一、模型选择的方法及相关指标
1、损失函数通常有0-1损失,平方损失,绝对值损失和对数损失
2、通常用测试集对模型评估,评估的方法有留出法,交叉验证法,留一法,自助法
#留出法:直接将数据分为对立的三部分(也可以是两部分,此时训练集也是验证集),在训练集上训练模型,在验证集上选择模型,最后用测试集上的误差作为泛化误差的估计,数据集划分尽量保持数据分布一致,可以用分层采样来保持比例,通常采用多次随机划分,取平均值值作为留出法的评估结果
#交叉验证法:K折交叉验证将数据集分为个大小相同互不相交的子集,每次用其中一个子集作为测试集,求误差均值作为泛化误差的估计
# 留一法:是K=N时交叉验证集的一个特例,每次用一个样本测试,结果较准确,数据集大的时候计算量大
# 自助法:有放回的重复独立采样,总的数据集中约有63.2%的样本会出现在采样集中,数据集较小时使用合适
3、评估指标:
# 1.混淆矩阵
# 2.P-R曲线(查准率/精确率、查全率/召回率)以及precision和recall调和平均f1
# 3.ROC图(AUC值,真正率-假正率)AR=2AUC-1
# 4.准确率accuracy(类别不平衡时不适合使用此评估指标)
# 5.区分能力KS值等
二、slearn中模型选择的运用
(一)损失函数、数据集划分
#损失函数
from sklearn.metrics import zero_one_loss
from sklearn.metrics import log_loss
y_true = [1,1,1,1,1,1,0,0,0,0]
y_pred = [0,1,0,1,1,0,1,0,1,0]
print('zero_one_loss<fraction>',zero_one_loss(y_true, y_pred, normalize=True)) #normalize=True返回误分类样本的比例,否则返回数量
print('zero_one_loss<num>',zero_one_loss(y_true, y_pred, normalize=False)) #还有参数sample_weight,默认每个样本权重为1
y_true = [1,1,1,0,0,0]
y_pred_prob =[[0.1,0.9],
[0.2,0.8],
[0.3,0.7],
[0.7,0.3],
[0.8,0.2],
[0.9,0.1]] #最后一个代表预测为类别0的概率为0.9,预测为1的概率为0.1
print('log_loss average', log_loss(y_true, y_pred_prob, normalize=True))#normalize为true返回对数损失均值
print('log_loss total', log_loss(y_true, y_pred_prob, normalize=False))#为false返回对数误差的总和
#数据集切分,对于类别不平衡数据集,采用带有分层抽样设置的切分方法更优
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.model_selection import KFold,StratifiedKFold
from sklearn.model_selection import StratifiedShuffleSplit
from sklearn.model_selection import LeaveOneOut
from sklearn.model_selection import cross_val_score
x = [[1,2,3,4],
[11,12,13,14],
[21,22,23,24],
[31,32,33,34],
[41,42,43,44],
[51,52,53,54],
[61,62,63,64],
[71,72,73,74]]
y = [1,1,0,0,1,1,0,0]
x_train,x_test,y_train,y_test = train_test_split(x, y, test_size=0.4, random_state=0)
print('x_train',x_train)
print('x_test',x_test)
print('y_train',y_train)
print('y_test',y_test)
#stratify参数为一个数组或者None,如果不是None,将分层采样,采样的标记数组由此参数指定
