一、背景
去年写过一篇关于用c++实现mnist手写数字识别的神经网络的文章,当然,这里是最基本的bp神经网络。不知不觉一年多的时间就悄悄溜过去了。
《神经网络实现手写数字识别(MNIST)》:https://blog.csdn.net/xuanwolanxue/article/details/71565934
《再谈神经网络反向传播原理》:https://blog.csdn.net/xuanwolanxue/article/details/73187717
以上就是之前的相关文章链接。

其识别的正确率大约为94%,其训练用时大约90秒。 后来又学习了一段时间之后,知道了一些可以优化加速的方法,所以准备在原有c++代码的基础上实现加速优化。
二、原理
2.1 mnist数据集
mnist手写数字数据集,其实就是一堆灰度图像,大致如下图所示:

如果把图中的有色(黑色或灰色)部分看做是数字 1, 其他部分是数字0, 我们可以使用c++的console输出一个手写数字的形状(只打印有色的“1”, 忽略空白的”0”):

2.2 优化原理
我们都知道,bp神经网络的结构原理大致如下所示:
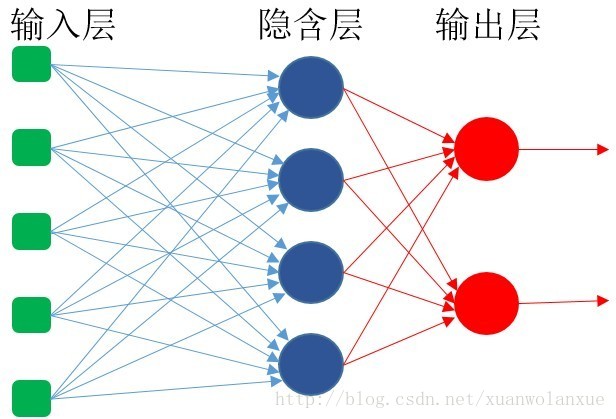
换句话说,他就是一个全连接神经网络,当前层的每一个神经单元(或神经“细胞”)的输入,都是前一层的所有数据节点。
mnist数据集的每一张图片的分辨率是28x28, 也就是说输入层会有784个数据节点,就像一个有784元素的数组,这里假设隐含层有200个神经单元。也就是说,每一个神经单元一次前向传播和反向传播,需要进行的计算量为:784此乘法和加法(这里还没有算经过sigmoid激活函数的计算量),一共200个神经单元,也就是说,要经过:784 * 200 = 156800 次的乘法和加法运算。这个计算量,对于非gpu加速来说,确实不小了,从之前的文章中得出的结果(训练一次需要90秒的时间)也可以看出这一点来。
从上一节中可以看出,mnist手写数字图片,有效(有颜色的数字部分)部分占整个图像的部分并不多,其他部分的数据都是”0”,这样的数据,对隐含层的输出没有任何贡献,反而只会浪费计算资源。所以我们要做的其中一个优化就是去除这部分的不必要的计算。
另一方面,这里的有效数据,其数据都可看做是”1”, “1” * weights[i] = weights[i], 小学都知道的数据原理,任何数乘以1都等于它自己本身, 换句话说这部分乘法计算也是不必要的。

