1 Python基础类型知识补充
1.1 Str
1:将列表转换成字符串:join(可迭代对象)
2:将字符串转换成列表:split()
例如:
(1)s='_'.join(["高华新",'刘清杨','崔园章'])
print(s)
------结果:高华新_刘清杨_崔园章
(2)ss="高华新_刘清杨_崔园章"
s=ss.split('_')

print(s)
--------结果:['高华新', '刘清杨', '崔园章']
1.2 List->for循环清空数据的方法
列表和字典在循环的时候不能直接删除.
需要把要删除的内容记录在新列表中.
然后循环新列表.删除字典或列表
经过分析发现. 循环删除都不行. 不论是用del还是用remove、pop. 都不能实现.
例题:
清空li列表li = [11,22,33,44]
方式一:
li.clear()
print(li)
----à结果:[]
方式二:
for e in li :
li.remove(e)
print(li)
--->结果:[22, 44]
【分析原因:】 for的运⾏过程. 会有一个指针来记录当前循环的元素是哪⼀个, 一开始这个指针指向第0 个. 然后获取到第0个元素. 紧接着删除第0个. 这个时候. 原来是第⼀个的元素会自动的变成 第0个. 然后指针向后移动一次, 指向1元素. 这时原来的1已经变成了0, 也就不会被删除了
解决方法:
-->精髓:使得的索引对应的数据是不变的à用一个新的列表放数据用于取索引