x_train,x_test,y_train,y_test = train_test_split(x, y, test_size=0.4, stratify=y, random_state=0)
print('stratify x_train',x_train)
print('stratify x_test',x_test)
print('stratify y_train',y_train)
print('stratify y_test',y_test)
#从运行结果可看出,分层采样之后,训练集和测试集的类别比例与原始几乎相同
#K折交叉
x = np.array(x)
y = np.array(y)
#shuffle为False,切分之前不混洗数据(按顺序切分为4部分),若为True,切分之前混洗数据(随机分为4部分)
folder = KFold(n_splits=4, shuffle=False, random_state=42)
for train_index,test_index in folder.split(x,y):
x_train,x_test = x[train_index],x[test_index]
y_test,y_train = y[test_index],y[train_index]
print('x_train,x_test',x_train,x_test)
print('y_train,y_test',y_train,y_test)
#StratifiedShuffleSplit为分层采样的K折交叉切分,参数与KFold同
stra_folder = StratifiedKFold(n_splits=4, shuffle=True, random_state=42)
for train_index,test_index in stra_folder.split(x,y):
x_train = x[train_index]
x_test = x[test_index]
y_train = y[train_index]
y_test = y[test_index]
print('x_train',x_train)
print('y_train',y_train)
print('x_test',x_test)
print('y_test',y_test)
#从运行结果可看出,相比KFold,此方法切分数据集类别占比与原始数据集相同,适合分类不平衡数据集切分
#StratifiedShuffleSplit 为分层混洗数据集切分方法,在train_test_split(stratify=y)基础上切分前混洗数据
ss = StratifiedShuffleSplit(n_splits=4, test_size=0.4, random_state=0)
for train_index,test_index in ss.split(x,y):
x_train,x_test = x[train_index],x[test_index]
y_train,y_test = y[train_index],y[test_index]
#留一法
lo = LeaveOneOut()
for train_index,test_index in lo.split(x,y):
print('x_train',x[train_index])
print('x_test', x[test_index])
print('y_train',y[train_index])
print('y_test',y[test_index])
‘’‘
#cross_val_score是sklearn中的一个便利函数,它在指定的数据集上运行指定的学习器,
