聚类算法准确率不太高,很少单独使用,但是会用来提供一些特征。
一、聚类算法简介
- 是一种无监督学习,只有数据x,没有标签y
- 试图通过数据间的关系发现一定的模式
可以作为监督学习中稀疏特征的预处理
比如有200个商品,不聚类的话就会很稀疏,聚类之后,可能会发现这些商品被分为几个大类,从而发现哪些人喜欢哪些类别的东西
不过结果可能不是很可靠,工业界用的较多的还是kmeans
1、聚类算法的过程:给定N个训练样本,同时给定聚类类别数K,把比较接近的样本放到一个类中,得到K个类
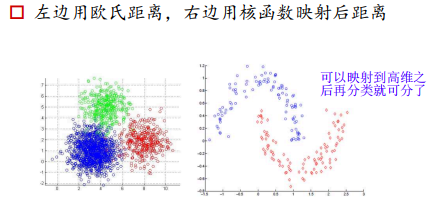
2、如何聚类:利用样本之间的相似度,相似度大的分为同类
3、聚类结果的评判(距离):高类间距,低类内距
4、评定内容:

无论用什么样的评定内容,最终都会把样本表示为向量,求取向量之间的距离。

5、聚类算法的分类:
有些聚类算法得到的类别时独立的,也就是每个样本只属于一个类别(kmeans,GMM)
有些聚类算法得到的类别是重叠的,可以看做是树状层叠,无需初始输入聚类个数(层次聚类)

二、K-means聚类
该算法是提出非常早,且使用非常频繁的算法

迭代收敛的定义:
聚类中心不再有变化
每个样本到对应聚类中心的距离之和不再有很大的变化
第二种计算距离之和的方法用的较多,因为是一个定量的分析
不再有很大的变化:因为样本量很大的时候,计算是有偏差的,所以说距离之和不再有很大的变化
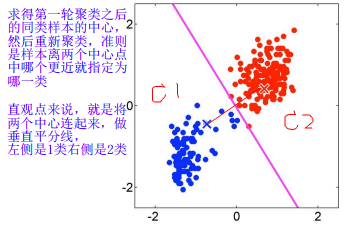
2.1 聚类过程:
随机确定k个初始点作为质心
将数据集中的每个点分配到一个簇中,即为每个点找到距离其最近的质心,并将其分配给该质心所对应的簇,该步骤完成后,每个簇的质心更新为该簇所有点的平均值。



2.2 K-means的损失函数

2.3 K-means的缺点
由于该损失函数(也叫畸变函数/散度函数)是非凸的函数,意味着难以收敛到局部最优,所以对初始聚类中心是敏感的**
解决方法:
- K-means++的方法:初始化第一个聚类中心为某个样本点,初始化第二个聚类中心点为离它最远的点,第三个点离它俩最远…
- 多进行几遍初始化,选使得损失函数最小的。
- 优化的初始化聚类方法
2.4 如何选择K:

