为什么要在单机下配置
我机器很多,可以为所欲为的,为什么还要挤到一台机器上去?
最主要的原因是:elasticsearch单实例最大内存是建议不超过32G的,现在的服务器一般内存都比较大了,想充分使用机器的内存就要多开实例
怎么配置
0.环境
系统:centos 6
版本:elasticsearch5.6,通过rpm安装。1.新建目录
切换到elasticsearch用户,新建节点目录用于存放配置,日志,es数据,这里建两个节点来测试。
su elasticsearch
cd ~
mkdir node1 node2 es1 es2 logs logs22.准备配置文件
将elasticsearch.yml jvm.options log4j2.properties 这三个文件分别复制到刚才新建的node1 和 node2 目录下。
如果是用rpm安装elasticsearch,这三个文件在/etc/elasticsearch下可以找到,切换到root用户操作下。
cp /etc/elasticsearch/elasticsearch.yml /home/elasticsearch/node1
cp /etc/elasticsearch/elasticsearch.yml /home/elasticsearch/node2
cp /etc/elasticsearch/jvm.options /home/elasticsearch/node1
cp /etc/elasticsearch/jvm.options /home/elasticsearch/node2
cp /etc/elasticsearch/log4j2.properties /home/elasticsearch/node1
cp /etc/elasticsearch/log4j2.properties /home/elasticsearch/node2
#对于cp到多个地方的操作没找到优雅的方法,不建议去用for,xargs,管道这些,所以多操作几次了。
#改下权限
chown elasticsearch:elasticsearch -R /home/elasticsearch/node*3.配置多节点
注意以下参数,分别对应修改即可
cluster.name: 保证集群名称一致,再启动时相同集群名称的节点会自动加入到集群中
node.name: 节点名称,自己定义,只要相互不冲突就可以;
http.port: 端口号,只要不冲突就行;修改后如下:
node1配置
cluster.name: erp
node.name: node1
path.data: /home/elasticsearch/es
path.logs: /home/elasticsearch/logs
http.port: 9201
bootstrap.system_call_filter: false
http.cors.enabled: true
http.cors.allow-origin: "*"node2配置
cluster.name: erp
node.name: node2
path.data: /home/elasticsearch/es2
path.logs: /home/elasticsearch/logs2
http.port: 9202
bootstrap.system_call_filter: false
http.cors.enabled: true
http.cors.allow-origin: "*"怎么启动
elasticsearch 5.X启动的参数和之前有点小差别,命令如下
#启动node1
/usr/share/elasticsearch/bin/elasticsearch -Epath.conf=/home/elasticsearch/node1 -d
#启动node2
/usr/share/elasticsearch/bin/elasticsearch -Epath.conf=/home/elasticsearch/node2 -d
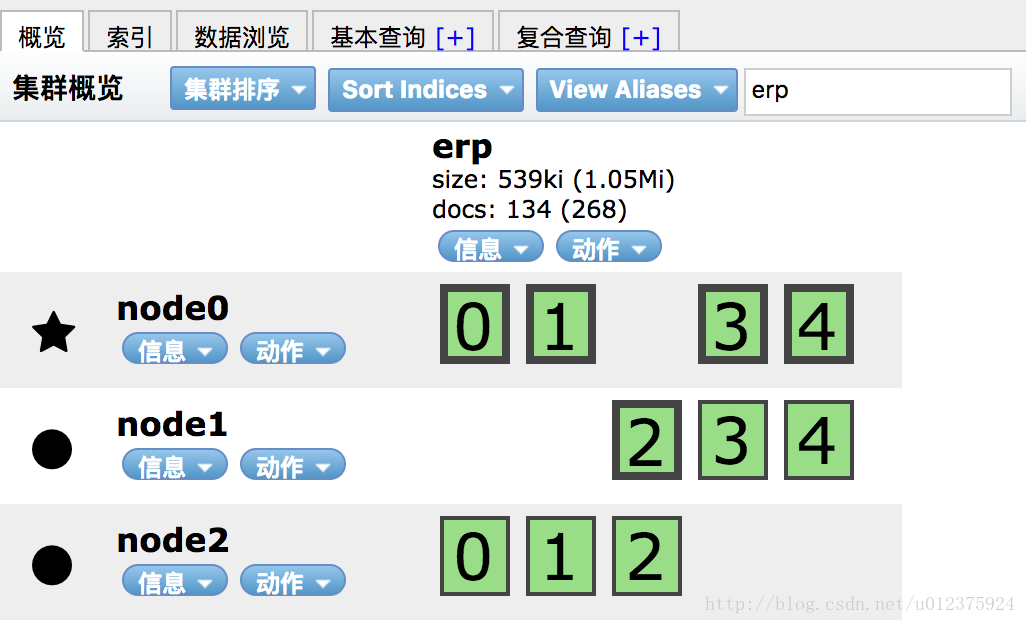
#建议先不加d参数跑下,确认能正常启动后再加。启动完成后,node1和node2节点就自动加入原先的node节点了,比如通过head可以看到,集群状态也变为绿色了,如图: