由于期货合约历史的分钟线数据过多,导入时间特别长,在这个过程中针对遇到的导入过慢的问题的解决思路如下:
1.首先,vnpy原本的loadcsv功能,是将csv文件读取以后,按行进行数据转换,按每一条的时间replaceone更新到mongodb中,由于本次是一次性向数据库插入数据,所以处理后通过insert_many的动作,进行一次性插入,提高插入数据的效率。
2.再后来还是速度比较慢,考虑通过多线程的方式,增加线程数量,来提高效率。最后增加了一个线程池,来完成多线程的插入。
3.以上动作插入后,还觉得有些慢,考虑是不是向mongodb插入的时候,多个同时插入大量数据造成的插入效率低,后来没有再验证优化了。
5.考虑每一条数据都需要进行格式化处理,形成vnpy的vtBar结构,是否可以通过dataframe的操作,一次性形成所需要的格式,提升处理效率
6.由于有些文件有几十M,pandas在读取的时候也会花费一定的时间,是否可以通过其它的方式进行读取,提高读取的效率
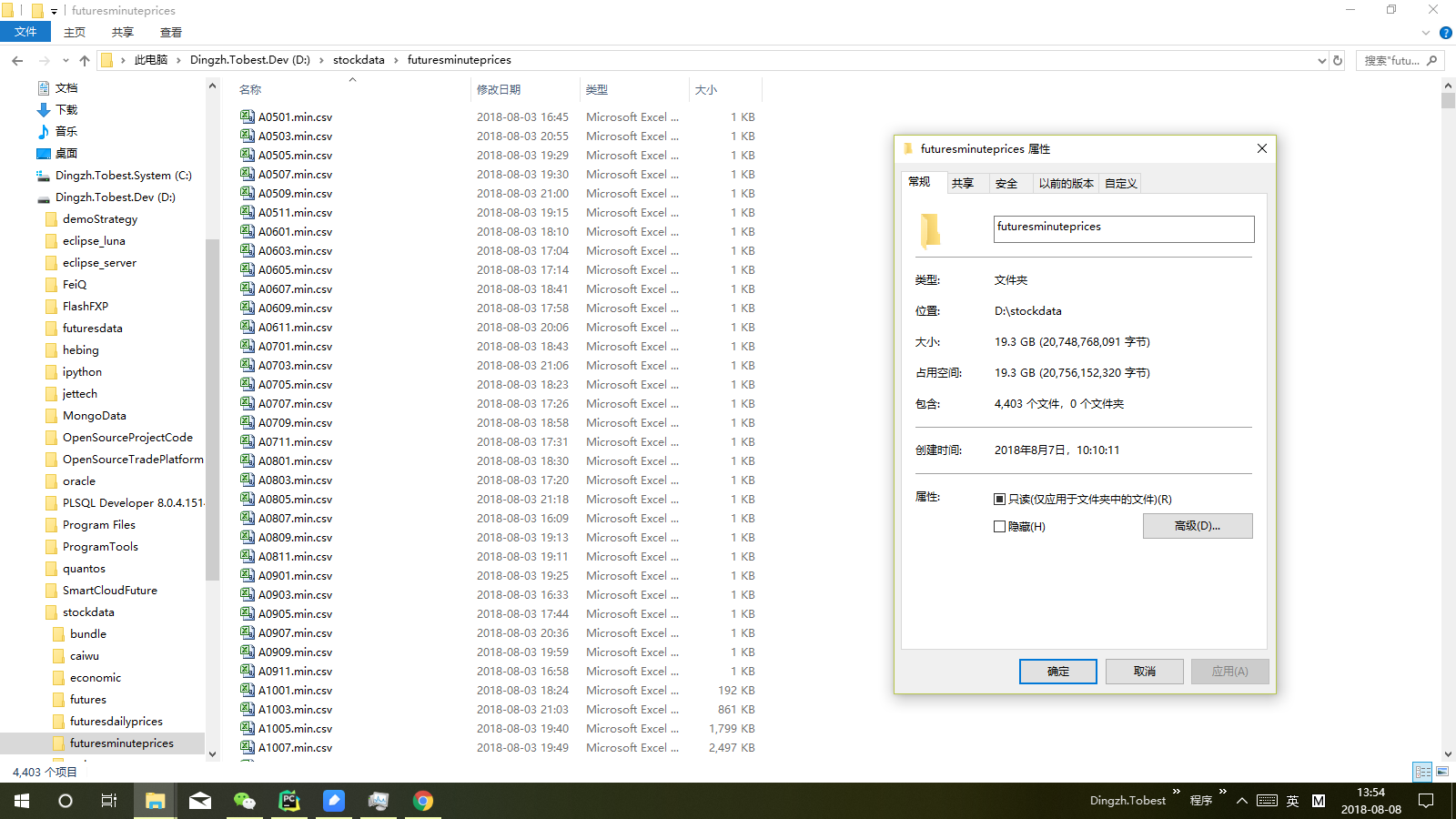
在进行前两步的优化后,导入效率比之前有较为名显的提升,4403的文件,接近20个G
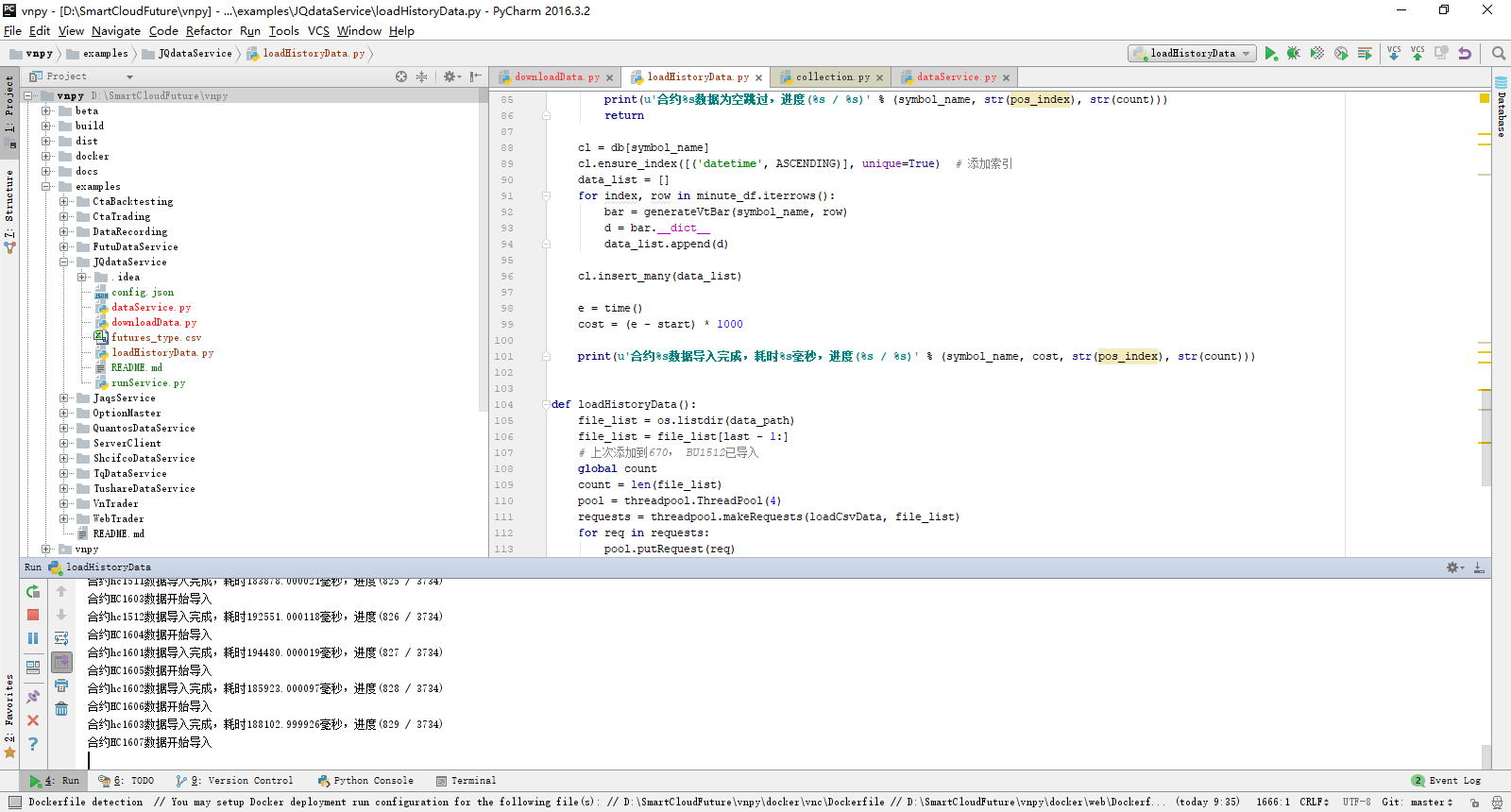
def loadHistoryData(): file_list = os.listdir(data_path) file_list = file_list[last - 1:] global pos pos = last # 上次添加到670, BU1512已导入 global count count = len(file_list) # 增加4个线程的线程池,多线程来提高导入效率 pool = threadpool.ThreadPool(4) requests = threadpool.makeRequests(loadCsvData, file_list) for req in requests: pool.putRequest(req) pool.wait() print('--------历史数据导入完成--------')
增加线程池的,提高处理效率
def loadCsvData(file_name): start = time() if file_lock.acquire(): symbol_name = file_name[0: -8] file_path = data_path + '\\' + file_name print(u'合约%s数据开始导入' % (symbol_name)) file_lock.release() if symbol_name[0: -4] in futures_symbol_map.keys(): symbol_name = futures_symbol_map[symbol_name[0: -4]] + symbol_name[-4:] minute_df = pd.read_csv(file_path, encoding='GBK') global pos if pos_lock.acquire(): pos += 1 pos_index = pos pos_lock.release() if minute_df.empty: print(u'合约%s数据为空跳过,进度(%s / %s)' % (symbol_name, str(pos_index), str(count))) return cl = db[symbol_name] cl.ensure_index([('datetime', ASCENDING)], unique=True) # 添加索引 data_list = [] for index, row in minute_df.iterrows(): bar = generateVtBar(symbol_name, row) d = bar.__dict__ data_list.append(d) cl.insert_many(data_list) e = time() cost = (e - start) * 1000 print(u'合约%s数据导入完成,耗时%s毫秒,进度(%s / %s)' % (symbol_name, cost, str(pos_index), str(count)))
一次性插入一个合约的全部数据,减少与mongodb的交互,提高插入效率