# 通过K折交叉验证获取最佳性能
# scoring 可为:'accuracy', 'adjusted_mutual_info_score', 'adjusted_rand_score',
# 'average_precision','completeness_score', 'explained_variance', 'f1', 'f1_macro', 'f1_micro',
# 'f1_samples', 'f1_weighted', 'fowlkes_mallows_score', 'homogeneity_score', 'mutual_info_score',
# 'neg_log_loss', 'neg_mean_absolute_error', 'neg_mean_squared_error', 'neg_mean_squared_log_error',
# 'neg_median_absolute_error', 'normalized_mutual_info_score', 'precision', 'precision_macro',
# 'precision_micro', 'precision_samples', 'precision_weighted', 'r2', 'recall', 'recall_macro',
# 'recall_micro', 'recall_samples', 'recall_weighted', 'roc_auc', 'v_measure_score'
’‘’
from sklearn.svm import LinearSVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import Lasso
from sklearn.datasets import load_breast_cancer
digitals = load_breast_cancer()
features = digitals.data
labels = digitals.target
print('labels',set(labels))
f1 = cross_val_score(LinearSVC(), features, labels, scoring='f1_weighted', cv=5)
print('f1',f1)
print('f1_mean',f1.mean())
#多分类问题precision_weighted,二分类直接precision, recall评估同
precision = cross_val_score(LinearSVC(),features, labels, scoring='precision_weighted', cv=5)
print('precision',precision.mean())
recall = cross_val_score(LinearSVC(), features, labels, scoring='recall_weighted', cv=5)
print('recall', recall.mean())
# auc只能用于二分类,不能用于多分类评估
roc_auc = cross_val_score(LinearSVC(), features, labels, scoring='roc_auc', cv=5)
print('roc_auc',roc_auc)
r2 = cross_val_score(Lasso(), features, labels, scoring='r2', cv=5)
print('r2',r2.mean())
#对数损失需能预测分类可能性,svm没有可能性预测功能,不能用此评估指标
logloss = cross_val_score(DecisionTreeClassifier(), features, labels, scoring='neg_log_loss', cv=5)
print('log-loss',logloss)
#对于回归任务还有平方误差等,见上面注释
(二)分类问题评估指标详解
#sklearn中提供了三种方式来评估模型的预测性能
# 1.学习器.score方法
# 2.model_selection(旧版本在cross_validation中)中模型评估工具如cross_val_score,上面已讲
# 3. metrics中各种评估指标
# 接下来演示metrics中提供的评估指标
1、分类问题评估指标主要有:
(1)accuracy(不适用于分类不平衡问题)
(2)精确率(查准率)precision
(3)召回率(查全率)recall
(4) f1(precision和recall调和平均)
(5)fbeta:fbeta 比precision多出参数beta,beta=1时,fbeta=f1;beta趋近于0时,fbeta趋近于precision;beta趋近+∞,fbeta趋近于Recall
#分类问题
from sklearn.metrics import accuracy_score,precision_score,recall_score,f1_score,fbeta_score
from sklearn.metrics import classification_report,confusion_matrix,precision_recall_curve
from sklearn.metrics import roc_auc_score,roc_curve
clf = DecisionTreeClassifier(min_samples_split=3)
clf.fit(x_train, y_train)
y_pred = clf.predict(x_test)
#(1)
acc = accuracy_score(y_test, y_pred, normalize=True)#normalize=True计算准确率,False则输出分类正确的数量
print('accuracy_score',accuracy_score)
#(2)pos_label指定正类标签,average值为字符串,默认二分类,此参数可以设置多分类问题评估
precision = precision_score(y_test, y_pred, pos_label=1, average='binary')
print('precision_score',precision_score)
# (3)recall
recall = recall_score(y_test, y_pred, pos_label=1,average='binary')#参数含义同precision_score
print('recall_score',recall_score)
#(4)f1 为precision 和recall调和平均
f1 = f1_score(y_test, y_pred, pos_label=1, average='binary') #参数含义同precision_score
print('f1_score',f1)
#(5)fbeta 比precision多出参数beta,beta=1时,fbeta=f1;beta趋近于0时,fbeta趋近于precision;beta趋近+∞,fbeta趋近于Recall
fbeta1 = fbeta_score(y_test, y_pred, beta=1.0, pos_label=1,average='binary')
fbeta0 = fbeta_score(y_test, y_pred, beta=0.001, pos_label=1,average='binary')
fbeta10000 = fbeta_score(y_test, y_pred, beta=10000.0, pos_label=1,average='binary')
print('fbeta0',fbeta0)
print('fbeta1',fbeta1)
print('fbeta10000',fbeta10000)
2、分类问题评估指标综合输出或可视化
(1)classification_report :生成分类评估指标precison、recall、f1-score的总体报告
#(6)classification_report 参数: labels:指定报告中出现的类别,target_names指定对应类别显示出来的名字,
# digits保留的小数位数
class_rep = classification_report(y_test, y_pred, target_names=['未患病','患病'], digits=5)
print('classification report:',class_rep)
结果

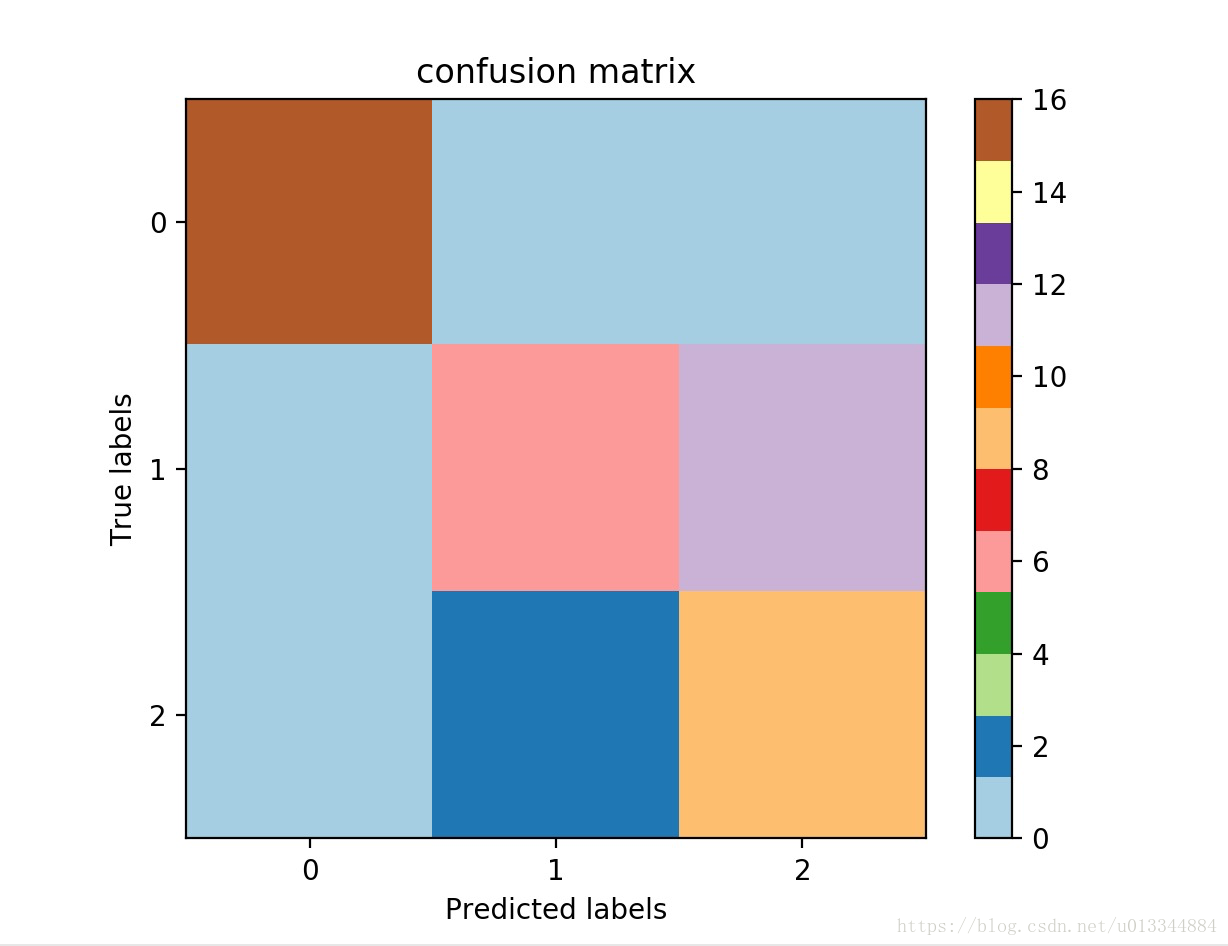
(2)混淆矩阵confusion matrix
#(7)confusion matrix
#混淆矩阵可视化
confusion_mat = confusion_matrix(labels_test, label_pred)
Plt_confusion_matrix(confusion_mat, len(set(labels))) #绘制混淆矩阵
#混淆矩阵可视化
def Plt_confusion_matrix(confusion_mat,num_class):
