MySQL水平分片
将不同每个模块的数据分配在不同的数据库上面,同时每个模块的数据进行水平切分,也保存在不同的数据库上
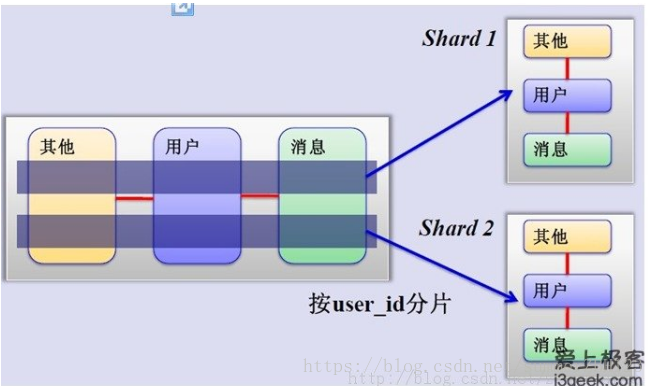
这样做的好处就是当在有新的数据进来时,只需要配置一台服务器即可。