列表
list_01.py
# _*_ coding:utf-8 _*_
"""
file:list_01.py
date:2018-07-19 3:22 PM
author:wwy
desc:
"""
# sort:对列表中的元素升序排序,按首字母ASII码的排序方式
lippy = ['dior','ysl','tf','mac']
print lippy
lippy.sort()
print lippy运行结果:

list_02.py
# _*_ coding:utf-8 _*_
"""
file:list_02.py
date:2018-07-19 3:22 PM
author:wwy
desc:
"""
# sort:对列表里的元素排序
lippy = ['dior','ysl','tf','mac']
print lippy
# sort(reverse=True)降序
lippy.sort(reverse=True)
print lippy运行结果:

list_03.py
# _*_ coding:utf-8 _*_
"""
file:list_03.py
date:2018-07-19 3:23 PM
author:wwy
desc:
"""
lippy = ['dior','ysl','tf','mac']
print lippy
print sorted(lippy)
print lippy运行结果:

list_04.py
# _*_ coding:utf-8 _*_
"""
file:list_04.py
date:2018-07-19 3:23 PM
author:wwy
desc:
"""
# reverse():将列表里的元素倒着打印
lippy = ['dior','ysl','tf','mac']
print lippy
lippy.reverse()
print lippy运行结果:

for_01.py
# _*_ coding:utf-8 _*_
"""
file:for_01.py
date:2018-07-19 3:23 PM
author:wwy
desc:
"""
# for:遍历
names = ['alice','lucky','coco','rose']
# print_list:随便起的
for print_list in names:
print '%s ,how are you ?' % print_list
print 'I will miss you'运行结果:

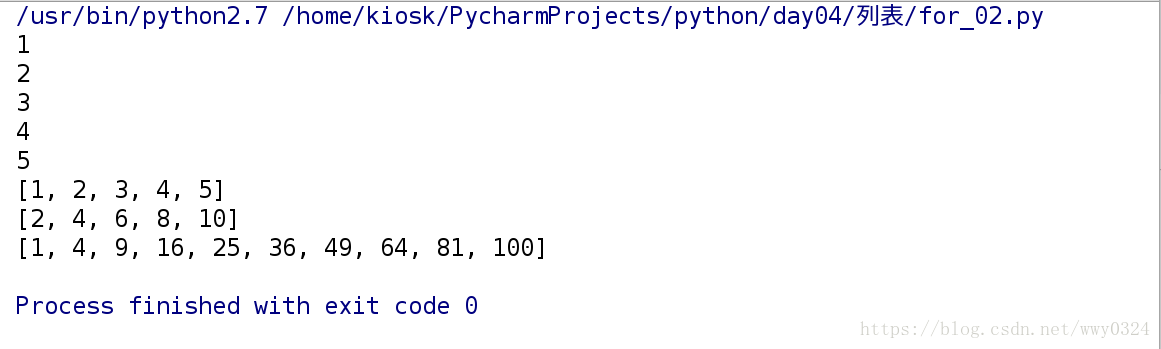
for_02.py
# _*_ coding:utf-8 _*_
"""
file:for_02.py
date:2018-07-19 3:23 PM
author:wwy
desc:
"""
for value in range(1,6):
print value
nums = list(range(1,6))
print nums
nums = list(range(2,11,2))
print nums
squares = []
for values in range(1,11):
squre = values ** 2
squares.append(squre)
print squares运行结果:
元组
tuple_01.py
# _*_ coding:utf-8 _*_
"""
file:tuple_01.py
date:2018-07-19 3:36 PM
author:wwy
desc:
"""
info_tuple = ('李四','张三','张三','18','1.75')
# 1.取值和取引索
print info_tuple[0]
print info_tuple.index('张三')
# 统计计数(有几个张三)
print info_tuple.count('张三')
# 统计元组中包含元素的个数
print len(info_tuple)运行结果:

tuple_02.py
# _*_ coding:utf-8 _*_
"""
file:tuple_02.py
date:2018-07-19 3:37 PM
author:wwy
desc:
"""
info_tuple = ('李四','张三','张三','18','1.75')
for my_info in info_tuple:
print my_info
info_tuple = ('小明',18,1.80)
# 格式化字符串后面(),本质上就是一个元组
print '%s 的年龄是:%d 身高是:%.2f' %info_tuple运行结果:

