目录
在web开发中,文件上传功能是很普遍的,我们最常见的就是上传图片了,还有上传Excel,利用apache的组件可以很方便实现文件上传功能。
上传原理
- 上传:我们把需要上传的资源,发送给服务器,在服务器上保存下来。
- 下载:下载某一个资源时,将服务器上的该资源发送给浏览器。
- 难点:服务器端获取资源时比较麻烦
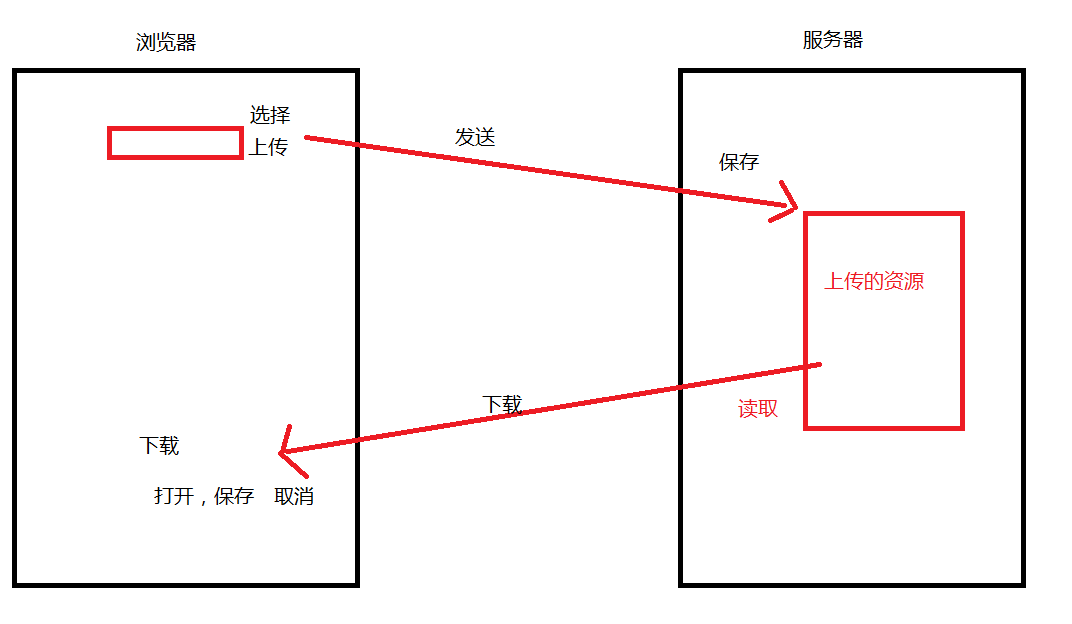
上传:要将磁盘上的文件上传到服务器上去,首先应该有一个管理磁盘文件的工具,当我们上传文件时,还要有一个负责上传文件和解析文件的工具,这两个工具就是apache提供的jar包,commons-fileupload组件和commons-io组件。
准备需要上传的文件
先准备一个jsp页面。此页面中有一个form表单,此表单有如下三个特征。
- 表单的method必须是post
- 表单的enctype属性值必须是multipart/form-data
- 表单中提供
<input type="file"/>
<form action="${pageContext.request.contextPath}/servlet/UploadServlet2" method="post" enctype="multipart/form-data">
name:<input type="text" name="name"/><br/>
file1:<input type="file" name="photo"/><br/>
file2:<input type="file" name="photo"/><br/>
<input type="submit" value="上传"/>
</form>注意:enctype=multipart/form-data:该属性表明发送的请求体的内容是多表单元素的,通俗点讲,就是有各种各样的数据,可能有二进制数据,也可能有表单数据,等等,所以使用该属性也进行其区分,发送的格式如下(使用火狐中的Firebug插件进行捕捉的信息。):

使用multipart/form-data会有一个boundary属性,来用将提交的表单数据进行分隔,以用来让服务器知道哪个是我们上传的资源,哪个是普通的表单数据。
开始上传
如果不使用commons-fileupload如果不使用commons-fileupload插件来帮我们处理上传后的数据而让我们自己手动处理的话,也是可以的,但是十分麻烦,因为我们需要将所有的请求体获取到,然后通过字符串的分割,通过boundary这个属性进行分割,然后一步步获取到我们想要的数据。
使用commons-fileupload进行处理上传内容。我们需要建立一个servlet,在此servlet中准备上传所需要的类,也就是DiskFileItemFactory类和ServletFileUpload类;DiskFileitemFactory类负责管理磁盘文件,ServletFileUpload类负责上传和解析文件,如下是具体代码实现:
@Override
protected void service(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException {
//处理中文乱码问题
req.setCharacterEncoding("utf-8");
resp.setContentType("text/html;charset=utf-8");
//检查请求是否是multipart/form-data类型
if(!ServletFileUpload.isMultipartContent(req)){ //不是multipart/form-data类型
