一、前言
按传统方法,能否在服务器上,能否成功搭建 hadoop 集群,取决于配置是否配置成功
在习惯优于配置的时代,已然过时
使用 docker 技术,零配置,10 秒内轻松搭建 hadoop 集群
本文图文并茂,轻松阅读无障碍
二、环境搭建
主要使用的镜像:kaibb/hadoop
阿里云镜像的,云服务器若也是阿里云的,拉去的速度将十分惊人
2.1.拉取镜像
docker pull registry.aliyuncs.com/kaibb/hadoop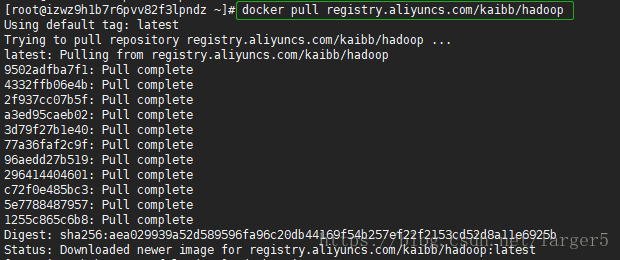
可以使用 docker images 查看镜像是否存在
2.2.启动容器
docker run -itd --name hadoop -h hadoop -P registry.aliyuncs.com/kaibb/hadoop
先使用 docker ps 查看端口映射,后面要在网页访问 DFS、YARN 要分别用到 50070、8088 端口的映射!!

使用 docker ps -a 查看各个容器运行的状态
2.3.进入容器
docker exec -it hadoop bash
2.4.格式化 namenode
在任何目录下运行 hadoop 命令都可以
hadoop namenode -format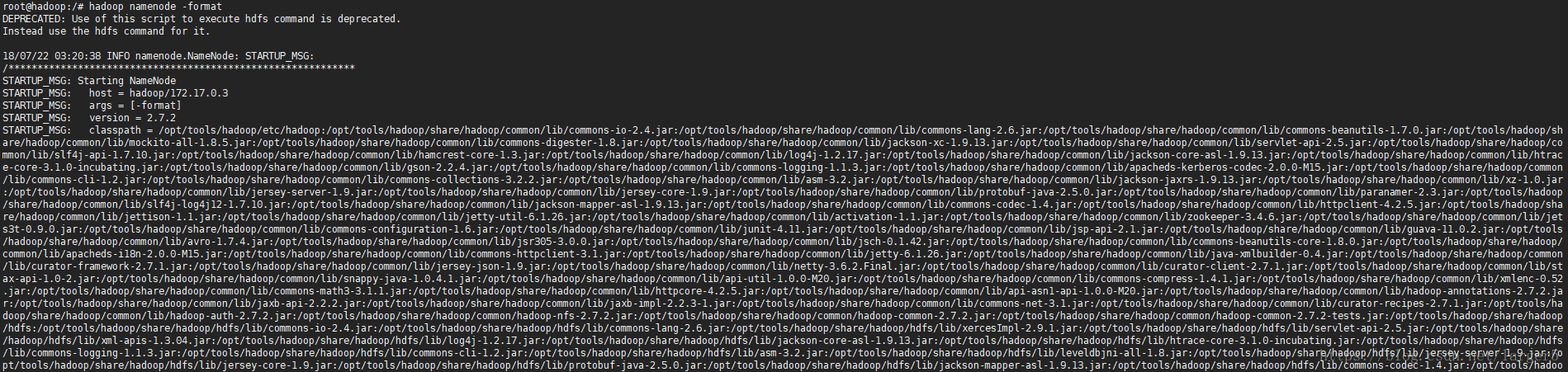
输出了一堆很长的日志。。。
2.5.运行 DFS
start-dfs.sh中间输入两个 yes,不要输入错误 ~
