前言
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
Hadoop特点
- 高可靠性
- 高扩展性
- 高效性
- 高容错性
- 低成本
Hadoop核心架构
HDFS
对外部客户机而言,HDFS就像一个传统的分级文件系统。可以创建、删除、移动或重命名文件,等等。但是 HDFS 的架构是基于一组特定的节点构建的,这是由它自身的特点决定的。这些节点包括 NameNode(仅一个),它在 HDFS 内部提供元数据服务;DataNode,它为 HDFS 提供存储块。由于仅存在一个 NameNode,因此这是 HDFS 的一个缺点(单点失败)。
存储在 HDFS 中的文件被分成块,然后将这些块复制到多个计算机中(DataNode)。这与传统的 RAID 架构大不相同。块的大小(通常为 64MB)和复制的块数量在创建文件时由客户机决定。NameNode 可以控制所有文件操作。HDFS 内部的所有通信都基于标准的 TCP/IP 协议。
NameNode
NameNode 是一个通常在 HDFS 实例中的单独机器上运行的软件。它负责管理文件系统名称空间和控制外部客户机的访问。NameNode 决定是否将文件映射到 DataNode 上的复制块上。对于最常见的 3 个复制块,第一个复制块存储在同一机架的不同节点上,最后一个复制块存储在不同机架的某个节点上。
DataNode
DataNode 也是一个通常在 HDFS实例中的单独机器上运行的软件。Hadoop 集群包含一个 NameNode 和大量 DataNode。DataNode 通常以机架的形式组织,机架通过一个交换机将所有系统连接起来。Hadoop 的一个假设是:机架内部节点之间的传输速度快于机架间节点的传输速度。
准备工作
- hadoop-2.7.2.tar.gz (已编译)
- Linux机器 * 3
Linux环境准备
1:修改主机名(三台机器都要修改)
vim /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=Hadoop1
#其他机器依次修改为
HOSTNAME=Hadoop2
HOSTNAME=Hadoop32:修改host映射(三台机器都要修改)
vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.211.133 Hadoop1
192.168.211.134 Hadoop2
192.168.211.135 Hadoop33:配置免密登陆
#主
[Hadoop1] ssh-keygen
#先给自己一份
ssh-copy-id Hadoop1
#分发给其他机器
ssh-copy-id Hadoop2
ssh-copy-id Hadoop3
// ...4:访问hadoop官网

在这里可以下载Hadoop源码包
这里需要注意的是Hadoop官网上下载下来的包是32位的,需要自己编译成64位
5:关闭防火墙
service iptables stopHadoop 完全分布式集群部署
1:解压hadoop
tar -xzvf hadoop-2.7.2.tar.gz -C /usr/hadoop/2:配置Hadoop环境变量
cd /usr/hadoop/hadoop-2.7.2/etc/hadoop/
vim hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_121
3:配置Hadoop
指定hadoop使用的文件系统
mkdir -p /usr/data/hadoop指定hadoop运行时产生的文件路径
vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Hadoop1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/data/hadoop</value>