throw new RuntimeException("表单的enctype属性不是multipart/form-data类型!!");
}
//创建上传所需要的两个对象
DiskFileItemFactory factory = new DiskFileItemFactory();
ServletFileUpload sfu = new ServletFileUpload(factory); //解析器依赖于工厂
//创建容器来接受解析的内容
List<FileItem> items = new ArrayList<FileItem>();
//将上传的文件信息放入容器中
try {
items = sfu.parseRequest(req);
} catch (FileUploadException e) {
e.printStackTrace();
}
//遍历容器,处理解析的内容;封装两个方法,一个处理普通表单域,一个处理文件的表单域
for(FileItem item : items){
if(item.isFormField()){
handleFormField(item);
}else{
handleUploadField(item);
}
}
}解析上传文件并保存到服务器
下面是两个需要解析的方法:
- 处理FormField的方法(也就是表单中普通的字段);
- 处理UploadField的方法(也就是需要上传的文件)。
/**
* 处理普通表单域(FormField)
* @param item
*/
private void handleFormField(FileItem item) {
String fieldName = item.getFieldName(); //得到表单域的name的值
String value = "";
try {
value = item.getString("utf-8"); //得到普通表单域中所输入的值
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
//打印到控制台
System.out.println("fieldName:"+fieldName+"--value:"+value);
}/**
* 处理文件的表单域
* @param item
*/
private void handleUploadField(FileItem item) {
String fileName = item.getName(); //得到上传文件的文件名
if(fileName!=null && !"".equals(fileName)){
//控制只能上传图片
if(!item.getContentType().startsWith("image")){
return;
}
//向控制台打印文件信息
System.out.println("fileName:"+fileName);
System.out.println("fileSize:"+item.getSize());
}
//上传文件存储路径
String path = this.getServletContext().getRealPath("/files");
//创建子目录
File childDirectory = getChildDirectory(path);
//写入服务器或者磁盘
try {
item.write(new File(childDirectory.toString(),UUID.randomUUID()+"_"+fileName));
} catch (Exception e) {
e.printStackTrace();
}
}为了防止上传的文件都是在同一个目录下,对于以后的遍历查找十分的不便,所以为上传的文件创建子目录