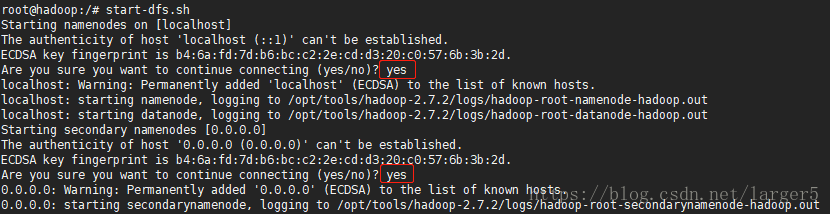
之后可以使用 jps 查看节点
访问 http://120.79.197.130:32802
(① 改120.79.197.130为你的服务器ip、② 改32802为你的 50070映射端口、③ 云服务器注意开启安全组)
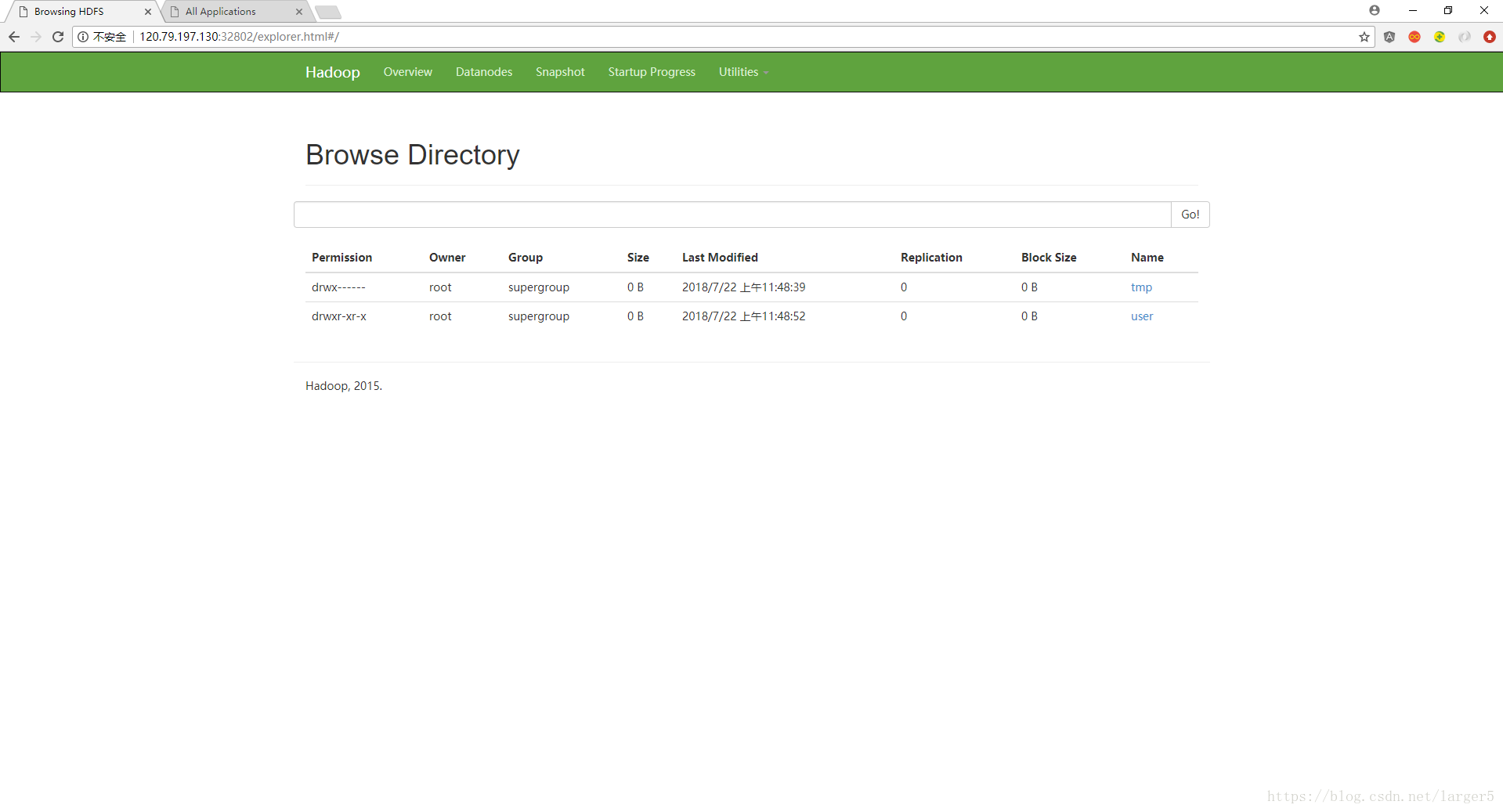
进入如下页面,说明一切顺利
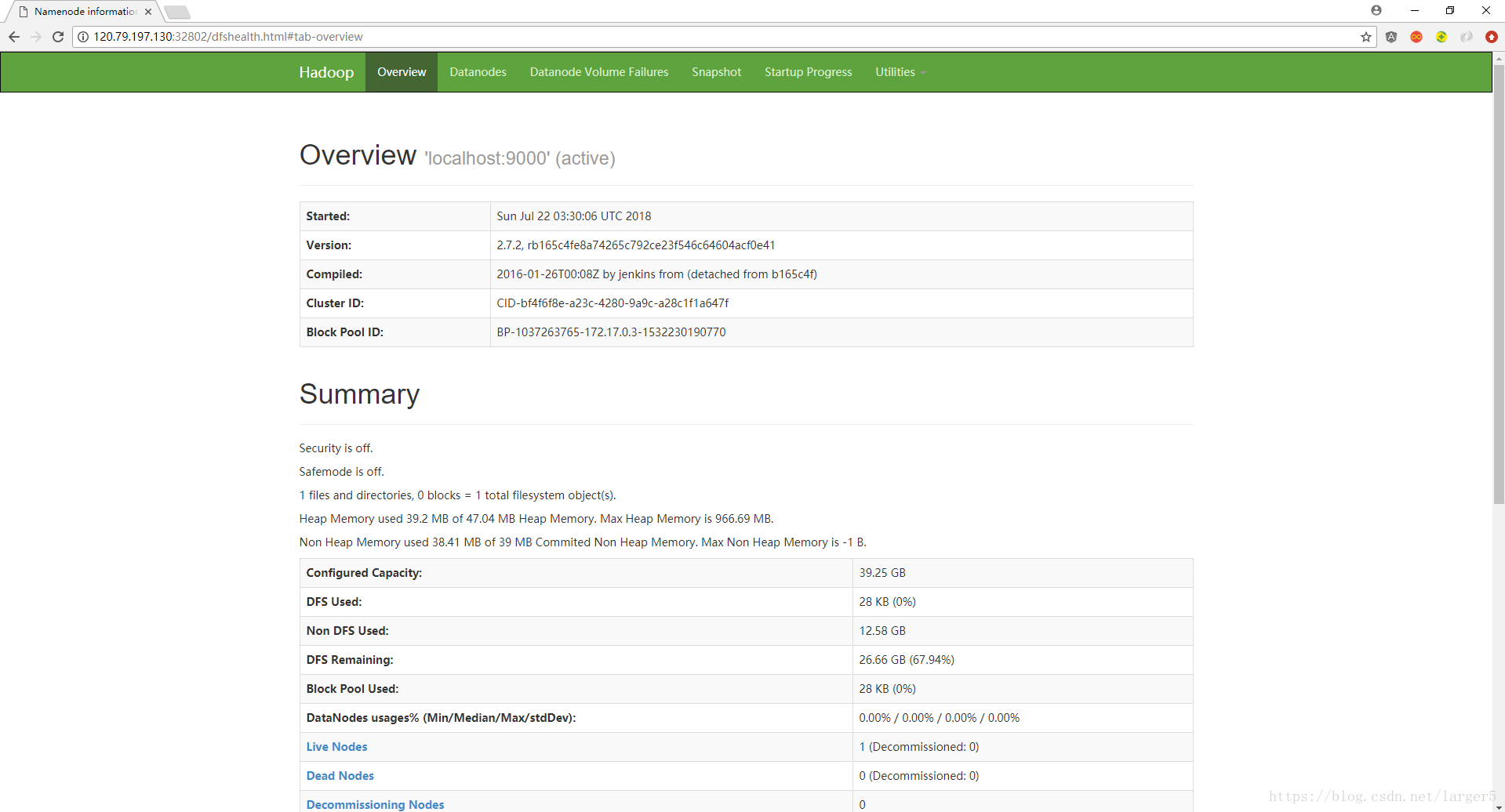
2.6.运行 YARN
start-yarn.sh
之后可以再次使用 jps 查看新节点
访问 http://120.79.197.130:32807 进入如下页面,说明一切顺利
(① 改120.79.197.130为你的服务器ip、② 改32807为你的 8088 映射端口、③ 云服务器注意开启安全组)
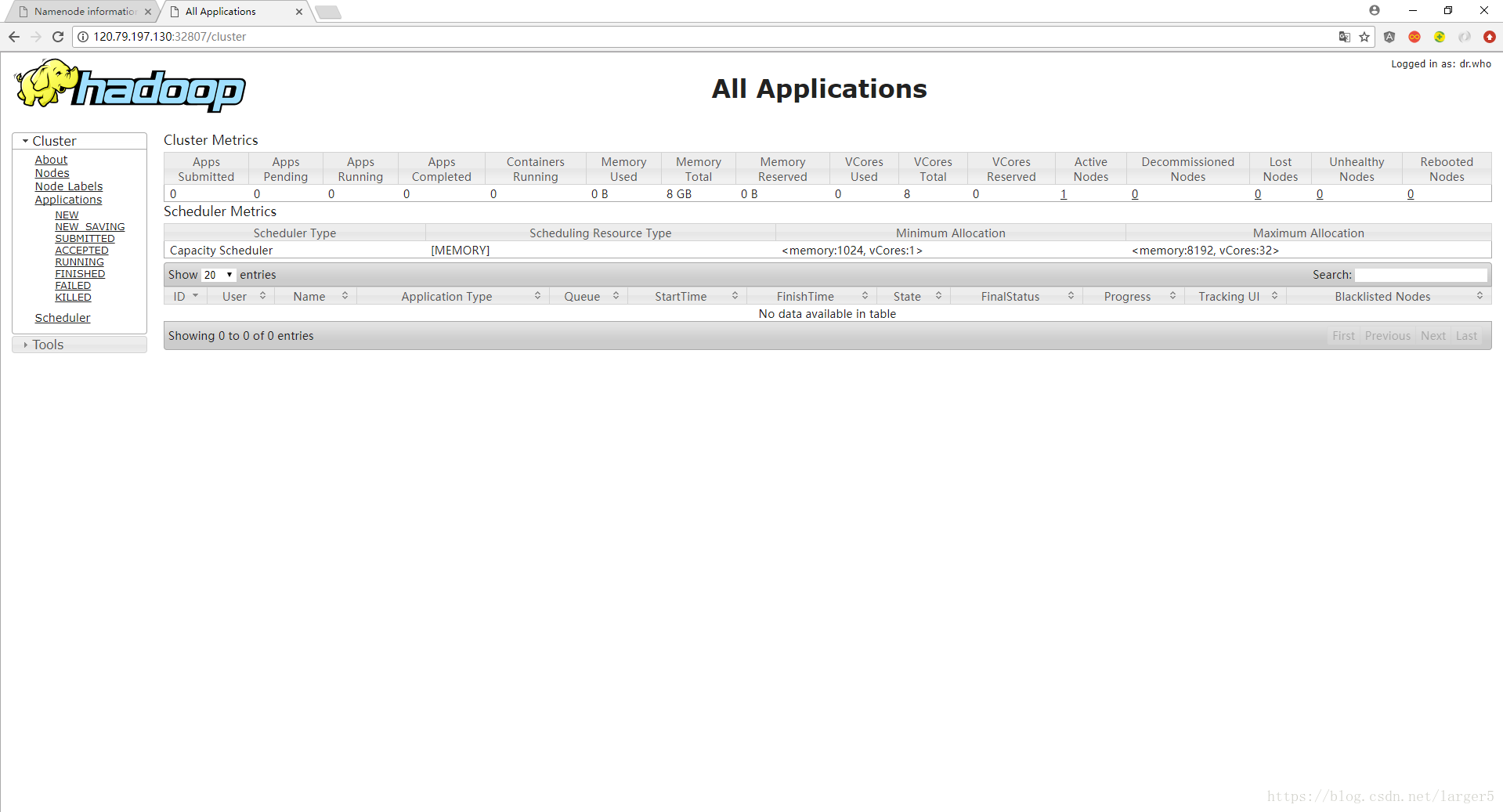
三、其他操作
3.1.更换目录
cd /opt/tools/hadoop
3.2.创建文件夹
hdfs dfs -mkdir -p /user/kaibb/input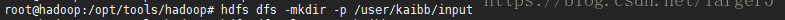
可以使用 hdfs dfs -ls /user/kaibb 查看刚刚创建的目录
3.3.复制文件至dfs文件目录中
hdfs dfs -put /opt/tools/hadoop/etc/hadoop/* /user/kaibb/input
