本文目标
1.使用selenium实现账号密码登录qq空间
2.使用多线程爬取qq好友的说说评论点赞情况保存至本地
3.使用echarts将数据可视化
开源地址:qq好友关系爬虫
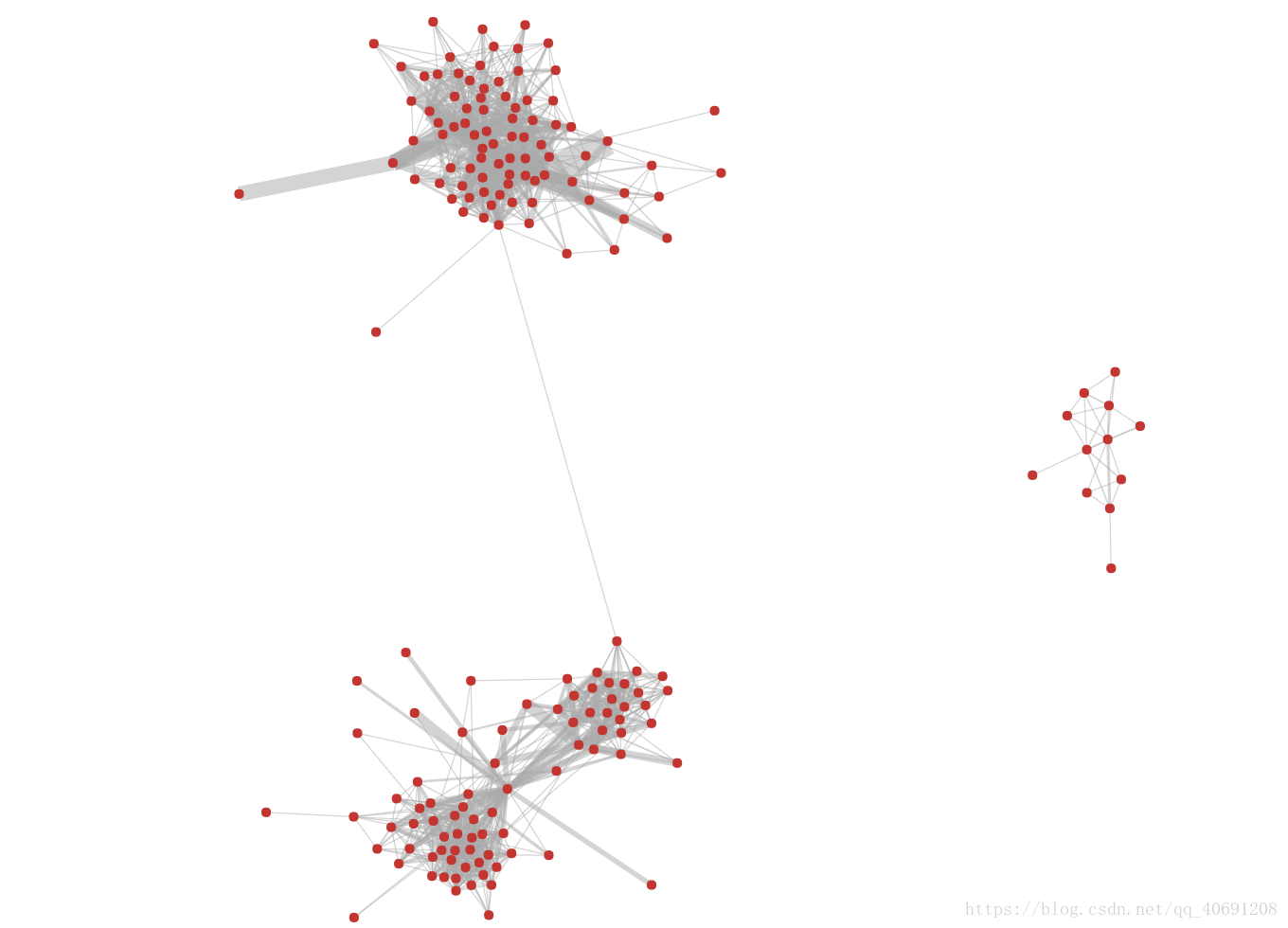
这是帮我同学做的他的qq好友关系网效果图,觉得他的关系网络比较好看,有特点,所以就用他的了,连线代表两人之间有联系,线的粗细代表两人关系的好的程度,为了显示效果和隐私就把名字给去了
最开始是看到了这篇博客,https://blog.csdn.net/u014271114/article/details/54973598,觉得得到好友关系网好像很有意思,无奈原博主并没有给出源码,自己瞎鼓捣了下,觉得有点思路,于是就开始做啦
一. 使用selenium登录获取好友列表
- selenium真的是非常好用,仿佛打开新世界大门,是模仿用户操作的一个自动化测试工具,想到之前模拟登录还要手动复制cookie真的是捞,关于selenium的安装配置看这篇文章:win10下配置python+selenium,看谷歌浏览器的版本号和对应的driver看这个: 版本号
1. 实现账号密码登录
注意要切换到登录的框架,代码如下
from selenium import webdriver
from time import sleep
import json
#chromedriver = 'C:/Users/13180/AppData/Local/Google/Chrome/Application/chromedriver.exe'
#driver = webdriver.Chrome(chromedriver)
driver = webdriver.Chrome()
driver.get('https://user.qzone.qq.com/你的qq/main')
#切换到登录的框架
driver.switch_to.frame('login_frame')
#找到账号密码登陆的地方
driver.find_element_by_id('switcher_plogin').click()
driver.find_element_by_id('u').send_keys('你的qq')
driver.find_element_by_id('p').send_keys('你的密码')
driver.find_element_by_id('login_button').click()
#保存本地的cookie
sleep(3)
cookies = driver.get_cookies()
cookie_dic = {}
for cookie in cookies:
if 'name' in cookie and 'value' in cookie:
cookie_dic[cookie['name']] = cookie['value']
with open('cookie_dict.txt', 'w') as f:
json.dump(cookie_dic, f)将这个保存为cookie.py,运行起来就能看到自动打开浏览器,然后会在目录下生成cookie_dict.txt的文件啦,接下来的访问都带上这个cookie就可以保持登录状态了
2. 获取qq好友列表
- 是通过这里得到qq好友列表,这种方法只能得到亲密度前200的好友