/**
* 按照时间创建子目录,防止一个目录中文件过多,不利于以后遍历查找
* @param path
* @return
*/
private File getChildDirectory(String path) {
Date currTime = new Date();
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
String time = sdf.format(currTime);
File file = new File(path,time);
if(!file.exists()){
file.mkdirs();
}
return file;
}
/**
* 按照hashcode创建分目录 防止一个文件夹下面的上传文件过度
* @param path
* @return
*/
<pre name="code" class="java">
private String genChildDirectory(String realPath, String fileName) {
int hashCode = fileName.hashCode();
int dir1 = hashCode & 0xf;
int dir2 = (hashCode & 0xf0) >> 4;
String str = dir1 + File.separator + dir2;
File file = new File(realPath, str);
if (!file.exists()) {
file.mkdirs();
}
return str;
}
上面两个方法一个是根据日期来创建目录,一个是根据hashcode创建目录。
文件上传的限制要求
- 限制文件的类型,如,只能上传图片
//控制只能上传图片
if(!item.getContentType().startsWith("image")){
return;
}- 限制上传文件的大小
//创建上传所需要的两个对象
DiskFileItemFactory factory = new DiskFileItemFactory();
ServletFileUpload sfu = new ServletFileUpload(factory); //解析器依赖于工厂
//限制单个文件的大小
sfu.setFileSizeMax(1024*10);
//限制上传的总文件大小
sfu.setSizeMax(1024*200);
//创建容器来接受解析的内容
List<FileItem> items = new ArrayList<FileItem>();
//将上传的文件信息放入容器中
try {
items = sfu.parseRequest(req);
}catch(FileUploadBase.FileSizeLimitExceededException e){
resp.getWriter().write("文件大小不能超过10kb");
}catch (FileUploadException e) {
e.printStackTrace();
}其他的一些配置
DiskFileItemFactory有两个方法:setSizeThreshold和setRepository
setRepository方法用于设置当上传文件尺寸大于setSizeThreshold方法设置的临界值时,将文件以临时文件形式保存在磁盘上的存放目 录。有一个对应的获得临时文件夹的 File getRespository() 方法。
注意:当从没有调用此方法设置临时文件存储目录时,默认采用系统默认的临时文件路径,可以通过系统属性 java.io.tmpdir 获取。如下代码:
System.getProperty(“java.io.tmpdir”);