2.5 K-means小结

K-Means的主要优点有:
1)原理比较简单,实现也是很容易,收敛速度快。
2)聚类效果较优。
3)算法的可解释度比较强。
4)主要需要调参的参数仅仅是簇数k。
K-Means的主要缺点有:
1)K值的选取不好把握
2)对于不是凸的数据集比较难收敛
3)如果各隐含类别的数据不平衡,比如各隐含类别的数据量严重失衡,或者各隐含类别的方差不同,则聚类效果不佳。
4) 采用迭代方法,得到的结果只是局部最优。
5) 对噪音和异常点比较的敏感。
2.6 K-means和KNN的区别
K-Means是无监督学习的聚类算法,没有样本输出,而K-Means有明显的训练过程,找到k个类别的最佳质心,从而决定样本的簇类别;
而KNN是监督学习的分类算法,有对应的类别输出。KNN基本不需要训练,对测试集里面的点,只需要找到在训练集中最近的k个点,用这最近的k个点的类别来决定测试点的类别。
当然,两者也有一些相似点,两个算法都包含一个过程,即找出和某一个点最近的点。两者都利用了最近邻(nearest neighbors)的思想。
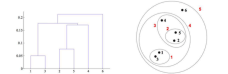
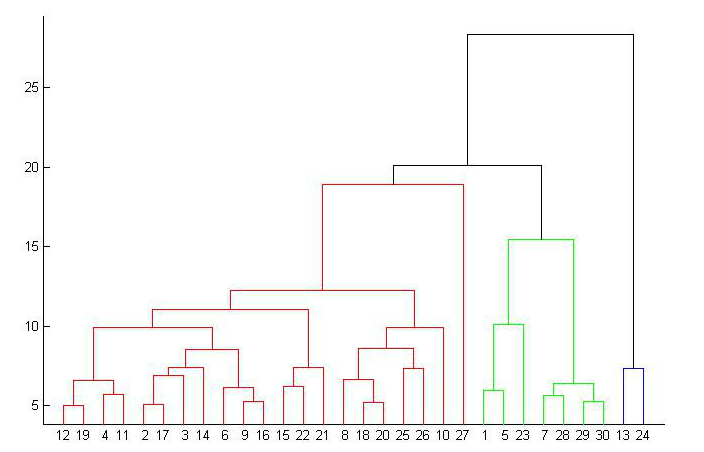
三、层次聚类
所谓从下而上地合并cluster,具体而言,就是每次找到距离最短的两个cluster,然后进行合并成一个大的cluster,直到全部合并为一个cluster。整个过程就是建立一个树结构,类似于下图。
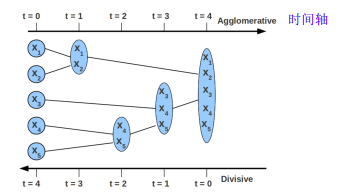
① 假设5个样本分别属于一个族,找到最接近的两个
② 将两个最接近的聚在一起,变为4类
③ 发现4和5最近,将其聚类
④ 直到将所有的样本聚到一类
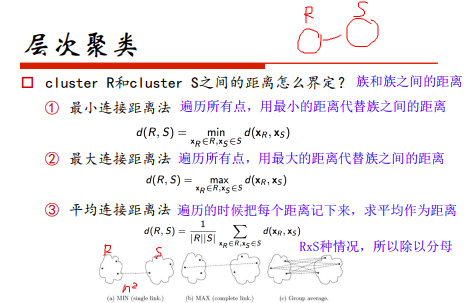
簇间的距离:
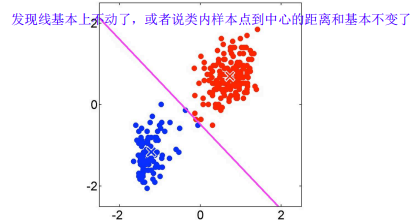
层次聚类和K-means的对比:

四、高斯混合模型
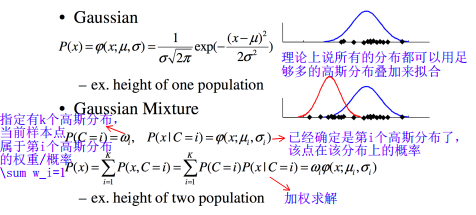


要点:
高斯混合模型系数之和为1,GMM整体的概率密度函数是由若干个高斯分量的概率密度函数线性叠加而成的,而每一个高斯分量的概率密度函数的积分必然也是1,所以,要想GMM整体的概率密度积分为1,就必须对每一个高斯分量赋予一个其值不大于1的权重,并且权重之和为1。
为什么要用EM算法求解
如果利用最大似然估计来求解的话,目标函数是对数的和,偏导难求,且很难展开,求解困难。
使用EM算法必须明确隐变量。(EM算法求解GMM)
高斯混合模型优势:

高斯混合模型的劣势:

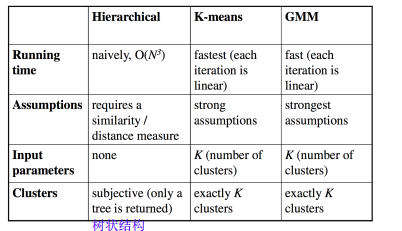
五、三种方法的对比
如果k的值和GMM的k的值一样的话,kmeans计算可能会快一点,可以将大量数据切分,逐层进行kmeans。
GMM模型给出的是每一个观测点由哪个高斯分量生成的概率,而K-means直接给出一个观测点属于哪一类。
GMM是一种“软性K-means”