- 打开F12进入开发者中心,点击 好友 ,看到

发送的http请求到的url为 https://user.qzone.qq.com/proxy/domain/r.qzone.qq.com/cgi-bin/tfriend/friend_ship_manager.cgi
带的参数数据如下

返回的数据是类似json格式的,只不过多了头_Callback(),只需要简单的正则匹配一下把头给去了就行啦
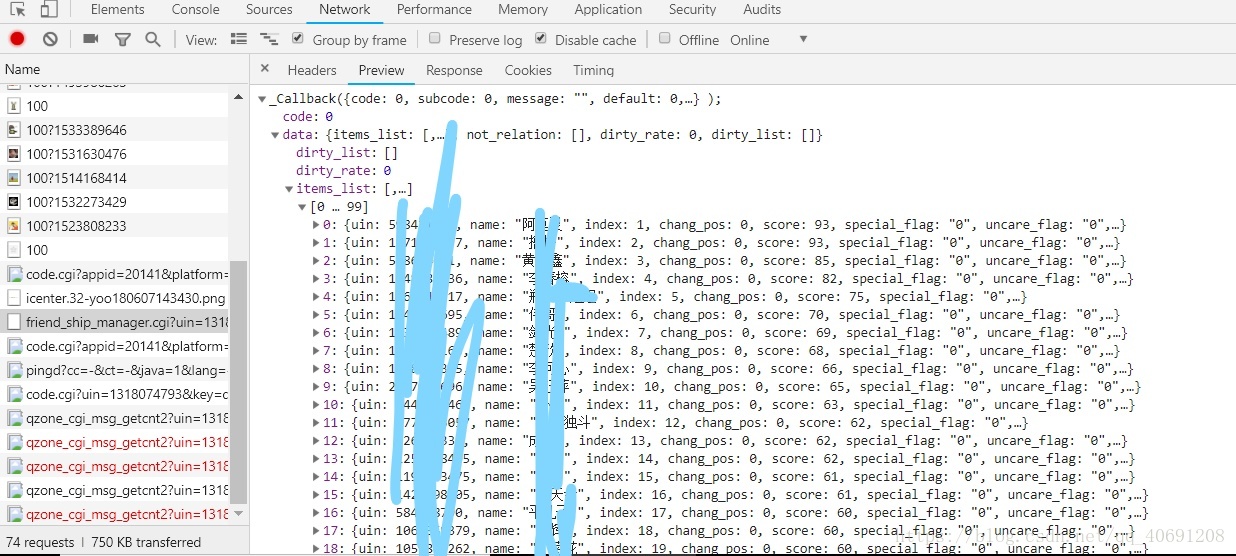
然后构造一个Qzone爬虫类,计算gtk,获得好友列表,
import urllib
import requests
import json
import re
class Qzone:
#算出来gtk
def get_gtk(self):
p_skey = cookie['p_skey']
h = 5381
for i in p_skey:
h += (h << 5) + ord(i)
g_tk = h & 2147483647
return g_tk
#得到uin
def get_uin(self):
uin = cookie['ptui_loginuin']
return uin
#只得到好友qqlist,以便后面判断共同好友
def get_qq(self):
qq_list = []
friend_list = self.get_friend()
for friend in friend_list:
qq_list.append(friend[1])
return qq_list
#找出好友qq和备注列表
def get_friend(self):
url_friend = 'https://user.qzone.qq.com/proxy/domain/r.qzone.qq.com/cgi-bin/tfriend/friend_ship_manager.cgi?'
g_tk = self.get_gtk()
uin= self.get_uin()
data = {
'uin': uin,
'do' : 1,
'g_tk': g_tk
}
data_encode = urllib.parse.urlencode(data)
url_friend += data_encode
res = requests.get(url_friend, headers = header, cookies = cookie)
#正则匹配出_Callback()里面的内容
friend_json = re.findall('\((.*)\)',res.text,re.S)[0]
#变成字典类型
friend_dict = json.loads(friend_json)
friend_result_list = []
#循环将好友的姓名qq号存入list中
for friend in friend_dict['data']['items_list']:
friend_result_list.append([friend['name'],friend['uin']])
#得到的好友list是[[name1,qqNum1],[name2,qqNum2],.....]格式的
return friend_result_list
if __name__ == '__main__':
qzone = Qzone()
#假装我是浏览器
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:61.0) Gecko/20100101 Firefox/61.0",
"Accepted-Language": "zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8"
}
with open('cookie_dict.txt','r') as f:
cookie = json.load(f)
#得到qq列表,
qq_list = qzone.get_qq()