依据训练集和验证集选择算法和调超参
- 在训练集上用不同模型训练,选取几个拟合效果好的模型
- 将这几个模型应用在验证集上,选择最优的一个或几个
在步骤2上,可以通过正则化等手段优化模型;步骤1是为了选择模型。
正则化为什么能起作用?
从贝叶斯的角度上看,正则化等价于对模型参数引入先验分布。在后验概率估计上,增加高斯分布先验,就是 正则化;增加拉普拉斯分布先验,就是 正则化。【这些分布的先验知识是对权重w而言的】。从求导推导过长看,增加了 先验,相当于在原本权重更新时,减去梯度的计算之前 ,对w进行了削减,即 。其结果就是造成最后的权重 比不添加正则化时小,极端一点看,若 较大,则 ,导致 。而 时,通过 函数,会基本展示不出非线性【即在sigmoid中间段,其基本呈线性传递】,因而导致模型的表达能力减弱,从而起到预防过拟合的作用。
dropout正则化
dropout正则化在计算机视觉应用比较多,因为计算机视觉的数据一般比较少。通常在我们没有足够多的数据时,导致存在的过拟合现象,我们才使用dropout正则化。【因为使用了dropout正则化后,我们优化的凭证Cost就不再是每次迭代都递减的了。这在某种程度上是很难计算的,因为我们失去了调试工具。】
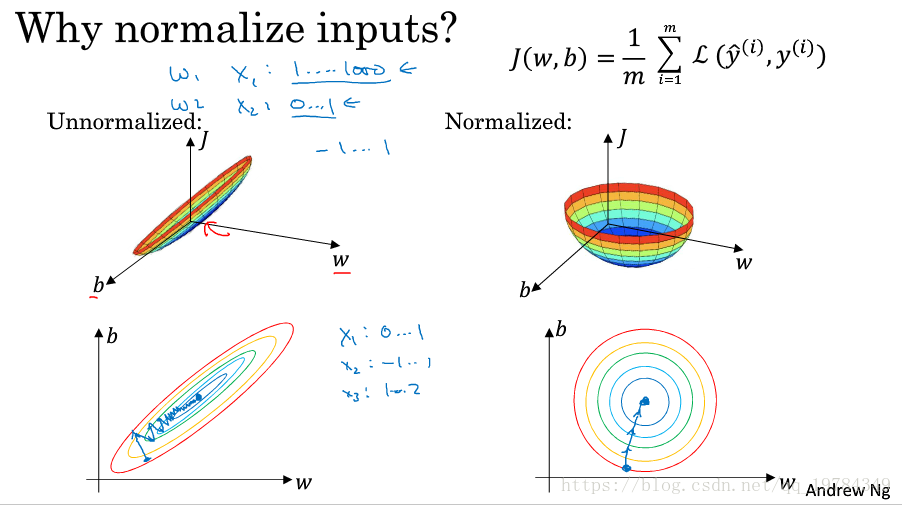
为什么归一化能加速模型拟合?
若未归一化前,数据分布呈现狭长状,即不同元素的取值范围差别大,则代价函数在不同元素上取得最优解需要的学习率不同。因此模型需要选择其中最小的学习率,以达到整个模型拟合的效果。而如果归一化了,则可以统一学习率,用较大的学习率去拟合数据,因而能加快模型拟合。
网络模型的超参数
- 模型方面:隐藏层层数、每层的神经元个数
- 优化方面:数据的mini-batch大小、学习率
的大小、学习衰减率、优化函数的参数
(假设是动量梯度下降法)、正则化项的系数
其中最重要,最需要调试的参数是学习率 ;其次是优化函数的参数 、每层神经元个数和mini-batch的大小;
Batch-Normalize(BN)
Batch-Normalize操作使网络每一层的输入归一化,即将 归一化,但是由于某些原因(如激活函数的效果等)就将这个归一化的操作提到了激活函数之前。
BN操作为什么起作用?
神经网络是多隐藏层叠起来的,其某一层的输入受之前所有层参数的控制,即convariat shift,也就是说该输入的分布是一直在变化的,这给该层的参数优化带来麻烦。BN操作将其分布固定为 的分布,使用 之后的均值受参数控制,但也固定分布。因此,BN操作就是讲每层的输入分布固定下来,使优化参数变得简单,也减少某参数梯度过大问题的出现,因而能加速模型拟合。
优化算法
优化算法前置知识
指数加权(移动)平均
一种计算连续变量的离散值平均的方式。其计算方式如下:
该计算方式在前几天的计算中很不准确,如第1天只有 ,所以有偏差修正:
梯度下降的优化
动量梯度下降法
计算梯度:
更新参数:
RMSprop
计算梯度:
更新方式:
这个跟之前笔记里的AdaDelta方法基本一模一样。
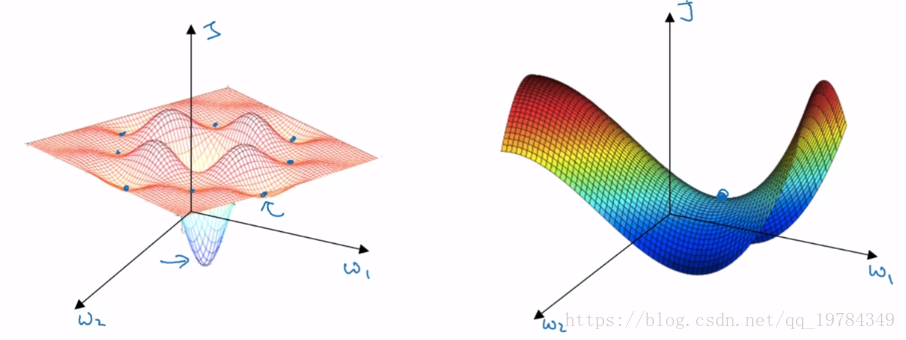
局部最优解
视频里说到,一直以来,我们担心神经网络陷入局部最优解,是像下图左边的那种,每个元素方向梯度都为
,且都是“凸”方向的极小值点。但是在高纬度中,梯度全为0且都是“凸”极值点的坑不多,大部分还是像下图右边的那种鞍点。因此,我们的优化目标应该是逃离鞍点,而不是过度担心“局部最优解”。