</property>
</configuration>4:指定HDFS副本数量,默认是3
vim hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Hadoop2:50090</value>
</property>5:指定mr运行时框架,这里指定在yarn上,默认是local
mv mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
<!-- 指定mr运行时框架,这里指定在yarn上,默认是local -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>6:指定yarn的leader地址
vim yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Hadoop1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>7:修改 slaves 写入三个主机节点
vim slaves
Hadoop1
Hadoop2
Hadoop3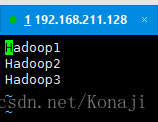
8:修改环境变量
vim /etc/profile
export HADOOP_HOME=/usr/hadoop/hadoop-2.7.2
export PATH=$HADOOP_HOME/bin:$PATH
source /etc/profile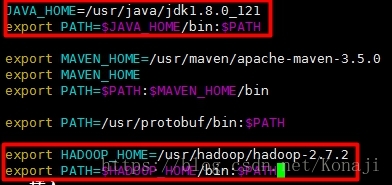
9:将Hadoop 发送到其他两台机器
scp -r /usr/hadoop/ root@Hadoop2:/usr/hadoop/
scp -r /usr/hadoop/ root@Hadoop3:/usr/hadoop/10:修改其他两台机器的环境变量(参考上面)
其他两台机器新增Hadoop运行时文件路径
mkdir -p /usr/data/hadoop
HDFS 格式化
启动Hadoop需要启动HDFS和YARN两个集群
注意:首次启动HDFS时,必须对其进行格式化操作,本质上是一些清理和准备工作,因为此时HDFS物理上是不存在的,格式化成功之后,不要再次进行格式化了,格式化操作在HDFS主节点操作
cd /
#执行
hdfs namenode -format
格式化成功之后可以查看节点信息
cd /usr/data/hadoop/dfs/name/current/
#可以查看到节点ID
vim VERSION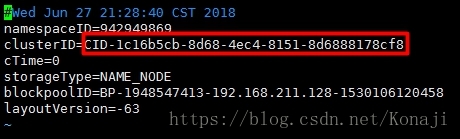
Hadoop 集群启动
启动hdfs
cd /usr/hadoop/hadoop-2.7.2/sbin/
./start-dfs.sh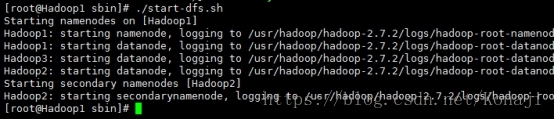
启动yarn
./start-yarn.sh
停止
停止
./stop-dfs.sh
./stop-yarn.sh
停止所有
./stop-all.sh (相当于停止dfs与yarn)访问Hadoop
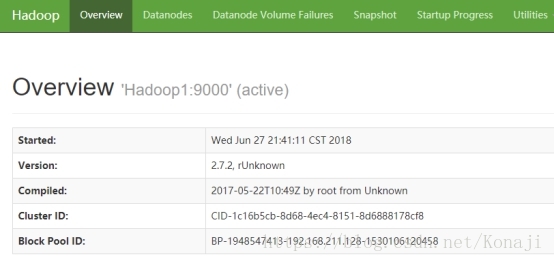
Hadoop 的 NameNode 默认是 50070 端口
Hadoop 的 ResourceManager 默认是8088端口
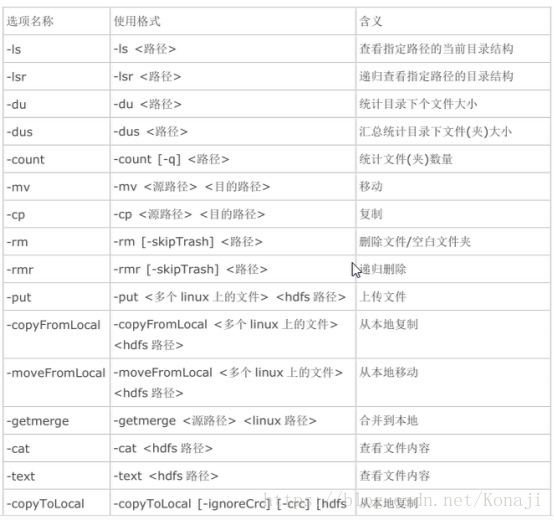
HDFS 常用命令
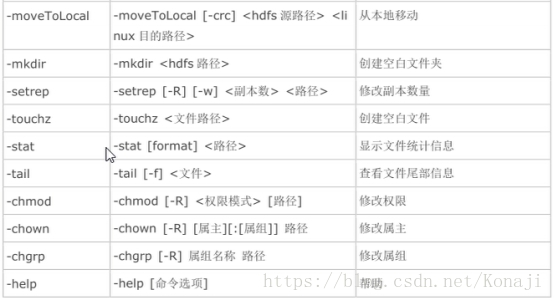
至此,Hadoop集群就搭建完成了。