1.3 Dcit--- for循环清空数据的方法
与列表的方法相同

1.4 Fromkeys
批量创建键值对
dic = {"apple":'苹果','banana':'香蕉'}
dic.fromkeys('orange','橘子')
print(dic)
---à结果:{'apple': '苹果', 'banana': '香蕉'}
----à要清楚:fromkeys这个函数是批量创建一个新的字典,与原来的字典没有关系
---à fromkeys直接使用字典类名进行访问
ret = dict.fromkeys("abc",["哈哈","呵呵", "吼吼"]) #
print(ret)
#{'a': ['哈哈', '呵呵', '吼吼'], 'b': ['哈哈', '呵呵', '吼吼'], 'c': ['哈哈', '呵呵', '吼吼']}
a = ["哈哈","呵呵", "吼吼"]
ret = dict.fromkeys("ab", a) # fromkeys直接使用类名进行访问
a.append("嘻嘻") #同样会添加到字典中,因为a的地址没有变
print(ret)
#{'a': ['哈哈', '呵呵', '吼吼', '嘻嘻'], 'b': ['哈哈', '呵呵', '吼吼', '嘻嘻']}
1.5 类型转换:
元组 => 列表 list(tuple)
列表 => 元组 tuple(list)
list=>str str.join(list)
str=>list str.split()
转换成False的数据: 0,'',None,[],(),{},set() ==> False
2 集合set
set中的元素是不重复的.无序的.⾥面的元素必须是可hash的(int, str, tuple,bool), 我们可以这样来记. set就是dict类型的数据但 是不保存value, 只保存key. set也用{}表⽰注意: set集合中的元素必须是可hash的(如列表中的key是不可变的). set是可变的(可增删改查)
2.1特点: 无序, 不重复, 元素必须可哈希(不可变)
元素是可哈希的即不可变的
无序的
不可重复的, 可以用于去重(重复的内容不打印)
(存储的是字典里的key,不存储value)
集合本身是可变的数据类型, 不可哈希, 有增删改查的操作
frozenset( )可以冻结集合,使集合 不可变, 可哈希
2.1.1 元素可hash(不可变)
s={'aa','hufh','koi'} #set集合
s1={'aa','hufh','koi',('1',2)} #可含有tuple
s2={'aa','hufh','koi',['1',2]} #错误的 含有list不可哈希
2.1.2 去重复:
lst = {11,5,4,1,2,5,4,1,25,2,1,4,5,5}
s= set(lst)
print(s)
->结果:{1, 2, 4, 5, 25, 11}
2.2 集合的操作
2.2.1 增
2.2.1.1 Add
集合名.add()
例如:
lst = {11,5,4,1,2,5,4,1,25,2,1,4,5,5}
lst.add("hah")
print(lst)
--à结果:{1, 2, 4, 5, 11, 'hah', 25}
s = {"刘嘉玲", '关之琳', "王祖贤"}
s.add("郑裕玲") # 重复的内容不会被添加到set集合中 print(s)
print(s)
--à结果:{'关之琳', '郑裕玲', '王祖贤', '刘嘉玲'}
2.2.1.2 Update---》迭代更新
s = {"刘嘉玲", '关之琳', "王祖贤"}
s.update("麻花藤") # 迭代更新
print(s)
-->结果:{'关之琳', '刘嘉玲', '麻', '王祖贤', '藤', '花'}
2.2.2 删
2.2.2.1 Pop—》随机弹出一个.
s = {"刘嘉玲", '关之琳', "王祖贤","张曼玉", "李若彤"}
item = s.pop() # 随机弹出一个.
print(s)
print(item)
--.>结果: {'张曼玉', '李若彤', '王祖贤', '关之琳'}
刘嘉玲
2.2.2.2 Remove--à删除指定值
s = {"刘嘉玲", '关之琳', "王祖贤","张曼玉", "李若彤"}
s.remove("关之琳") # 直接删除元素
#s.remove("⻢虎疼") # 不存在这个元素. 删除会报错
print(s)
-->结果:{'李若彤', '王祖贤', '张曼玉', '刘嘉玲'}
2.2.2.3 Clear -à清空
s.clear() # 清空set集合.需要注意的是set集合如果是空的. 打印出来是set() 因为要和 dict区分的.
print(s)
---à结果:set()
2.2.3 修改
set集合中的数据没有索引. 也没有办法去定位一个元素. 所以没有办法进行直接修改.
# 我们可以采用先删除后添加的方式来完成修改操作
s = {"刘嘉玲", '关之琳', "王祖贤","张曼玉", "李若彤"}
# 把刘嘉玲改成赵本山
s.remove("刘嘉玲")
s.add("赵本山")
print(s)
--->结果:{'李若彤', '赵本山', '关之琳', '王祖贤', '张曼玉'}
2.2.4 查询
set是⼀一个可迭代对象. 所以可以进⾏行行for循环
s = {"刘嘉玲", '关之琳', "王祖贤","张曼玉", "李若彤"}
for i in s :
print(i)
2.3 集合的其他常用操作
2.3.1 集合的交集
s1 = {"刘能", "赵四", "⽪山"}
s2 = {"刘科长", "冯乡长", "⽪山"}
print(s1 & s2)
print(s1.intersection(s2))
->{'⽪山'}
2.3.2 集合的并集
print(s1|s2)
print(s1.union(s2))
2.3.3 集合的反交集(亦或)
print(s1 ^ s2)
print(s1.symmetric_difference(s2))
2.3.4 集合的子集
s1 = { "⽪山"}
s2 = {"刘科长", "冯乡长", "⽪山"}
print(s1<s2)
print(s1.issubset(s2))
->True
2.3.5 集合的超集
print(s1 > s2)
print(s1.issuperset(s2))
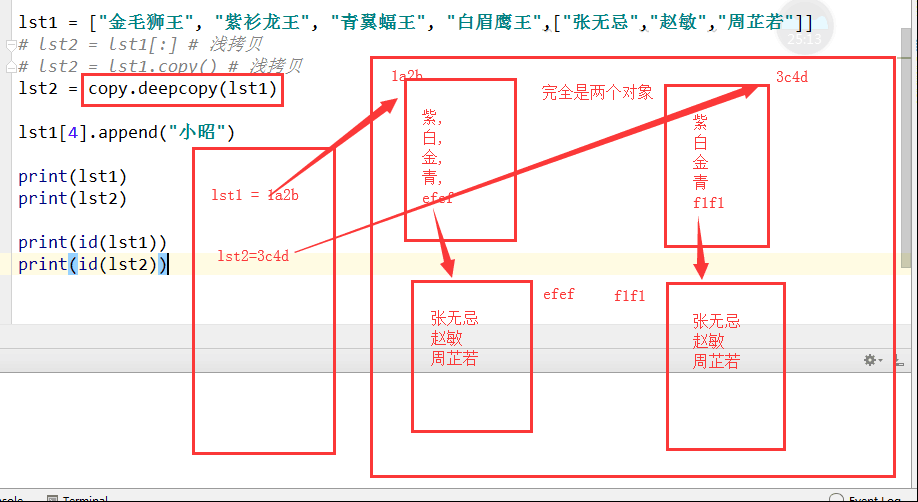
3 深浅拷贝

