本文根据最近学习机器学习书籍网络文章的情况,特将一些学习心得做了总结,详情如下.如有不当之处,请各位大拿多多指点,在此谢过。
一、概述
1、认识CART算法
本文介绍一种新的叫做CART(Classification and Regression Trees, 分类回归树)的树构建算法,这种算法既可以用于分类也可以用做回归。CART算法是一种二分递归分割技术,分割方法采用基于最小距离的基尼指数估计函数,将当前的样本集划分为两个子样本集,使得生成的每个非叶子节点都有两个分支。所以,CART算法生成的决策树是结构简洁的二叉树。
分类树是针对目标变量为离散型的变量,通过二叉树将数据分割成离散分类的方法;而回归树则是针对目标变量是连续型变量,通过选取最优分割特征的某个值,然后将数据根据大于或小于这个值来进行划分、进行树分裂,最终形成回归树。
2、树回归场景
上一篇文章《机器学习实践之预测数值型数据--回归》介绍了一些相当强大的方法,但这些方法创建模型时需要拟合所有的样本点(局部加权线性回归除外)。当数据拥有众多特征且这些特征之间关系十分复杂时,构建全局型模型就变得非常困难,且也略显笨重。在生活中遇到的问题大多数属于非线性的,不可能使用全局线性模型来拟合相关数据。
面对这类问题,一种可行的办法是将数据集切分成很多份易建模的数据,然后再使用上一篇介绍的线性回归技术进行建模。若首次切分后仍难以拟合线性模型则继续进行切分,在这种切分方式下, 树结构和回归法就变得是否有用。
3、树回归 基本原理
为成功构建出以分段常数为叶子节点的树,需要度量出数据的一致性。在决策树一篇文章中,我们应用了决策树进行分类,在给定节点计算数据的混乱度。而面对连续型数据的混乱度如何开展?首先计算所有数据的均值,然后计算每个数据的值与均值之间的差值,而面对正负差值,我们采用绝对值或者平方差值来替代。
4、树构建算法比较
在决策树一篇文章中,我们采用的是ID3算法。ID3算法的方法是每次都会选取当前的最佳特征来对数据进行划分,并且按照该特征的所有可能取值来进行划分。换句话说,如果该特征有4种取值,数据集将被切分为4份。一旦按照某特征进行划分后,该特征在后面的算法执行过程中将不再起作用,所以,有人会认为这种切分方式过于迅速。另外一种方法是二元切分法,即每次把数据切分为两份。如果数据的某特征值等于切分所要求的值,则这些数据就进入树的左子树,反之则进入树的右子树。
其实,ID3除了切分过于迅速外,还存在一个问题,那就是不能直接处理连续型特征。只能将连续型特征转换为离散型的,才可以在ID3中应用。但这种转换过程会破坏连续型变量之间的内在性质,而使用二元切分法则易于对树构建过程进行调整以便进行处理连续型特征。具体做法是:如果特征值大于给定值则走左子树,否则则走右子树。当然,二元切分法也节省了树的构建时间,但在这里其实意义不大,因为树构建一般是离线完成的,所以时间并不是我们关注的重点因素。
对于“如果特征值大于给定值则走左子树,否则则走右子树。”,笔者查看的书籍、网络文章都是同样的描述,这就看怎样取理解特征值和给定值的对象了。以笔者本文代码实现过程而言,在tree_predict()函数中,tree带来的feat_val就是特定值,而data['feat_idx']就是给定值,而feat_idx和feat_val均来自create_tree()函数传递。之所以在这里特别给出说明,是为了和下面代码规则保持一致。
CART算法是十分著名且记载广泛的树构建算法,它使用二元切分法处理连续型变量。对CART稍作修改就可以处理回归问题。在决策树那篇文章中,我们使用香农熵度量集合的无组织程度。如果使用其他方法来代替香农熵,就可以使用树构建算法完成回归。
5、 各种常见树构建算法划分分支方式
三种常见方式: ID3、C4.5、CART。其区别是在划分树的分支方式时:
(1)ID3是信息增益分支;
(2)C4.5是信息增益率分支;
(3)CART是GINI系数分支;
对于CART而言:在做分类工作时,采用GINI值作为节点分裂的依据;在做回归时,采用样本最小方差作为节点分裂的依据。
工程上总的来讲:
CART与C4.5主要区别在于分类结果,CART可以用于分类处理也可以进行回归处理,而C4.5只能用于分类处理;C4.5的子节点是可以多分的,而CART是由无数个二叉子节点组成。
拓展一下:以CART为基础的“树群” Random Forest;以回归树为基础的“树群”GBDT。
6、 特征和最佳分割点的选取
在使用决策树解决回归问题中我们需要不断的选取某一特征的一个值作为分割点来生成子树。选取的标准就是使得被分割的两部分数据能有最好的纯度。
- 对于离散型数据我们可以通过计算分割两部分数据的基尼不纯度的变化来判定最有分割点;
- 对于连续性变量我们通过计算最小平方残差,也就是选择使得分割后数据方差变得最小的特征和分割点。直观的理解就是使得分割的两部分数据能够有最相近的值。
7、 树分裂的终止条件
有了选取分割特征和最佳分割点的方法,树便可以依此进行分裂,但是分裂的终止条件是什么呢?
