scrapy框架是目前最受欢迎的爬虫框架之一,今天我们来具体的去了解一下scrapy框架。
scrapy是一个快速,高层次,轻量级的屏幕抓取和web抓取的python爬虫框架。
scrapy用途十分的广泛,主要的去用于web站点的信息并且从中提取特定的结构的数据,除此之外,scrapy还可以用于数据挖掘,检测,自动化测试,信息处理等等,首先我们来看一下该怎么安装scrapy。
安装Scrapy
安装的方法有两种。
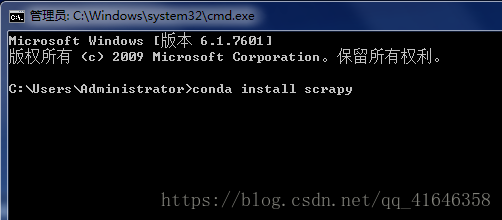
1.如果你的电脑上安装的有Anaconda的话,可以直接windows+R,输入cmd,进入终端,输入conda install scrapy,点击回车,静静的等待安装成功就可以了。
2.假如未安装Anaconda,使用pip方式安装,首先我们需要来下载一些插件。
下载地址:::https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
【1】进入该网站,该网站可能加载速度会很慢,所以请耐心等待。进入后,按ctrl+F,搜索twisted,下载对应的版本即可.
cp27表示的是python2.7版本,cp36就表示的是python3.6版本。
win32表示的就是Windows32位的操作系统
这里就根据自己所用的版本与电脑的配置来选择适应自己的版本。

【2】下载完成后,进入终端,输入命令:pip install Twisted-18.7.0-cp36-cp36m-win32.whl
这个命令是你下载的是哪个,就输入那个。
安装完成后,就输入pip install scrapy ,按下回车。
检验scrapy是否安装成功,输入scrapy,出现以下的内容就安装成功了。

Scrapy用法
安装完成之后我们那可以来小试,了解一下scrapy,注意:scrapy的命令都是在终端里面完成的。
1.scrapy可执行的命令
上图所示,显示的就是scrapy可以执行的命令,有以下。

bench:性能测试
fetch:读取源代码
genspider:生成爬虫文件
runspider:运行爬虫文件
setting:爬虫设置
shell:终端操作
startproject:创建新的项目
version:查看版本
2.创建一个scrapy框架,这个是进行所有操作的前提。
1.在PyCharm里创建一个文件名,文件名字为Python,打开终端,输入cd+空格+Python的路径,按下回车键。
2.输入命令:scrapy startproject python. python为项目的名字,这个是自定义的,按下回车键。
3.输入命令:cd+空格+python,回车,继续输入:cd+空格+python,按下回车键。
4.输入命令:scrapy genspider baid baidu.com。生成一个爬虫文件,这里是以百度为例。

完毕后,打开PyCharm,我们可以看到Python文件下多了许多新的文件。

解释一下上图中各部分文件的作用:
items.py;定义爬虫程序的数据模型
middlewares.py:定义数据模型中的中间件
pipelines.py:管道文件,负责对爬虫返回数据的处理。
settings.py:爬虫程序设置,主要是一些优先级设置,优先级越高,值就越小。
scrapy.cfg:内容为scrapy的基础配置
我们进行爬虫的操作大部分是在baid.py中完成的,点击进入:
# -*- coding: utf-8 -*-
import scrapy
class BaidSpider(scrapy.Spider):
# 爬虫名
name = 'baid'
#允许爬虫的范围
allowed_domains = ['baidu.com']
## 通常会修改爬虫程序的start_url,这个是第一批要进行访问的网址,这里我们补全网址。
start_urls = ['http://www.baidu.com/']
def parse(self, response):
print(response.text)另外,我们需要修改一下settings.py里面的内容
(1)打开文件,找到代码的第22行,把 ROBOTSTXT_OBEY=True 改为 False,这行代码表示是否遵循爬虫协议,如果是Ture的可能有些内容无法爬取。
(2)将第67到69行代码解注释,并把300改为1,这是优先级设置,值越小优先级就越高。
在终端中输出运行的命令,scrapy crawl baid,按下回车键。
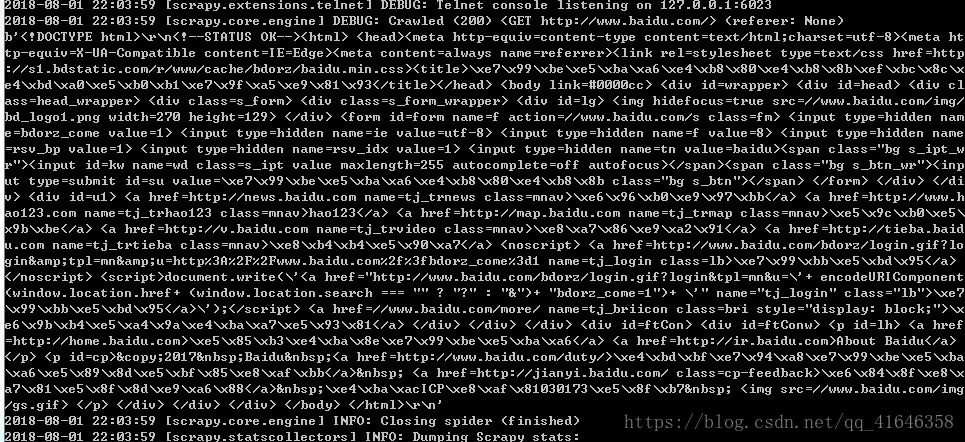
成功出现目标url的网页源代码即为成功。
Scrapy框架图。

此图来源于网络。
Scrapy Engine:引擎,处理整个框架的数据流
Scheduler:调度器,接收引擎发过来的请求,将其排至队列中,当引擎再次请求时返回
Downloader:下载器,下载所有引擎发送的请求,并将获取的源代码返回给引擎,之后由引擎交给爬虫处理
Spiders:爬虫,接收并处理所有引擎发送过来的源代码,从中分析并提取item字段所需要的数据,并将需要跟进的url提交给引擎,再次进入调度器
Item Pipeline:管道,负责处理从爬虫中获取的Item,并进行后期处理
Downloader Middlewares:下载中间件,可以理解为自定义扩展下载功能的组件
Spider Middlewares:Spider中间件,自定义扩展和操作引擎与爬虫之间通信的功能组件
Scrapy数据处理流程:
1. 当需要打开一个域名时,爬虫开始获取第一个url,并返回给引擎
2.引擎把url作为一个请求交给调度器
3.引擎再次对调度器发出请求,并接收上一次让调度器处理的请求
4.引擎将请求交给下载器
5.下载器下载完成后,作为响应返回给引擎
6.引擎把响应交给爬虫,爬虫开始进一步处理,处理完成后有两个数据,一个是需要跟进的url,另一个是获取到的item数据,然后把结果返回给引擎
7.引擎把需要跟进的url给调度器,把获取的item数据给管道
8.然后从第2步开始循环,知道获取信息完毕。只有调度器中没有任何请求时,程序才会停止
今天关于Scrapy的介绍就到这里了,关于以后用scrapy获取具体的数据,之后,我会持续更新的。