字典
dict_01.py
# _*_ coding:utf-8 _*_
"""
file:dict_01.py
date:2018-07-19 3:40 PM
author:wwy
desc:
"""
# 字典
message = {'name':'zmy',
'age':20,
'height':163,
'weight':44}
print message
# 1.取值
print message['name']
# 增加/修改
message['hobby'] = 'sing'
print message
message['sex'] = 'female'
print message
message['height'] = '164'
print message
# 删除
message.pop('sex')
print message运行结果:

dict_02.py
# _*_ coding:utf-8 _*_
"""
file:dict_02.py
date:2018-07-19 3:40 PM
author:wwy
desc:
"""
message = {'name':'zmy',
'age':20,
'height':163,
'weight':44}
# 1.统计键值对的数量
print len(message)
# 2.合并字典
# 字典的自定义键是可变的也是唯一的
temp_dict = {'height':164,'age':21,'sex':'girl'}
message.update(temp_dict)
print message
# 清空字典
message.clear()
print message运行结果:

dict_03.py
# _*_ coding:utf-8 _*_
"""
file:dict_03.py
date:2018-07-19 3:41 PM
author:wwy
desc:
"""
message_dict = {'name':'harry',
'qq':'123456',
'phone':'10086'}
for k in message_dict:
print k
print '%s - %s' %(k,message_dict[k])运行结果:

dict_04.py
# _*_ coding:utf-8 _*_
"""
file:dict_04.py
date:2018-07-19 3:41 PM
author:wwy
desc:
"""
card_list = [{'name':'zmy','qq':'1233333333444','phone':'10010'},
{'name':'jcl','qq':'128738127','phone':'10086'}]
for card_info in card_list:
print card_info运行结果:

dict_05.py
# _*_ coding:utf-8 _*_
"""
file:dict_05.py
date:2018-07-19 3:41 PM
author:wwy
desc:
"""
word_list = [{'w1':'v1','w2':'v2','w3':'v3'},
{'a1':'b1','a2':'b2'}]
for word_into in word_list:
for k in word_into:
print '%s - %s' %(k,word_into[k])运行结果:

dict_06.py
# _*_ coding:utf-8 _*_
"""
file:dict_06.py
date:2018-07-19 3:41 PM
author:wwy
desc:
"""
word_list = [{'w1':'v1','w2':'v2','w3':'v3'},
{'a1':'b1','a2':'b2'}]
for word_into in word_list:
print word_into
for k in word_into:
print '%s - %s' %(k,word_into[k])运行结果:

# for循环读取列表1,列表二,读完后word_into的值为列表2,所以k只能读取到第二个列表的值
字符串
str_01.py
# _*_ coding:utf-8 _*_
"""
file:str_01.py
date:2018-07-19 3:59 PM
author:wwy
desc:
"""
str1 = 'hello python'
for char in str1:
print char
str2 = u'我的好朋友叫高放' # 打印汉字组成的字符串前面要加u
for char in str2:
print char运行结果:

str_02.py
# _*_ coding:utf-8 _*_
"""
file:str_02.py
date:2018-07-19 3:59 PM
author:wwy
desc:
"""
hello_str = 'hello python llo'
# 1.统计字符串的长度
print len(hello_str)
# 2.统计子字符串的次数
print hello_str.count('ww')
# 3.某一个字符串出现的位置
print hello_str.index('llo')
# 使用index()方法的时候,如果子字符串不存在,程序会报错
#print hello_str.index('ww')运行结果:

