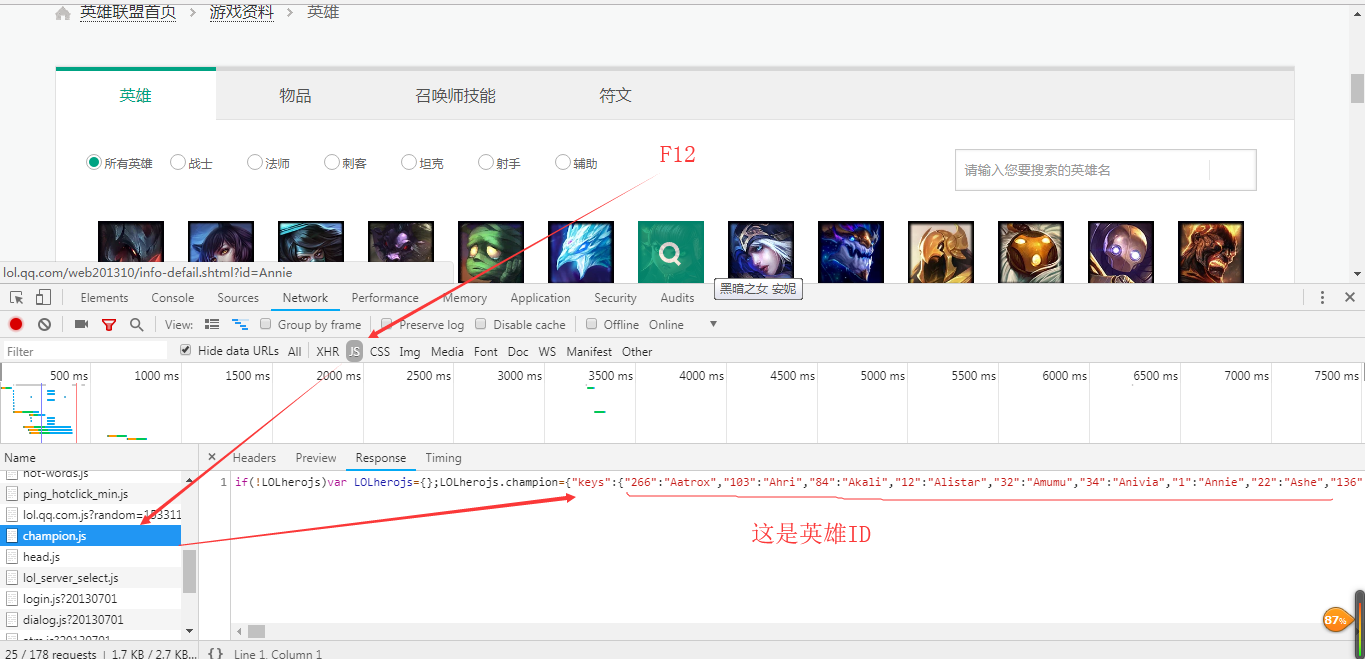
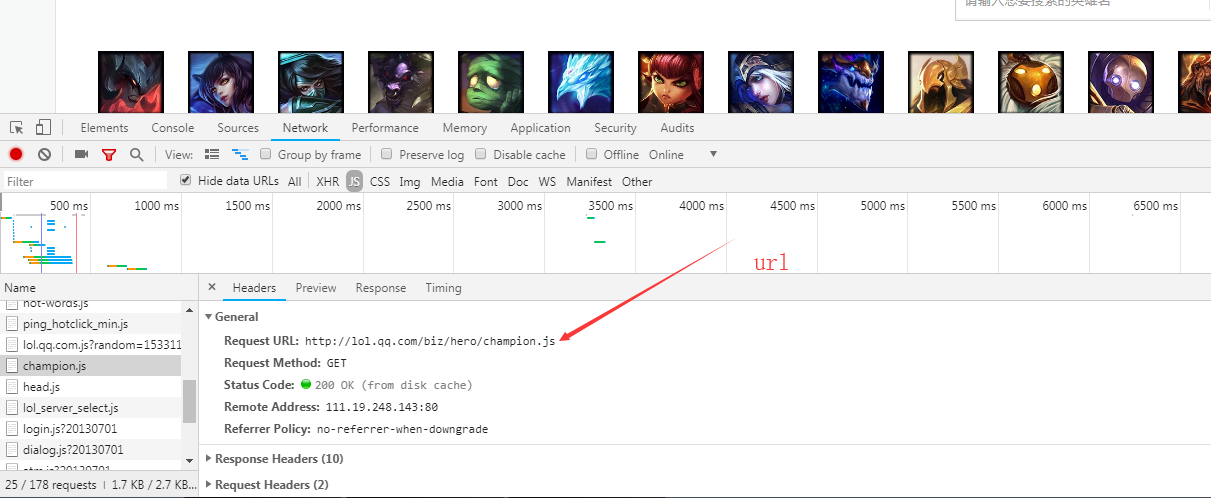
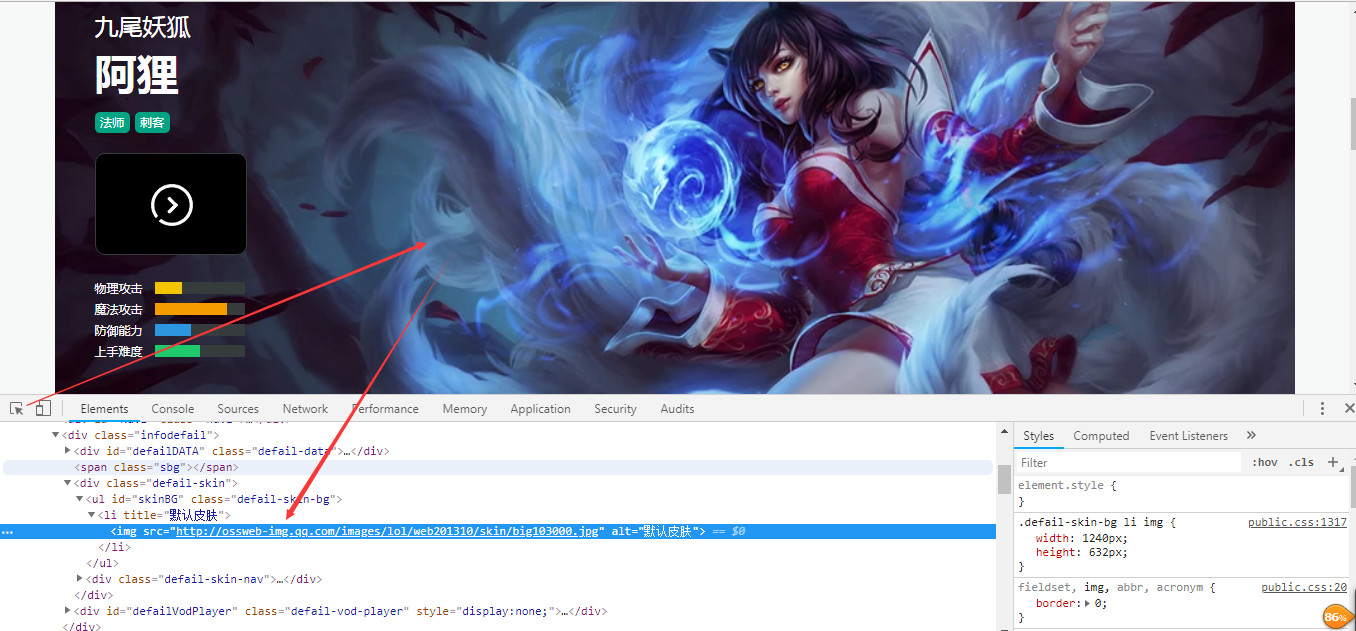
1 import requests
2 import json
3 import re
4 import os
5
6 class Grab_img(object):
7 hero_img_list = []
8
9 def __init__(self,url):
10 self.url = url
11
12
13 def grab_id(self):
14 response = requests.get(self.url)
15 pat = r"\"keys\":(.+),\"data\""
16 hero_id = json.loads(str(re.findall(pat, response.text))[2:-2])
17 for i in hero_id:
18 self.hero_img_list.append('http://ossweb-img.qq.com/images/lol/web201310/skin/big' + i + '000.jpg')
19
20
21
22 def storage_img(self):
23 for i in self.hero_img_list:
24 root = "F://爬取图片存储//"
25 # 文件名
26 path = root + i.split("/")[-1]
27
28 # 判断根目录是否存在
29 if not os.path.exists(root):
30 os.mkdir(root)
31
32 # 判断文件是否存在
33 if not os.path.exists(path):
34 r = requests.get(i)
35 with open(path, "wb") as f:
36 f.write(r.content)
37 print("文件保存成功~~")
38 else:
39 print("文件已存在~~")
40
41
42 def main(self):
43 #获取英雄ID
44 self.grab_id()
45
46 #下载保存图片
47 self.storage_img()
48
49
50 if __name__ == '__main__':
51 try:
52 t = Grab_img("http://lol.qq.com/biz/hero/champion.js")
53 t.main()
54 except:
55 print("爬取出错啦~~~")