#用imshow函数画混淆矩阵
plt.imshow(confusion_mat, interpolation = 'nearest', cmap = plt.cm.Paired)
plt.title('confusion matrix')
plt.colorbar()
tick_marks = np.arange(num_class)
plt.xticks(tick_marks,tick_marks)
plt.yticks(tick_marks,tick_marks)
plt.ylabel('True labels')
plt.xlabel('Predicted labels')
plt.show()
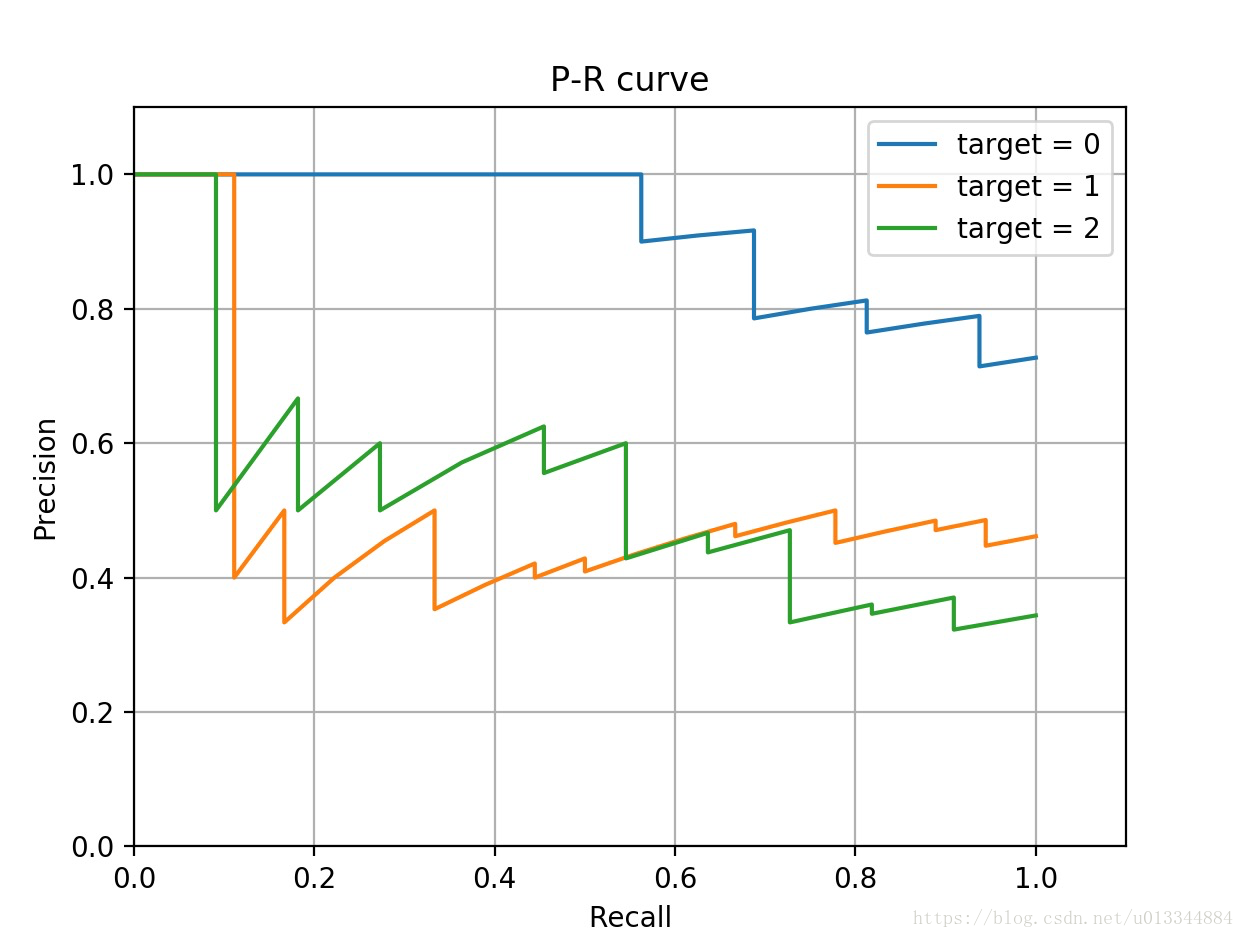
(3)P_R图
#(8)precision_recall_curve
from sklearn.datasets import load_iris,load_boston
from sklearn.svm import SVC
from sklearn.multiclass import OneVsRestClassifier
import matplotlib.pyplot as plt
from sklearn.preprocessing import label_binarize
iris = load_iris()
x = iris.data
y = iris.target
#二元化标记
y = label_binarize(y, classes=[0,1,2])#将类别0,1,2二值化,如类别1[0,1,0]
n_classes = y.shape[1]
#添加噪声
np.random.seed(0)
n_samples,n_features=x.shape
x = np.c_[x, np.random.randn(n_samples, 200*n_features)]
x_train,x_test,y_train,y_test = train_test_split(x, y, test_size=0.3,
shuffle=True, random_state=0)
#训练模型
clf = OneVsRestClassifier(SVC(kernel='linear', probability=True, random_state=0))
clf.fit(x_train, y_train)
y_score = clf.decision_function(x_test)
#获取P_R
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
precision = dict()
recall = dict()
for i in range(n_classes):
precision[i], recall[i], _ = precision_recall_curve(y_test[:,i], y_score[:,i])
ax.plot(recall[i], precision[i], label='target = %s'%i)
ax.set_xlabel("Recall")
ax.set_ylabel('Precision')
ax.set_title("P-R curve")
ax.legend(loc='best')
ax.set_xlim(0,1.1)
ax.set_ylim(0,1.1)
ax.grid()
plt.show()#至此分别绘制出三个类别为正例时的P-R图
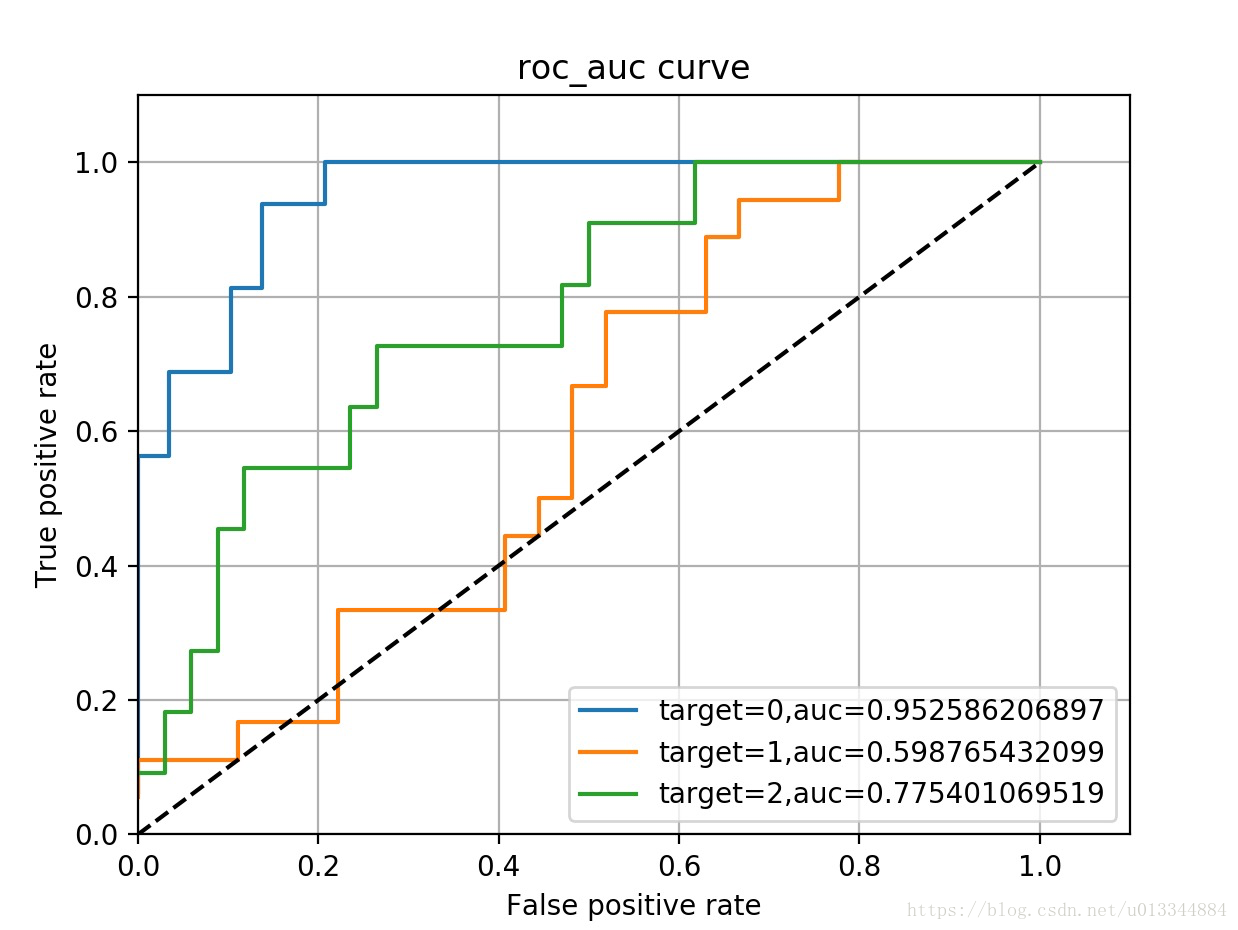
(4)AUC
# (9)roc_curve,二元化标记,添加噪声,训练模型与前面相同
iris = load_iris()
x = iris.data
y = iris.target
#二元化标记
y = label_binarize(y, classes=[0,1,2])
n_classes = y.shape[1]
#添加噪声
np.random.seed(0)
n_samples, n_features = x.shape
x = np.c_[x, np.random.randn(n_samples, 200*n_features)]