总结一下,这次要做的优化包括两点:
- 去除输入mnist图像数据中“0”元素对应的所有计算
- 去除输入mnist图像有效的“1”元素对应的所有乘法运算
三、具体实现
3.1 优化方法
对于输入层,遍历mnist图像的784个元素,记录有效元素(数据”1”)的索引值到一个数组中
将这个索引数组作为隐含层的输入
隐含层的前向传播和反向传播,都只针对索引数组中对应的mnist元素进行计算
3.2 代码实现
3.2.1 mnist输入层数据处理
inline void preProcessInputData(const unsigned char src[],int size, InputIndex& indexs)
{/** src 数组为mnist图形的原始数据 */
for (int i = 0; i < size; i++)
{
if (src[i] >= 128) /**表示有效数据,此时将对应的索引值存入索引数组*/
{
indexs.push_back(i);
}
}
}3.2.2 训练神经网络相关的函数实现
- 首先是外部调用的训练API函数
bool bpNeuronNet::training(const int indexArray[], const size_t arraySize, const double targets[])
{/**indexArray: 索引数组
* arraySize: 索引数组的大小
* targets: 当前mnist元素对应的标签(也就是对应的正确答案)
*/
const double* prevOutActivations = NULL;
double* prevOutErrors = NULL;
trainUpdate(indexArray, arraySize, targets); /**训练模式(会更新最终输出误差)的前向传播 */
for (int i = mNumHiddenLayers; i >= 0; i--)
{/**进行反向传播 */
neuronLayer& curLayer = *mNeuronLayers[i];
/** get the out activation of prev layer or use inputs data */
if (i > 0)
{
neuronLayer& prev = *mNeuronLayers[(i - 1)];
prevOutActivations = prev.mOutActivations;
prevOutErrors = prev.mOutErrors;
memset(prevOutErrors, 0, prev.mNumNeurons * sizeof(double));
/** 更新当前层的权重(即学习),并反向传播误差 */
trainNeuronLayer(curLayer, prevOutActivations, prevOutErrors);
}
else
{
/** 更新当前层的权重(即学习),并反向传播误差 */
trainNeuronLayer(curLayer, indexArray, arraySize);
}
}
return true;
}- 训练模式下的前向传播
void bpNeuronNet::trainUpdate(const int indexArray[], const size_t arraySize,
const double targets[])
{/**indexArray: 索引数组
* arraySize: 索引数组的大小
* targets: 当前mnist元素对应的标签(也就是对应的正确答案)
*/
double* inputs;
/** 使用输入数据有效部分的索引数组来作为第一个隐含层的输入 */
updateNeuronLayer(*mNeuronLayers[0], indexArray, arraySize);
inputs = mNeuronLayers[0]->mOutActivations;
for (int i = 1; i < mNumHiddenLayers + 1; i++)
{/** 其他隐含层到输出层的前向传播*/
updateNeuronLayer(*mNeuronLayers[i], inputs);
inputs = mNeuronLayers[i]->mOutActivations;
}
/** get the activations of output layer */
neuronLayer& outLayer = *mNeuronLayers[mNumHiddenLayers];
double* outActivations = outLayer.mOutActivations;
double* outErrors = outLayer.mOutErrors;
int numNeurons = outLayer.mNumNeurons;
mErrorSum = 0;
/** 计算最终输出误差,以及平方差 */
/** update the out error of output neuron layer */
for (int i = 0; i < numNeurons; i++)
{
//double err = outActivations[i] - targets[i];
double err = targets[i] - outActivations[i];
outErrors[i] = err; /**记录输出层的误差 */
/** update the SSE(Sum Squared Error). (when this value becomes lower than a
* preset threshold we know the training is successful)
*/
mErrorSum += err * err; /** 记录最终的SSE */
}
}- 更新一层神经网络
void bpNeuronNet::updateNeuronLayer(neuronLayer& nl, const int indexArray[],
const size_t arraySize)
{ /**indexArray: 索引数组
* arraySize: 索引数组的大小
*/
int numNeurons = nl.mNumNeurons;
int numInputsPerNeuron = nl.mNumInputsPerNeuron;
double* curOutActivations = nl.mOutActivations;
//for each neuron
for (int n = 0; n < numNeurons; ++n)
{
double* curWeights = nl.mWeights[n];
double netinput = 0;
//for each weight
for (size_t k = 0; k < arraySize; k++)
{/**从索引数组中获取有效数据对应的索引值,直接将这个索引值对应的权重累加输出
* (因为有效数据为数据"1",所以这里省略了乘法计算)
*/
netinput += curWeights[indexArray[k]];
}
//add in the bias
netinput += curWeights[numInputsPerNeuron] * BIAS;
//The combined activation is first filtered through the sigmoid
//function and a record is kept for each neuron
curOutActivations[n] = sigmoidActive(netinput, ACTIVATION_RESPONSE);
}
}四、优化结果
其优化后的结果如下所示:

从上面可以看出,优化后的训练时间只有15秒多,比之优化之前,速度差不多提升了5倍多。
除此之外,在识别的准确率上也有提升,从之前的94%,到了优化后的95%。
注意 :本篇文章所提到的优化,是有局限的,适合当前的mnist手写数字识别,但不一定适合其他神经网络
五、附录
完整代码:
https://gitee.com/xunawolanxue.com/digital_recognition_with_neuron_network
注意:默认main.cpp中的测试函数,使用的是优化前的训练流程,要使用优化后的网络,需要将mian函数汇总的trainEpoch和testRecognition两个函数,分别改为使用trainEpoch2和testRecognition2