Tomcat系统默认临时目录为“<tomcat安装目录>/temp/”。setSizeThreshold方法用于设置是否将上传文件已临时文件的形式保存在磁盘的临界值(以字节为单位的int值),如果从没有调用该方法设置此临界值,将会采用系统默认值10KB。对应的getSizeThreshold() 方法用来获取此临界值。
附:Apache文件上传组件在解析上传数据中的每个字段内容时,需要临时保存解析出的数据,以便在后面进行数据的进一步处理(保存在磁盘特定位置或插入数据库)。因为Java虚拟机默认可以使用的内存空间是有限的,超出限制时将会抛出“java.lang.OutOfMemoryError”错误。如果上传的文件很大,例如800M的文件,在内存中将无法临时保存该文件内容,Apache文件上传组件转而采用临时文件来保存这些数据;但如果上传的文件很小,例如600个字节的文件,显然将其直接保存在内存中性能会更加好些。
下载
实现下载有两种方式:
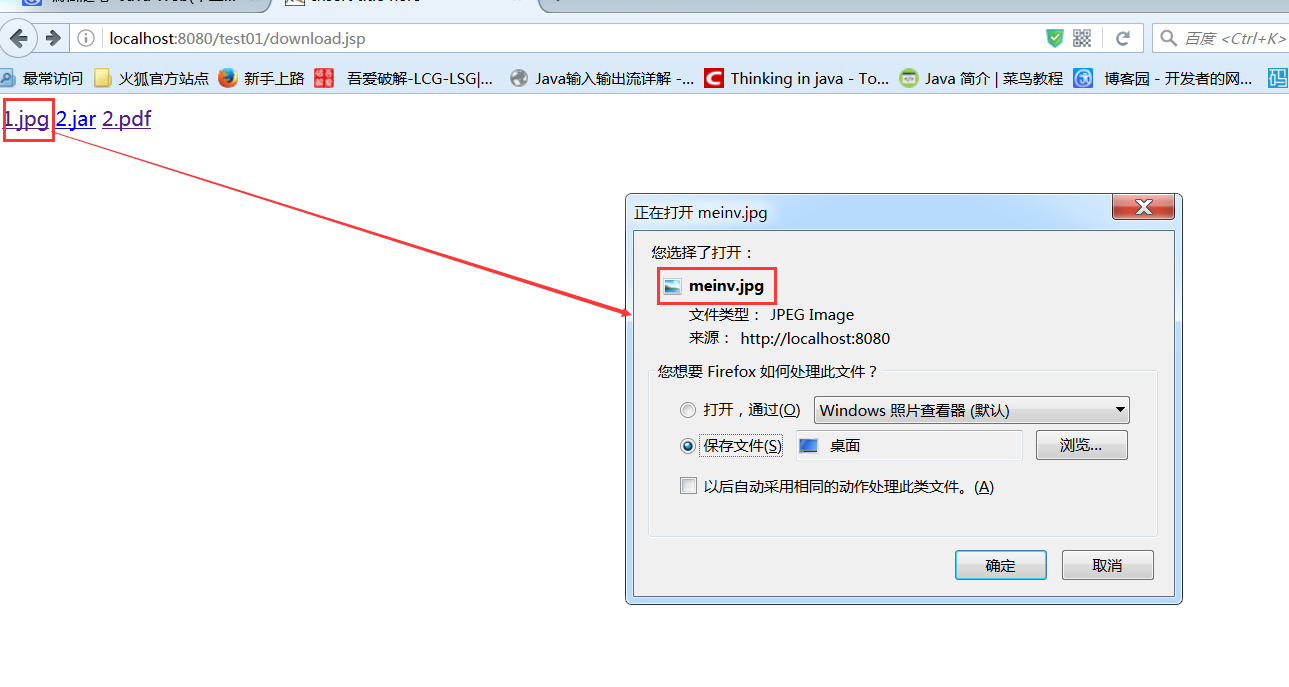
- 第一种,使用a标签,也就是使用超链接,如果浏览器能够解析,则直接显示出来,如果不能解析,则进行下载,这种方式不太好。

以firefox浏览器为例,第一个和第三个都能直接解析出来,而第二个则不能解析,显示的是下载页面: 
- 第二种:
1.设置响应头,让浏览器知道应该下载,而不是解析
response.setHeader("content-disposition", "attachment;filename=" +fileName);//设置content-disposition响应2. 获取输入流,指向需要下载的文件
InputStream is = this.getServletContext().getResourceAsStream("/download/1.jpg");3.获取输出流,将其文件传到浏览器端
ServletOutputStream out = response.getOutputStream();4.使用IOUtils.copy(is,out);直接将输入流和输出流传进去,就会帮我们把输出流读到的内容通过输出流输出到浏览器。内部实现原理应该就如下所示:
int b = -1; byte[] bf = new byte[1024]; while((b=is.read(bf)) != -1){ out.write(bf,0,b);}public void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { String fileName="龙队今天赢了吗.jpg"; //设置响应头,通知浏览器应进行下载,而不是解析 response.setHeader("content-disposition","attachement;fileName="+fileName); //读取资源,发送给浏览器 InputStreamis=this.getServletContext().getResourceAsStream("/download/1.jpg"); ServletOutputStream out =response.getOutputStream(); IOUtils.copy(is,out); }

注意:这里下载时写的下载文件名不包含中文,所以能够正常显示,如果写中文的话,则会乱码,甚至是中文都不会显示出来。有两种方式处理这个中文乱码问题
简单处理
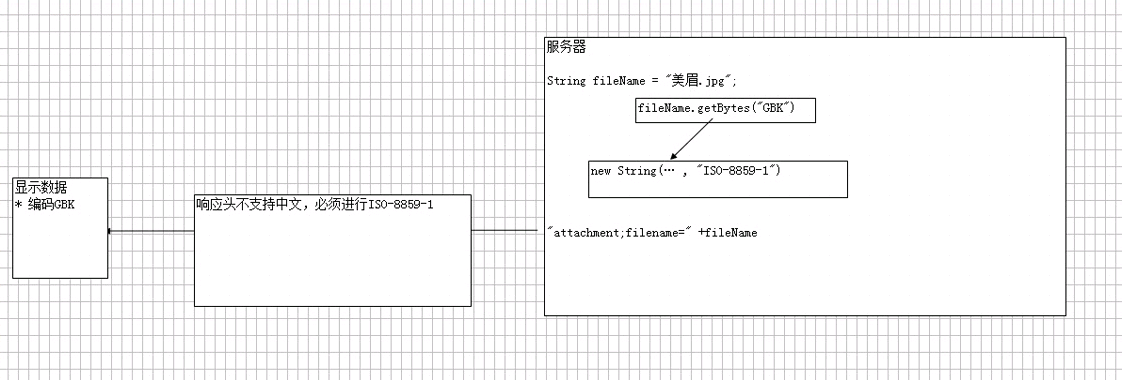
fileName = new String(fileName.getBytes("gbk"),"ISO8859-1");