- 节点中所有目标变量的值相同, 既然都已经是相同的值了自然没有必要在分裂了,直接返回这个值就好了;
- 树的深度达到了预先指定的最大值;
- 不纯度的减小量小于预先定好的阈值,也就是之进一步的分割数据并不能更好的降低数据的不纯度的时候就可以停止树分裂了;
- 节点的数据量小于预先定好的阈值。
8、 树回归开发的一般流程
- 收集数据: 采用任意方法收集数据。
- 准备数据: 需要数值型数据,标称型数据被映射成二值型数据。
- 分析数据: 绘制出数据的二维可视化结果,以字典方式生成树。
- 训练算法: 大部分时间都花费在叶子节点树模型的构建上。
- 测试算法: 使用测试数据上的R^2值来分析模型效果。
- 使用算法: 使用训练出的树做预测,预测结果还可以用来做很多事情
9、 树回归的相关特性
优点: 可以对复杂和非线性的数据进行建模;
缺点: 结果不易理解。
适用数据类型: 数值型和标称型数据。
二、项目案例---回归树的实现
1、 项目概述
在简单数据集上生成一颗回归树。
2、 数据集样式
0.303697 1.170272
0.486698 1.68796
0.51181 1.979745
0.195865 0.06869
0.986769 4.052137
0.785623 3.156316
0.797583 2.95063
0.081306 0.068935
0.659753 2.854023、 加载数据部分
这里由于做树回归,自变量和因变量都放在同一个二维数组中。
def load_DataSet(filename):
"""
加载数据
"""
dataSet = []
with open(filename, 'r') as fs:
for line in fs:
line_Data = [float(dataSet) for dataSet in line.split()]
dataSet.append(line_Data)
return dataSet4、构建子树和叶子节点
树回归中再找到分割特征和分割值之后需要将数据进行划分以便构建子树或者叶子节点。
def split_DataSet(dataSet, feat_idx, feat_val):
"""
根据给定的特征编号和特征值对数据集进行分割。
"""
lData, rData = [], []
for data in dataSet:
if data[feat_idx] < feat_val:
lData.append(data)
else:
rData.append(data)
return lData, rData5、选取最佳分割特征和分割值
def choose_best_feature(dataSet, fLeaf, fErr, opt):
"""
选取最佳分割特征和特征值
dataSet -- 待分割的数据集
fLeaf -- 创建叶子节点的函数
fErr -- 计算数据误差的函数
opt -- 回归树参数
err_tolerance -- 最小误差下降值
n_tolerance -- 数据切分最小样本数
"""
a_DataSet = np.array(dataSet)
m, n = a_DataSet.shape
err_tolerance , n_tolerance = opt['err_tolerance'], opt['n_tolerance']
err = fErr(a_DataSet)
best_feat_idx, best_feat_val, best_err = 0, 0, float('inf')
for feat_idx in range(n-1):
values = a_DataSet[:, feat_idx]
for val in values:
lData, rData = split_DataSet(a_DataSet.tolist(), feat_idx, val )
if len(lData) < n_tolerance or len(rData) < n_tolerance:
continue
new_err = fErr(lData) +fErr(rData)
if new_err < best_err:
best_feat_idx = feat_idx
best_feat_val = val
best_err = new_err
if abs(err-best_err) < err_tolerance:
return None, fLeaf(a_DataSet)
#检查样本量是不是太小
lData, rData = split_DataSet(a_DataSet, best_feat_idx, best_feat_val)
if len(lData) < n_tolerance or len(rData) < n_tolerance:
return None, fLeaf(a_DataSet)
return best_feat_idx, best_feat_val 其中,停止选取的条件有两个: 一个是当分割的子数据集的大小小于一定值;一个是当选取的最佳分割点分割的数据的方差减小量小于一定的值。
fLeaf是创建叶子节点的函数引用,不同的树结构此函数也是不同的,例如本部分的回归树,创建叶子节点就是根据分割后的数据集平均值,而对于模型树来说,此函数返回值是根据数据集得到的回归系数。fErr是计算数据集不纯度的函数,不同的树模型该函数也会不同,对于回归树,此函数计算数据集的方差来判定数据集的纯度,而对于模型树来说我们需要计算线性模型拟合程度也就是线性模型的残差平方和。