str_03.py
# _*_ coding:utf-8 _*_
"""
file:str_03.py
date:2018-07-19 3:59 PM
author:wwy
desc:
"""
# 1.判断字符串是否含有空格
space_str = ' '
print space_str.isspace()
space_str = '\t\n'
print space_str.isspace()
print '-' * 50
# 2.判断字符串是否只包含数字
num_str = '1234546'
print num_str.isdigit()
print '-' * 50
# 3. 判断是否以指定的字符串开始
hello_str = 'hello python'
print hello_str.startswith('he')
print hello_str.startswith('ha')
print '-' * 50
# 4.判断字符串是否以指定的子字符串结束
print hello_str.endswith('n')
print hello_str.endswith('o')
print '-' * 50
# 5.查找指定字符串,返回的是一个引索
print hello_str.find('o')
print hello_str.find('w')
print '-' * 50
# 6.替换字符串
print hello_str
print hello_str.replace('python','world')运行结果:

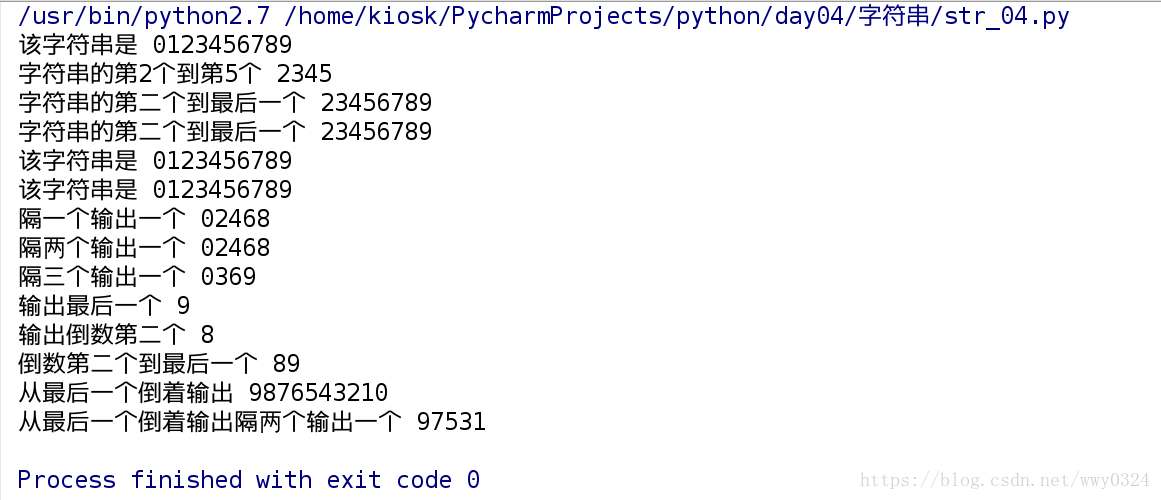
str_04.py
# _*_ coding:utf-8 _*_
"""
file:str_04.py
date:2018-07-19 3:59 PM
author:wwy
desc:
"""
num_str = '0123456789'
print '该字符串是 %s' %num_str
print '字符串的第2个到第5个 %s' % num_str[2:6]
print '字符串的第二个到最后一个 %s' % num_str[2:]
print '字符串的第二个到最后一个 %s' % num_str[2:10]
print '该字符串是 %s' % num_str[:10]
print '该字符串是 %s' % num_str[:]
print '隔一个输出一个 %s' % num_str[0:10:2]
print '隔两个输出一个 %s' % num_str[::2]
print '隔三个输出一个 %s' % num_str[::3]
print '输出最后一个 %s' % num_str[-1]
print '输出倒数第二个 %s' % num_str[-2]
print '倒数第二个到最后一个 %s' % num_str[-2:]
print '从最后一个倒着输出 %s' % num_str[-1::-1]
print '从最后一个倒着输出隔两个输出一个 %s' % num_str[-1::-2]运行结果: