9.1 关系数据库系统的查询处理
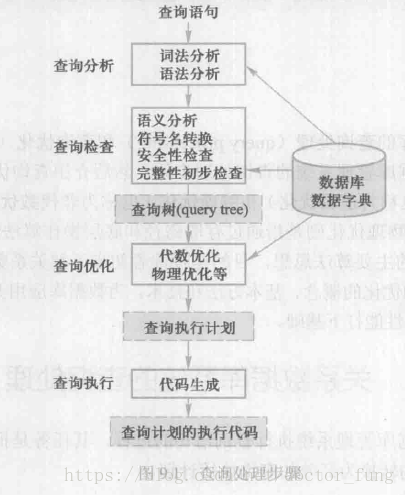
9.1.1 查询处理步骤
- 查询分析:词法分析、语法分析
- 查询检查:语义分析、是否有权限、是否破坏完整性、视图转换
- 查询优化:代数优化(逻辑优化)和物理优化(基于规则、代价、语义),生成查询计划树
- 查询执行:自底向上/自顶向下策略
9.1.2 实现查询操作的算法示例
- 选择操作的实现:全表扫描/索引扫描
- 连接操作的实现:查询处理中最常用最耗时的操作之一
- 嵌套循环算法:最简单最通用,实际上都是基于数据块的循环
- 排序-合并算法:常用与等值连接,尤其适合各个表已经排好序的情况。
第一步:如果参与连接的表没有排好序,根据连接属性排序
第二步:sorted_merge - 索引连接算法:根据表上已经建立好的索引,根据索引查找匹配的元组
- hash join 算法:等值连接,要求内存足够大,小表的hash表要全部能够放进内存。分成两个阶段
第一步,为小表建立hash表,根据连接属性作为hash码
第二步,对另外一张表的连接属性hash一遍,将匹配的元组连接起来
9.2 关系数据库系统的查询优化
- 在集中式数据库中,查询执行开销主要包括磁盘存取块数(IO代价)、处理机时间(CPU代价)以及查询的内存开销
- 计算查询代价时一般用查询处理读写的块数作为衡量单位
9.3 代数优化
9.3.1 关系代数表达式等价变换规则


9.3.2 查询树的启发式优化
- 选择运算应尽可能先做
- 把投影运算和选择运算同时进行:这两者都是一元操作,一个元组能不能成为结果只取决于其本身
- 把投影同其前或后的双目运算结合起来
- 把某些选择同在它前面要执行的笛卡儿积结合起来称为一个连接运算
- 找出公共子表达式
具体方法:

9.4 物理优化
- 基于规则的启发式优化
- 基于代价估算的优化
- 两者结合的优化方法
9.4.1 基于启发式规则的存取路径选择优化
选择操作的启发式规则:
小关系,全表扫描
大关系:
1. 若选择条件是主码,则可以选择主码索引,因为主码索引一般是被自动建立的
2. 若选择条件是非主属性的等职查询,并且选择列上有索引,如果选择比例较小(10%)可以使用索引扫描,否则全表扫描
3. 若选择条件是属性上的非等职查询或者范围查询,同上
4. 对于用and连接的合取选择条件,若有组合索引,优先用组合索引方法;如果某些属性上有一般索引,则用索引扫描,否则全表扫描
5. 对于用OR连接的析取选择条件,全表扫描
连接操作的启发式规则
1. 若两个表都已经按连接属性排序,则选用排序-合并算法
2. 若一个表在连接属性上有索引,则使用索引连接方法
3. 若其中一个表较小,则选用hash join
4. 最后可以使用嵌套循环,小表坐外表
9.4.2 基于代价估算的优化
- 统计信息:数据字典中存储了优化器需要的优化信息,包括基本表的元组总数、长度、占用块数,每个列的不同值的个数、最大/小值、是否有索引,索引的层数、个数、选择基数等
- 代价估算实例