可以使用 hdfs dfs -ls /user/kaibb/input 查看 dfs文件目录下的内容
也可以在网页直接查看,点击红色框中的内容:

如下:
3.4.运行示例程序
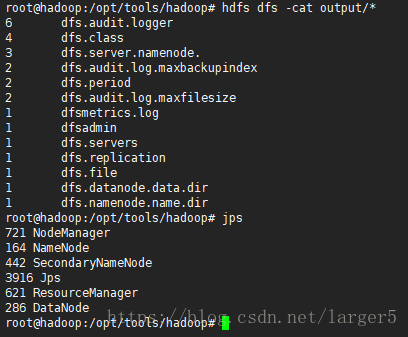
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar grep /user/kaibb/input output 'dfs[a-z.]+'
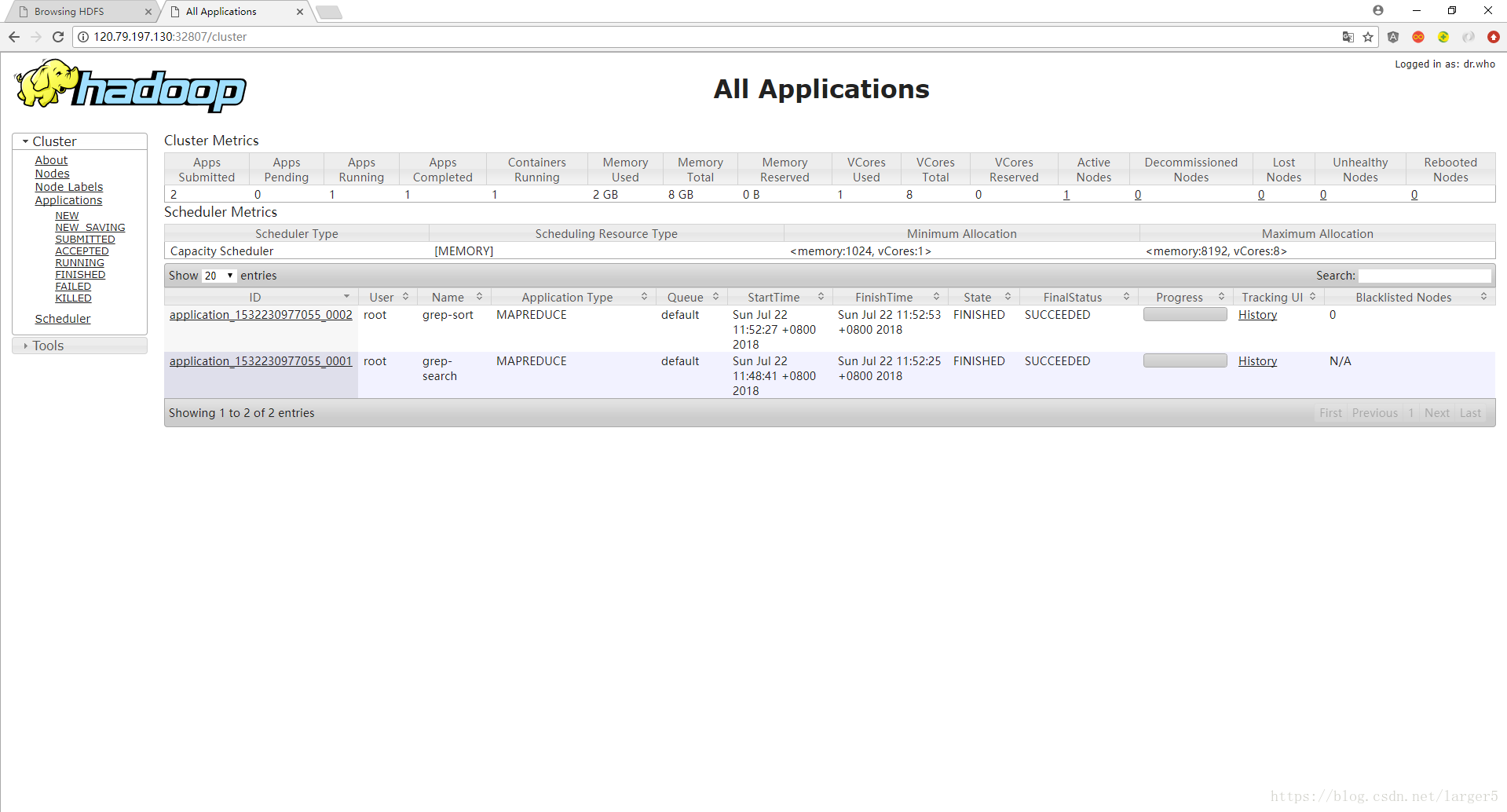
在 YARN 中可以看到运行成功的两个应用:
3.5.查看结果、节点
hdfs dfs -cat output/*jps