3.1 赋值.
没有创建新对象. 公用同一个对象
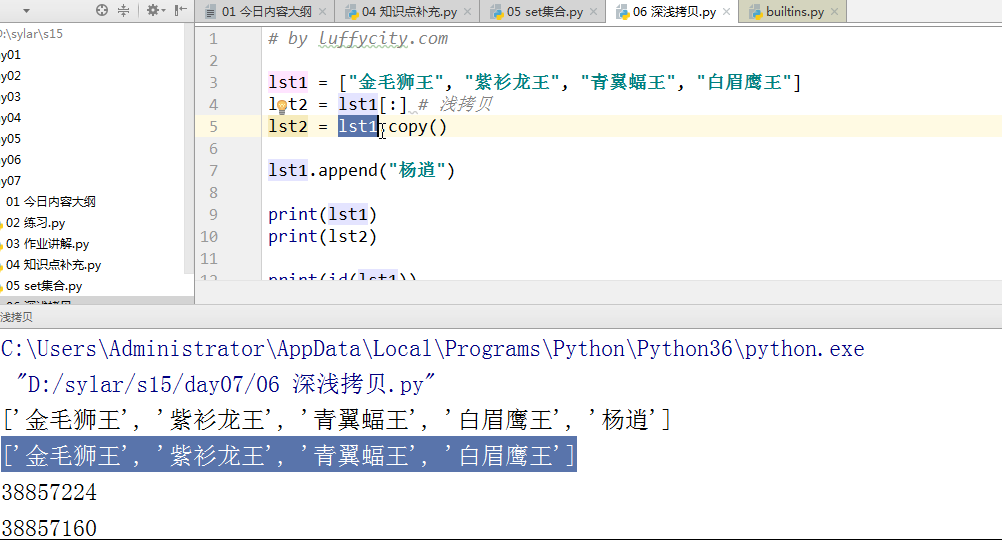
3.2 浅拷贝.
拷贝第一层内容(复制的只是表层
拷贝的方式:[:]或copy()
例子:1
例子2:
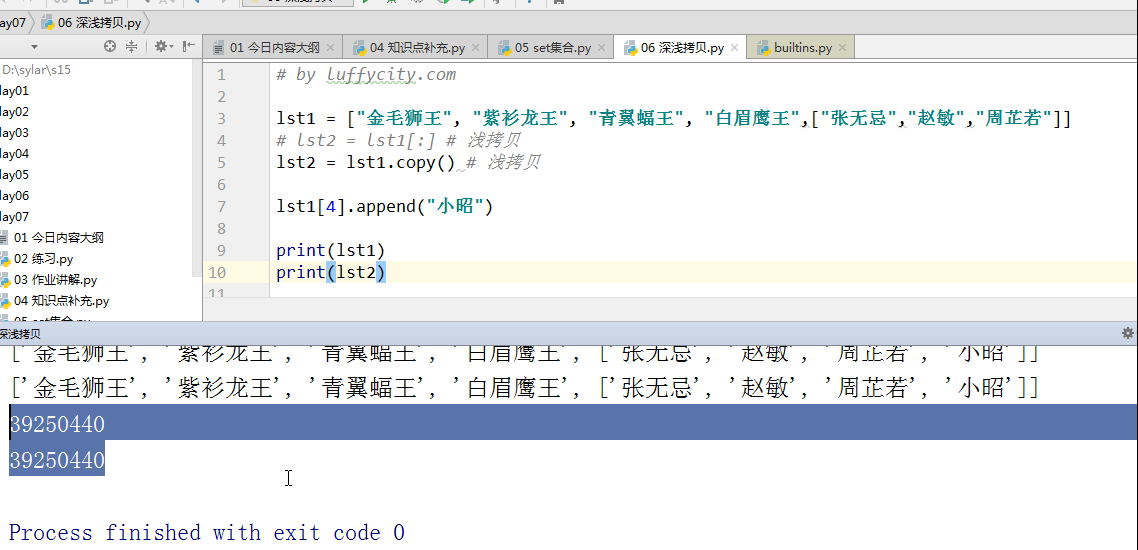

3.3 深拷贝. Copy.deepcopy()
拷贝所有内容. 包括内部的所有(完完全全的复制
先入模块import copy