6、 回归树生成
def create_tree(dataSet, fLeaf, fErr, opt= None):
"""
递归创建树结构
dataSet -- 待划分的数据集
fLeaf -- 创建叶子节点的函数
fErr --- 计算误差的错误率
opt --- 回归树的参数
err_tolerance-- 最小误差下降值
n_tolerance -- 数据切分最小样本数
"""
if opt == None:
opt = {'err_tolerance' : 1,'n_tolerance' : 4}
feat_idx, feat_val = choose_best_feature(dataSet, fLeaf, fErr, opt)
if feat_idx == None:
return feat_val
tree = {'feat_idx': feat_idx, 'feat_val': feat_val}
lData, rData = split_DataSet(dataSet, feat_idx, feat_val)
lTree = create_tree(lData, fLeaf, fErr ,opt)
rTree = create_tree(rData, fLeaf, fErr ,opt)
tree['left'] = lTree
tree['right'] = rTree
return tree7、其余函数
"""
回归树实现
"""
import uuid
from functools import namedtuple
import numpy as np
import matplotlib.pyplot as plt
def fLeaf(dataSet):
"""
计算给定数据的叶节点数值,这里是均值
"""
M_dataSet = np.array(dataSet)
return np.mean(M_dataSet[:, -1])
def fErr(dataSet):
"""
计算数据集的误差。
"""
E_dataSet = np.array(dataSet)
m,_ = E_dataSet.shape
return np.var(E_dataSet[:, -1])*E_dataSet.shape[0]
def get_nodes_edges(tree, root_node = None):
"""
返回所有节点和边
"""
Node = namedtuple('Node' , ['id', 'label'])
Edge = namedtuple('Edge', ['start', 'end'])
nodes, edges = [], []
if type(tree) is not dict:
return nodes, edges
if root_node is None:
label = '{}:{}'.format(tree['feat_idx'],tree['feat_val'])
root_node = Node._make([uuid.uuid4(), label])
nodes.append(root_node)
for sub_tree in (tree['left'], tree['right']):
if type(sub_tree) is dict:
node_label = '{}:{}'.format(sub_tree['feat_idx'], sub_tree['feat_val'])
else:
node_label = '{: .2f}'.format(sub_tree)
sub_node = Node._make([uuid.uuid4(), node_label])
nodes.append(sub_node)
sub_nodes , sub_edges = get_nodes_edges(sub_tree, root_node = sub_node)
nodes.extend(sub_nodes)
edges.extend(sub_edges)
return nodes, edges
def dotify(tree):
"""
获取Graphviz Dot文件内容
"""
content = 'disgraph decision tree {\n'
nodes, edges = get_nodes_edges(tree)
for node in nodes:
content += ' "{}" [label="{}"] ; \n'.format(node.id, node.label)
for edge in edges:
start, end = edge.start,edge.end
content += ' "{}" -> "{}"; \n' .format(start.id, end.id)
content += '}'
return content
def tree_predict(data, tree):
"""
根据给定的回归树预测数据值
"""
if type(tree) is not dict:
return tree
feat_idx, feat_val = tree['feat_idx'], tree['feat_val']