x_train,x_test,y_train,y_test = train_test_split(x, y, test_size=0.3, shuffle=True, random_state=0)
#训练模型,probability=True使预测结果可输出概率
clf = OneVsRestClassifier(SVC(kernel='linear', probability=True, random_state=0))
clf.fit(x_train, y_train)
y_prob = clf.decision_function(x_test)
#获取roc
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
tpr = dict()
fpr = dict()
roc_auc = dict()
for i in range(n_classes):
fpr[i], tpr[i], _ = roc_curve(y_test[:,i], y_prob[:,i]) #获取曲线坐标
roc_auc[i] = roc_auc_score(y_test[:,i], y_prob[:,i]) #计算auc值
ax.plot(fpr[i], tpr[i], label='target=%s,auc=%s'%(i,roc_auc[i]))
ax.plot([0,1],[0,1],'k--')
ax.set_xlabel('False positive rate')
ax.set_ylabel('True positive rate')
ax.set_title('roc_auc curve')
ax.legend(loc='best')
ax.set_xlim(0,1.1)
ax.set_ylim(0,1.1)
ax.grid() #这个语句有没有实际作图并未看到影响
plt.show()
3、回归问题评估指标
主要有绝对误差(mean_absolute_error),均方误差mean_squared_erro
#回归问题评估指标
from sklearn.linear_model import Lasso
from sklearn.metrics import mean_absolute_error,mean_squared_error
boston = load_boston()
x = boston.data
y = boston.target
x_train,x_test,y_train,y_test = train_test_split(x, y, test_size=0.3,
shuffle=True, random_state=0)
lo = Lasso(alpha=2.0)
lo.fit(x_train,y_train)
y_pred = lo.predict(x_test)
abs_error = mean_absolute_error(y_test, y_pred)
sq_error = mean_squared_error(y_test, y_pred)
print('mean_absolute_error=%s,mean_squared_error=%s'%(abs_error,sq_error))
#验证曲线:学习因为某个参数的不同而在测试集上预测的不同性能曲线
from sklearn.model_selection import validation_curve
iris = load_iris()
x = iris.data
y = iris.target
print(x.shape)
#获取验证曲线
param_name = 'C' #验证曲线中指定学习器要调整的参数
param_range = np.logspace(-2, 2) #要调整的参数的取值范围
train_scores, test_scores = validation_curve(LinearSVC(), x, y, param_name=param_name,
param_range=param_range, cv=10,
scoring='f1_weighted')
#对于每个C值,获取10折交叉验证上的得分的均值和方差
train_score_mean = np.mean(train_scores, axis=1)
train_socre_std = np.std(train_scores, axis=1)
test_score_mean = np.mean(test_scores, axis=1)
