Elasticsearch集群时增删改查是如何实现的?
本文不介绍ES API的如何使用,而是简单记录一下从一个请求发出后,elasticsearch服务器上的各个节点(或分片)是如何进行工作的。
Elasticsearch分布式集群
(图片来自网络)
首先了解一下es集群中三个名词:
cluster(集群):
一个节点(node)就是一个elasticsearch实例;一个集群可有一个或多个节点,他们的cluster.name相同,
集群中有一个节点会选举为主节点(master),他将管理集群级别的一些变更,例如新建或删除索引,新建或移除节点等。
主节点不会参与文档(document)级别的变更,所以主节点不会成为集群流量上的瓶颈。任何节点都可以成为主节点但主节点只有一个。
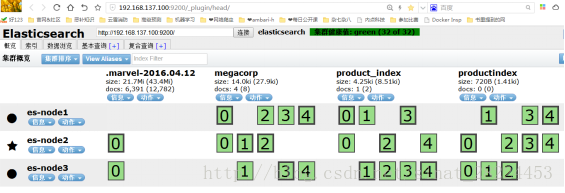
集群健康:GET /_cluster/health
green:所有主分片和复制分片都可用(上图中的集群就处于green的状态,因为32个主副分片都可用)
yellow:所有主分片都可用,不是所有的复制分片都可用
red:不是所有的主分片都可用。
node(节点):
上图中的es-node2就是主节点,负责与用户之间的请求,并管理索引或节点变更。
shards(分片):
一个分片就是es工作的最小单位,索引(index)只是一个指向一个或多个分片的“逻辑名称”,分片就是一个Lucene实例,是一个完整的搜索引擎,分片可以分为主分片(primary shard)和复制分片(replica shard),索引中的每一个文档都属于一个单独的主分片(也就是一个文档不会在两个主分片中重复出现),所以主分片的数量决定了你的能存储多少数据,复制分片只是主分片的副本,以防数据丢失并同时提供读请求。
当索引创建完成时,主分片的数量就确定了,但是副分片的数量可以调整。默认情况下一个索引会被分配5个主分片。上图中就分配了5个主分片和一个副分片(一个主分片有个一副分片),所以一个索引有10个副分片,如果节点多的话可以分配更多的副分片;
单一节点集群:
在一个空节点上创建一个索引,只分配3个主分片和一个副分片,此时副节点的状态是unassigned,即没还被分配。

双节点集群:
在单一节点上运行意味着有单点故障的危险,所以我们还需要启动另一个节点(es实例),只要两个节点有想同的cluster.name就可以,
可以在./config/elasticsearch.yml文件中配置,9300端口一般用作节点之间的通信,9200一般用作es集群和外部的通信;
这样就可以避免单点故障了,即使一个节点无法工作,副分片就会替代成为主分片继续工作。

多节点集群:
横向扩展,随着应用需求的增长,我们启动第三个节点,集群会重新组织分片,已经被重新分配以平衡负载。
这样每个节点就有两个分片,和之前三个少了一个意味着每个分片可以获得更多的资源(CPU,RAM,I/O),
由于每一个分片都是一个完整的搜索引擎,所以现在我们最多可以增加到6个几点。每个节点上的分片都可以100%的使用这个节点的资源
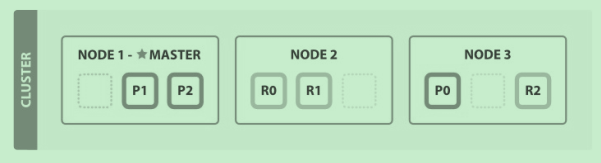
多节点集群扩展:
如果继续扩展节点呢?索引的主分片已经确定了,但是我们可以增加副分片啊
PUT /blogs/_settings
{
"number_of_replicas" : 2
}
副分片的数量由一个增加到两个。分片的总量就达到9个了(三个主,六个副),这样我们就可以再加入三个节点了,每个节点上一个分片(当然只是这个一个指的的只有一个这个索引的分片,可能还有其他索引的分片呢),
性能会比原始节点增加三倍。
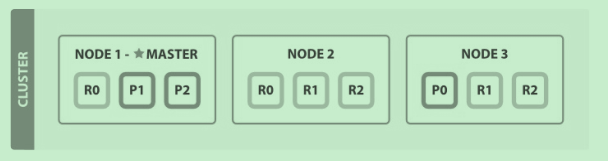
分布式增删改查如何实现?