if data[feat_idx] < feat_val:
sub_tree = tree['left']
else:
sub_tree = tree['right']
return tree_predict(data, sub_tree)
if '__main__' == __name__:
dataFile = 'ex0.txt'
dataSet = load_DataSet(dataFile)
tree = create_tree(dataSet, fLeaf, fErr, opt={'n_tolerance':4, 'err_tolerance' : 1})
dotfile = '{}.dot' .format(dataFile.split('.')[0])
with open(dotfile, 'w') as fs:
content = dotify(tree)
fs.write(content)
a_DataSet = np.array(dataSet)
#绘制散点
plt.scatter(a_DataSet[:, 0], a_DataSet[:, 1])
#绘制回归曲线
x = np.linspace(0, 1, 50)
y = [ tree_predict([i] , tree) for i in x]
plt.plot(x, y , c = 'r')
plt.show()8、 执行代码后效果如下
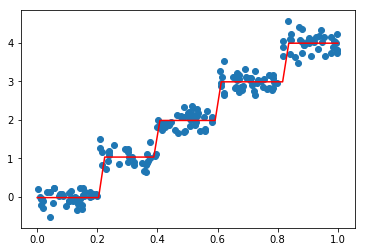
三、 树剪枝
一棵树如果节点过多,表明该模型可能对数据进行了 “过拟合”。
通过降低决策树的复杂度来避免过拟合的过程称为 剪枝(pruning)。在函数 chooseBestSplit() 中提前终止条件,实际上是在进行一种所谓的 预剪枝(prepruning)操作。另一个形式的剪枝需要使用测试集和训练集,称作 后剪枝(postpruning)。
1、 预剪枝(prepruning)
顾名思义,预剪枝就是及早的停止树增长,在构造决策树的同时进行剪枝。
所有决策树的构建方法,都是在无法进一步降低熵的情况下才会停止创建分支的过程,为了避免过拟合,可以设定一个阈值,熵减小的数量小于这个阈值,即使还可以继续降低熵,也停止继续创建分支。但是这种方法实际中的效果并不好。
2、 后剪枝
决策树构造完成后进行剪枝。剪枝的过程是对拥有同样父节点的一组节点进行检查,判断如果将其合并,熵的增加量是否小于某一阈值。如果确实小,则这一组节点可以合并一个节点,其中包含了所有可能的结果。合并也被称作 塌陷处理 ,在回归树中一般采用取需要合并的所有子树的平均值。后剪枝是目前最普遍的做法。
对树进行塌陷处理: 我们对一棵树进行塌陷处理,就是递归将这棵树进行合并返回这棵树的平均值。
def collapse(tree):
"""
对一棵树进行塌陷处理,得到给定树结构的平均值
"""
if not_tree(tree):
return tree
lTree, rTree = tree['left'], tree['right']
return (collapse(lTree) + collapse(rTree))/23、 代码实现过程
#树剪枝
def not_tree(tree):
"""
判断是否是一棵树结构
"""
return type(tree) is not dict
def collapse(tree):
"""
对一棵树进行塌陷处理,得到给定树结构的平均值
"""
if not_tree(tree):
return tree
lTree, rTree = tree['left'], tree['right']
return (collapse(lTree) + collapse(rTree))/2
def postPrune(tree, test_data):
"""
根据测试数据对树结构进行后剪枝处理
"""
if not_tree(tree):
return tree
if not test_data:
return collapse(tree)
lTree, rTree = tree['left'], tree['right']
if not_tree(lTree) and not_tree(rTree):
#分割数据用于测试
lData, rData = split_DataSet(test_data, tree['feat_idx'], tree['feat_val'])
#分别计算合并前和合并后的测试数据误差
err_no_merge = (np.sum(np.array(lData)-lTree)**2 + np.sum(np.array(rData)-rTree) **2)
err_merge = np.sum((np.array(test_data) - (lTree + rTree)/2) **2)
if err_merge < err_no_merge :
print('merged')
return (lTree + rTree)/2
else:
tree
tree['left'] = postPrune(tree['left'] , test_data)
tree['right'] = postPrune(tree['right'] , test_data)
return tree4、 执行结果
