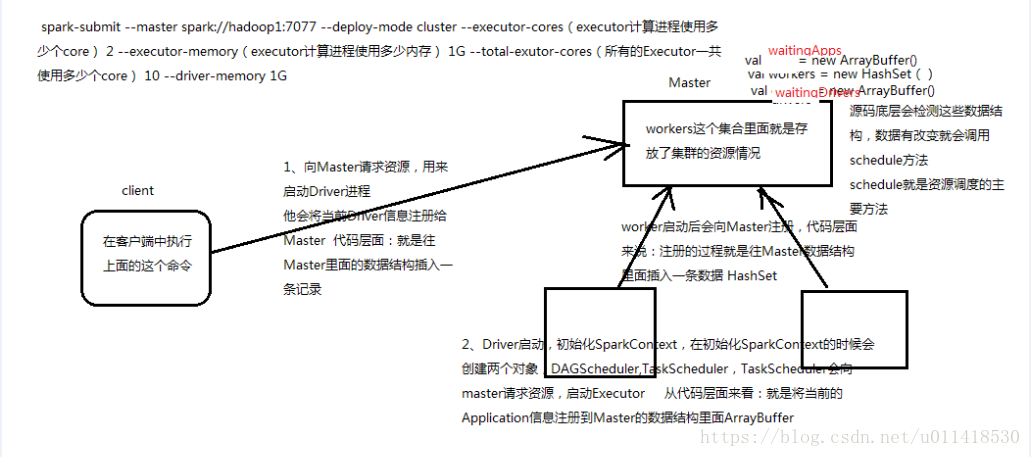
Work启动之后会向Master注册
代码层面来说:注册过程就是往Master数据结构里面插入一条数据HashSet ,这时候Master里就会有 val workers = new HashSet()的代码
1,客户端client执行spark-submit 任务命令,就会向Master请求资源,用来启动Driver进程,他会将当前Driver信息注册给Master;代码层面:就是往Master里面的数据结构插入一条记录;这时候Master里面就会多出一条,val waiting = new ArrayBuffer()
2,Driver启动,初始化SparkContext,在初始化SparkContext的时候会创建两个对象DAGScheduler,TaskScheduler;TaskScheduler会向master请求资源,启动Executor;从代码层面来说,就是将当前的Application信息注册到Master的数据结构里面;意思就是Master里面就会插入val waitingApps = new ArrayBuffer()
3,源码底层会检测Matser的数据结构,数据改变就会调用schedule方法;schedule就是资源调度的方法
spark-submit --master spark://hadoop1:7077
--deploy-mode cluster --executor-cores(executor计算进程使用多少个core) 2
--executor-memory(executor计算进程使用多少内存) 1G
--total-exutor-cores(所有的Executor一共使用多少个core) 10
--driver-memory 1G
是在内存充足的情况下使用的core:10/2 = 5
结论:
(1)默认情况下,每一个Worker为当前的Application启动一个Executor,这个Executor会使用全部的core
./spark-submit --master spark://hadoop1:7077 --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 1000
(2)在内存充足的前提下:如果想在某一台Worker上启动多个Executor需要设置--executor-cores
修改了spark-env.sh 每一台Worker 2G内存 3个core
./spark-submit --master spark://hadoop1:7077 --executor-cores 1 --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 1000
每一个Worker能够启动Executor的公式:
execuotNums = Math.min(Worker.sumCores/coresPerExecutor,Worker.sunMemory/memoryPerExecutor)
(3)默认情况下,Executror会在集群中分散启动(有利于数据本地化),如果不想分散启动怎么办?
new SparkConf().set("spark.deploy.spreadOut","false")
./spark-submit --master spark://hadoop1:7077 --executor-cores 1 --total-executor-cores 2 --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 1000
Spark-submit 命令
--master MASTER_URL spark://host:port, mesos://host:port, yarn, or local.
--deploy-mode DEPLOY_MODE
--class
--name
--jars 依赖的jar包路径, Driver和Executor里面的程序都可以依赖这个jar包
--files 会将指定的文件,下载到每一个Executor的工作目录区 默认是在Spark安装包下的WOrker目录
--conf --conf spark.deploy.spreadOut=false 可以代替代码里面 new SparkConf().set("spark.deploy.spreadOut","false")
--driver-memory MEM Memory for driver (e.g. 1000M, 2G) (Default: 1024M).
--driver-java-options Extra Java options to pass to the driver.
--driver-library-path Extra library path entries to pass to the driver.
--driver-class-path Extra class path entries to pass to the driver. Note that
jars added with --jars are automatically included in the
classpath.
--executor-memory MEM Memory per executor (e.g. 1000M, 2G) (Default: 1G).
--help, -h Show this help message and exit
--verbose, -v Print additional debug output
--version, Print the version of current Spark
Spark standalone with cluster deploy mode only:
--driver-cores NUM Cores for driver (Default: 1).
Spark standalone or Mesos with cluster deploy mode only:
--supervise 如果Driver在cluster模式下挂掉了 会重启
Spark standalone and Mesos only:
--total-executor-cores NUM Total cores for all executors.
Spark standalone and YARN only:
--executor-cores NUM Number of cores per executor. (Default: 1 in YARN mode,
or all available cores on the worker in standalone mode)
YARN-only:
--driver-cores NUM Number of cores used by the driver, only in cluster mode
(Default: 1).
--queue QUEUE_NAME 指定资源队列的名称
--num-executors NUM Number of executors to launch (Default: 2).