路由文档到分片
es如何知道文档属于那个分片呢?根据一条算法:
shard = hash(routing) % number_of_primary_shards
rounting默认是_id,他通过hash函数的到一个数字,在除以主分片的数量取余数,所以shard永远都会在0到number_of_primary_shards之间,
这也是主分片确定之后就不可以更改的原因。
主分片和副分片如何交互的
我们有一个包含三个节点的集群,内有一索引blogs,改索引有两个主分片,每个主分片有两个副分片,如图
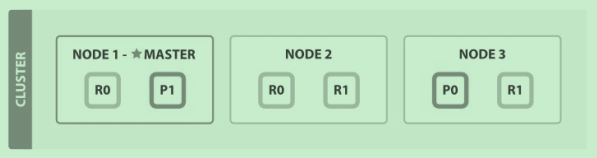
我们的请求可以发送给集群中的任意一个节点,任意一个节点都有能力处理请求。每个节点都只但文档所在节点(因为根据_id可以路由到啊),
也可以互相访问(在elasticsearch.yml可以设置)。我们将发送秦秋给node1,node1叫请求节点。
新建,索引和删除文档
他们都是write操作,需要在主分片上完成操作才能分配到其他的副分片上
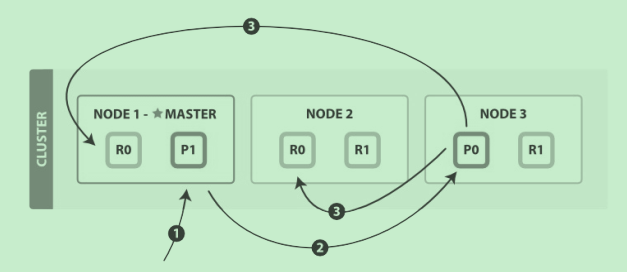
1. 客户端给 Node 1 发送新建、索引或删除请求。
2. 节点使用文档的 _id 确定文档属于分片 0 。它转发请求到 Node 3 ,分片 0 位于这个节
点上。
3. Node 3 在主分片上执行请求,如果成功,它转发请求到相应的位于 Node 1 和 Node 2 的
复制节点R 0上。当所有的复制节点报告成功, Node 3 报告成功到请求的节点,请求的节点
再报告给客户端。
注:replication属性可以设置为async,这样主分片处理完成后就返回给客户端,不会等复制分片。
但这个属性默认的是sync,也就是同步的,因为es已经够快了。
检索文档
文档能够从主分片或任意一个副分片被检索
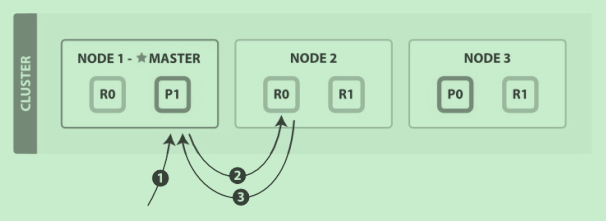
1. 客户端给 Node 1 发送get请求。
2. 节点使用文档的 _id 确定文档属于分片 0 。分片 0 对应的复制分片在三个节点上都
有。此时,它转发请求到 Node 2 。
3. Node 2 返回文档(document)给 Node 1 然后返回给客户端。
对于读请求,为了平衡负载,请求节点会为每个请求选择不同的分片——它会循环所有分片
副本。
可能的情况是,一个被索引的文档已经存在于主分片上却还没来得及同步到复制分片上。这
时复制分片会报告文档未找到,主分片会成功返回文档。一旦索引请求成功返回给用户,文
档则在主分片和复制分片都是可用的。
更新文档
update API 结合列前面的读和写操作
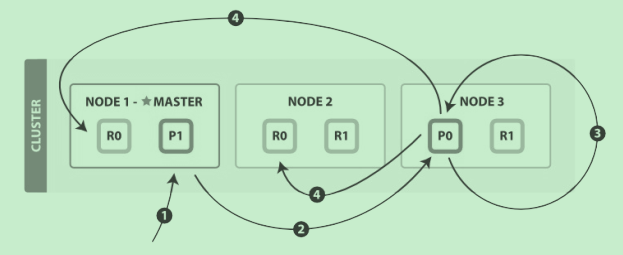
1. 客户端给 Node 1 发送更新请求。
2. 它转发请求到主分片所在节点 Node 3 。
3. Node 3 从主分片检索出文档,修改 _source 字段的JSON,然后在主分片上重建索引。
如果有其他进程修改了文档,它以 retry_on_conflict 设置的次数重复步骤3,都未成功
则放弃。
4. 如果 Node 3 成功更新文档,它同时转发文档的新版本到 Node 1 和 Node 2 上的复制节点
以重建索引。当所有复制节点报告成功, Node 3 返回成功给请求节点,然后返回给客户
端。
参考资料《Elasticsearch权威指南》