执行下面代码
test_data = load_DataSet('ex2test.txt')
pruned = postPrune(tree , test_data)得到结果
merged四、 项目案例---树模型的实现
1、模型树简介
用树来对数据建模,除了把叶节点简单地设定为常数值之外,还有一种方法是把叶节点设定为分段线性函数,这里所谓的 分段线性(piecewise linear) 是指模型由多个线性片段组成。
决策树相比于其他机器学习算法的优势之一在于结果更易理解。很显然,两条直线比很多节点组成一棵大树更容易解释。模型树的可解释性是它优于回归树的特点之一。另外,模型树也具有更高的预测准确度。
上一部分叶子节点上放的是分割后数据的平均值并以他作为满足条件的样本的预测值,本部分我们将在叶子节点上放一个线性模型来做预测。也就是指我们的树是由多个线性模型组成的,显然会比强行用平均值来建模更有优势。
- 模型树使用多个线性函数来做回归比用多个平均值组成一棵大树的模型更有可解释性;
- 而且线性模型的使用可以使树的规模减小,毕竟平均值的覆盖范围只是局部的,而线性模型可以覆盖所有具有线性关系的数据;
- 模型树也具有更高的预测准确度。
2、 创建模型树
模型树和回归树的思想是完全一致的,只是在生成叶子节点的方法以及计算数据误差(不纯度)的方式不同。在模型树里针对一个叶子节点我们需要使用分割到的数据进行线性回归得到线性回归系数而不是简单的计算数据的平均值。不纯度的计算也不是简单的计算数据的方差,而是计算线性模型的残差平方和。
为了能为叶子节点计算线性模型,我们还需要实现一个标准线性回归函数linear_regression, 相应模型树的fErr和fleaf的Python实现。
def linear_regression(dataSet):
"""
获取标准线性回归函数
"""
dataSet = np.matrix(dataSet)
#分割数据并添加常数列
X_ori, y = dataSet[:, :-1] , dataSet[:, -1]
X_ori, y = np.matrix(X_ori) , np.matrix(y)
m, n = X_ori.shape
X = np.matrix(np.ones((m, n+1)))
X[:, 1:] = X_ori
#回归系数
w = (X.T * X).I*X.T*y
return w, X, y3、 在分段线性数据上应用模型树
执行如下代码:
tree = create_tree(dataSet, fLeaf, fErr, opt={'err_tolerance': 0.1, 'n_tolerance': 4})
tree得到:
{'feat_idx': 0, 'feat_val': 0.30440099999999998, 'left': matrix([[ 3.46877936],
[ 1.18521743]]), 'right': matrix([[ 1.69855694e-03],
[ 1.19647739e+01]])}4、执行模型树代码及效果
#树模型
def linear_regression(dataSet):
"""
获取标准线性回归函数
"""
dataSet = np.matrix(dataSet)
X_ori, y = dataSet[:, :-1] , dataSet[:, -1]
X_ori, y = np.matrix(X_ori) , np.matrix(y)
m, n = X_ori.shape
X = np.matrix(np.ones((m, n+1)))
X[:, 1:] = X_ori
#回归系数
w = (X.T * X).I*X.T*y
return w, X, y
def fLeaf(dataSet):
"""
计算给定数据集的线性相关系数
"""
w, _, _ = linear_regression(dataSet)
return w
def fErr(dataSet):
"""
对给定数据集进行回归并计算误差
"""
w , X , y = linear_regression(dataSet)
y_prime = X*w
return np.var(y_prime - y)
def get_nodes_edges(tree, root_node = None):
"""
返回树中所有节点和边
"""
Node = namedtuple('Node', ['id', 'label'])
Edge = namedtuple('Edge' , [ 'start' , 'end'])
nodes , edges = [] , []
if type(tree) is not dict:
return nodes , edges
if root_node is None:
label = '{}:{}'.format(tree['feat_idx'] , tree['feat_val'])
root_node = Node._make([uuid.uuid4() , label])
nodes.append(root_node)
for sub_tree in (tree['left'] , tree['right']):
if type(sub_tree) is dict:
node_label = '{}:{}'.format(sub_tree['feat_idx'] , sub_tree['feat_val'])