test_score_std = np.std(test_scores, axis=1)
#绘图
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
ax.semilogx(param_range, train_score_mean, label='Training f1_weighted', color='r')
ax.fill_between(param_range, train_score_mean - train_socre_std, train_score_mean + train_socre_std,
alpha=0.2, color='r')
ax.semilogy(param_range, test_score_mean, label='Testing f1_weighed', color='g')
ax.semilogy(param_range, test_score_mean-test_score_std, test_score_mean+test_score_std,
alpha=0.2, color='g')
ax.set_title('LinearSVC validation curve')
ax.set_xlabel('C')
ax.set_ylabel('f1-score')
ax.set_ylim(0,1.1)
ax.legend(loc='best')
plt.show()
#学习曲线:学习器因为数据集大小的不同而导致的学习器在训练集和测试集上预测的性能曲线
from sklearn.model_selection import learning_curve
x = x.repeat(10, axis=0)#增加数据量
y = y.repeat(10, axis=0)
#获取学习曲线
train_sizes = np.linspace(0.2, 0.9, endpoint=True, dtype='float')
abs_train_sizes, train_scores, test_scores = learning_curve(LinearSVC(),
x, y, train_sizes=train_sizes,
cv=3, scoring='accuracy',shuffle=True)
#对于每个C值,获取10折交叉验证上的得分的均值和方差
train_score_mean = np.mean(train_scores, axis=1)
train_score_std = np.std(train_scores, axis=1)
test_score_mean = np.mean(test_scores, axis=1)
test_score_std = np.std(test_scores, axis=1)
#绘图
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
ax.plot(abs_train_sizes, train_score_mean, label='Training accuracy', color='r')
ax.fill_between(abs_train_sizes, train_score_mean-train_socre_std,
train_score_mean+train_socre_std, alpha=0.2, color='r')
ax.plot(abs_train_sizes, test_score_mean, label='Testing accuracy', color='g')
ax.fill_between(abs_train_sizes,test_score_mean-test_score_std,
test_score_mean+test_score_std, alpha=0.2, color='g')
ax.set_title('Learning Curve with LinearSVC')
ax.set_xlabel('train_size')
ax.set_ylabel('accuracy')
ax.set_ylim(0,1.1)
ax.legend(loc='best')
plt.show()
参考
1.《Python机器学习经典实例》----Prateek Joshi