else:
node_label = '{}'.format(np.array(sub_tree.T).tolist()[0])
sub_node = Node._make([uuid.uuid4() , node_label])
nodes.append(sub_node)
edge = Edge._make([root_node, sub_node])
edges.append(edge)
sub_nodes , sub_edges = get_nodes_edges(sub_tree, root_node = sub_node)
nodes.extend(sub_nodes)
edges.extend(sub_edges)
return nodes, edges
def dotify(tree):
"""
获取树的Graphvize Dot 文件中的内容
"""
content = 'digraph decision_tree {\n'
nodes ,edges = get_nodes_edges(tree)
for node in nodes:
content = ' "{}" -> [label ="{}"; \n]'.format(node.id , node.label)
for edge in edges:
start , end = edge.start , edge.end
content = ' "{}" -> [label = "{}"; \n]'.format(start.id , end.id)
content += '}'
return content
def tree_predict(data , tree):
if type(tree) is not dict:
w = tree
y = np.matrix(data) * w
return y[0 , 0]
feat_idx , feat_val = tree['feat_idx'] ,tree['feat_val']
if data[feat_idx+1] < feat_val:
return tree_predict(data, tree['left'])
else:
return tree_predict(data, tree['right'])
if '__main__' == __name__:
dataSet = load_DataSet('exp2.txt')
tree = create_tree(dataSet , fLeaf ,fErr , opt = {'err_tolerance':0.1 , 'n_tolerance': 4})
#生成树模型Dot文件
with open('exp2.dot' , 'w') as fs:
fs.write(dotify(tree))
dataSet = np.array(dataSet)
#绘制散点图
plt.scatter(dataSet[: , 0], dataSet[: , 1])
#绘制回归曲线
x = np.sort(dataSet[: , 0])
y = [tree_predict([1.0]+[i] , tree) for i in x]
plt.plot(x, y , c = 'r')
plt.show()

5、 模型结果分析
由3、4步骤可知,该代码以0.30441为界划分了两个模型,如下:
- 当x < 0.304的时候,使用线性模型y = 3.47 + 1.19x来回归
- 当x > 0.304的时候,使用线性模型y = 0.0017 + 1.20x来回归
五、 项目案例----树回归和标准回归的比较
1、 项目概述
前面介绍了模型树、回归树和一般的回归方法,下面测试一下哪个模型最好。
这些模型将在某个数据上进行测试,该数据涉及人的智力水平和自行车的速度的关系。当然这些数据也是杜撰的。
2、样本数据样式
训练数据集 bikeSpeedVsIq_train.txt部分数据如下:
1 52.525471
16 127.060008
9 101.639269
14 146.41268
15 144.157101
17 152.69991
19 136.669023
21 166.971736
21 165.467251
3 38.455193
6 75.557721
4 22.1717633、 实现过程如下
from regression_tree import *
from model_tree import linear_regression
def get_corrcoef(X, Y):
# X Y 的协方差
cov = np.mean(X*Y) - np.mean(X)*np.mean(Y)
return cov/(np.var(X)*np.var(Y))**0.5
if '__main__' == __name__:
# 加载数据
data_train = load_data('bikeSpeedVsIq_train.txt')
data_test = load_data('bikeSpeedVsIq_test.txt')
dataset_test = np.matrix(data_test)
m, n = dataset_test.shape
testset = np.ones((m, n+1))
testset[:, 1:] = dataset_test
X_test, y_test = testset[:, :-1], testset[:, -1]
# 获取标准线性回归模型
w, X, y = linear_regression(data_train)
y_lr = X_test*w
y_test = np.array(y_test).T
y_lr = np.array(y_lr).T[0]
corrcoef_lr = get_corrcoef(y_test, y_lr)
print('linear regression correlation coefficient: {}'.format(corrcoef_lr))
# 获取模型树回归模型
tree = create_tree(data_train, fleaf, ferr, opt={'err_tolerance': 1,
'n_tolerance': 4})
y_tree = [tree_predict([x], tree) for x in X_test[:, 1].tolist()]
corrcoef_tree = get_corrcoef(np.array(y_tree), y_test)
print('regression tree correlation coefficient: {}'.format(corrcoef_tree))
plt.scatter(np.array(data_train)[:, 0], np.array(data_train)[:, 1])
# 绘制线性回归曲线
x = np.sort([i for i in X_test[:, 1].tolist()])
y = [np.dot([1.0, i], np.array(w.T).tolist()[0]) for i in x]
plt.plot(x, y, c='r')
# 绘制回归树回归曲线
y = [tree_predict([i], tree) for i in x]
plt.plot(x, y, c='y')
plt.show()
4、 运行效果展示即分析

linear regression correlation coefficient: 0.9434684235674762
regression tree correlation coefficient: 0.9780307932704089由模型结果展示可知,因为R^2越接近于1,模型的效果越佳,所以从数字结果来看,树回归模型好于线性回归模型;图中黄色部分为树回归曲线,红色部分为线性回归曲线,显然也同样证明,树回归模型好于线性回归模型。
六、 Python 中 GUI 的使用
1、 使用 Python 的 Tkinter 库创建 GUI
如果能让用户不需要任何指令就可以按照他们自己的方式来分析数据,就不需要对数据做出过多解释。其中一个能同时支持数据呈现和用户交互的方式就是构建一个图形用户界面(GUI,Graphical User Interface),如图所示。
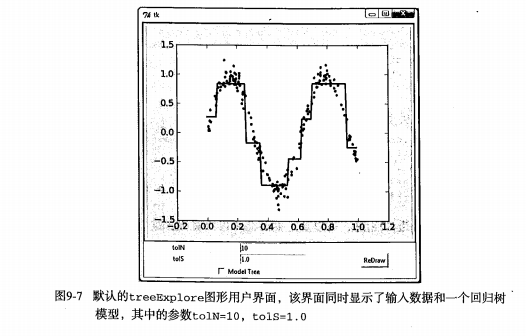
2、用 Tkinter 创建 GUI
Python 有很多 GUI 框架,其中一个易于使用的 Tkinter,是随 Python 的标准版编译版本发布的。Tkinter 可以在 Windows、Mac OS和大多数的 Linux 平台上使用。
3、集成 Matplotlib 和 Tkinter
MatPlotlib 的构建程序包含一个前端,也就是面向用户的一些代码,如 plot() 和 scatter() 方法等。事实上,它同时创建了一个后端,用于实现绘图和不同应用之间接口。
通过改变后端可以将图像绘制在PNG、PDF、SVG等格式的文件上。可以设置后端为 TkAgg (Agg 是一个 C++ 的库,可以从图像创建光栅图)。TkAgg可以在所选GUI框架上调用Agg,把 Agg 呈现在画布上。我们可以在Tk的GUI上放置一个画布,并用 .grid()来调整布局。
4、用GUI构建的模型树示例图
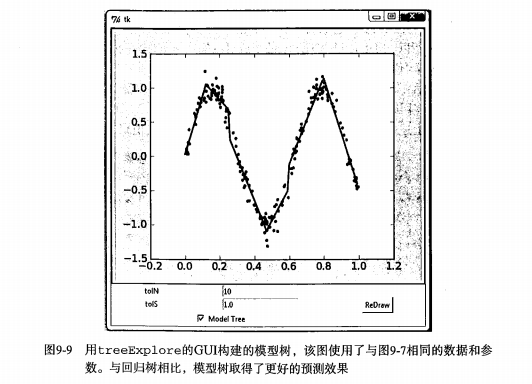
七、 小结
数据集中经常包含一些复杂的相互关系,使得输入数据和目标变量之间呈现非线性关系。对于这些复杂的关系建模,一种可行的方式是使用树来对预测值分段, 包括分段常数或分段直线。一般采用树结构来对这些数据进行建模。相应地,若叶节点使用的模型是分段常数则称为回归树,若叶节点使用的模型是线性回归方程则称为模型树。
CART算法可以用于构建二元树并处理离散型或连续型数据的切分。若使用不同的误差准则,就可以通过CART算法构建回归树和模型树。该算法构建出的树会倾向于对数据过拟合。一颗过拟合的树往往十分复杂,剪枝技术的出现就是为了解决这个问题。两种剪枝方法分别是预剪枝(在树的构建过程中就剪枝)和后剪枝(在树构建完毕后进行剪枝),预剪枝更有效但需要用户定义一些参数。
Tkinter 是Python的一个GUI工具包。虽然并不是唯一包,但它更常用。利用Tkinter可以轻松绘制各种部件并合理安排它们的位置。另外,可以为Tkinter构造一个特殊的部件来显示Matplotlib绘出的图形。所以,Matplotlib和Tkinter集成可以构造出更加强大的GUI,用户可以以更加自然的方式来探索机器学习算法的奥妙。