fileName = new String(fileName.getBytes("utf-8"),"ISO8859-1");
fileName = new String(fileName.getBytes(),"ISO8859-1");
//这种跟第一种是一样的,默认使用的编码就是gbk。原理:上面代码意思是,先将fileName使用gbk或者utf-8进行编码,然后在使用ISO8859-1进行解码,此时的fileName是一个乱码文字。
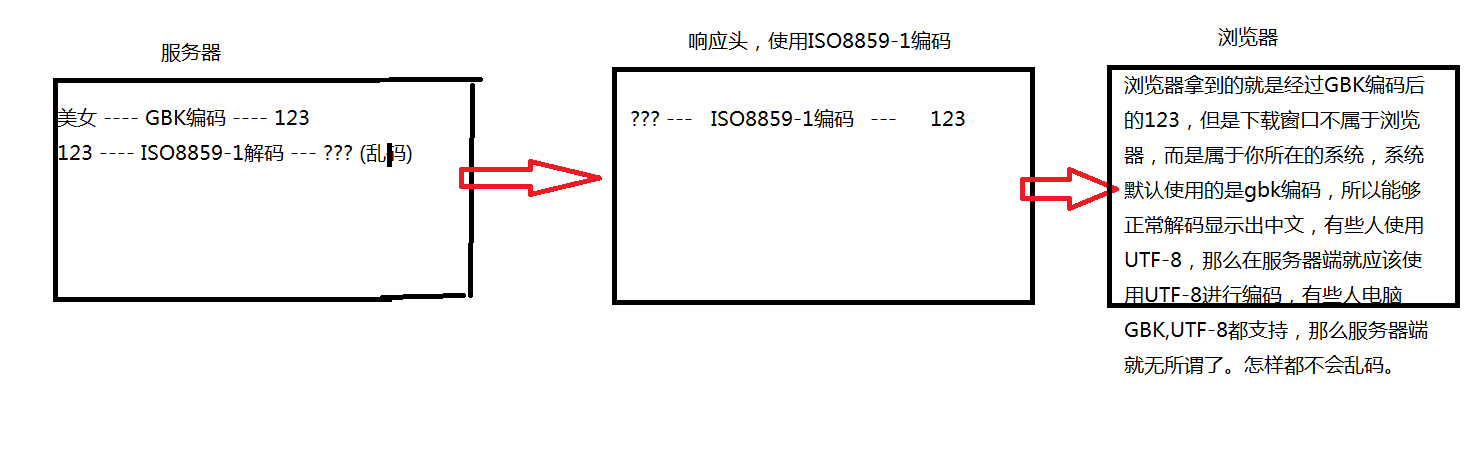
具体原理图可以看下面两张图,这张图解释了上面这段代码所做的事情,而整个编码过程,我来简单口述一下,在服务器端,写上面这段代码,“龙队今天会赢吗”是中文字,将其使用GBK码表进行编码后,就会获得一个计算机认识的符号,比如是123,然后我们在将这个计算机认识的符号,123使用ISO8859-1码表进行解码,变成我们所认识的汉字,但是因为编码和解码所用码表不一样,所以不能正常显示,也就是此时的fileName本身就是一个乱码的文字,然后在响应头中,因为是使用ISO8859-1的码表进行编码,所以fileName本身乱码的文字,就会变为机器认识的123,当到了浏览器端,因为123是由gbk进行编码的,所以如果使用gbk进行的解码的话,就会使其正确的显示,过程就是这样。
复杂处理
根据每个浏览器的不同,而进行不同的操作。根据浏览器不同进行设置。IE和谷歌 URL编码,火狐采用BASE64编码:
- IE和谷歌
IE 谷歌 采用 URL编码,就用URL对fileName进行编码即可。其内部跟我们上面讲解编码解码时的思路类似,可以将fileName输出看看是个什么结果,还是一个xxx.jpg,说明就是将fileName进行编码,解码的过程。
//判断是不是google或者IE浏览器
if(userAgent.contains("MSIE") || userAgent.contains("Chrome")){
fileName = URLEncoder.encode(fileName, "UTF-8");
}- 火狐 采用 Base64编码
if(userAgent.cotains("Firefox)){
BASE64ENcoder base64Encoder = new BASE64ENcoder();
String encStr = base64Encoder.encode(fileName.getBytes("UTF-8"));
//格式:=?字符集?编码方式?...?=
//*编码方式:B base64,Q q编码
fileName= "=?UTF-8?B?+encStr+"?=";
}这里会出现两个问题:
- BASE64Encoder这个类找不到包
方案1(推荐):只需要在project build path中先移除JRE System Library,再添加库JRE System Library,重新编译后就一切正常了。
即: 项目——属性——java bulid path——jre System Library——access rules——resolution选择accessible,下面填上** 点击确定。
方案2:Windows—— Preferences——Java —— Compiler—— Errors/Warnings——Deprecated and trstricted API
——Forbidden reference (access rules):——change to warning
- 格式问题,具体查看图中的注释,格式已经写出来了
总结:下载Easy啦,就是在编写下载文件名出现的中文乱码问题比较麻烦,其他的套路很容易:
- 设置响应头,让浏览器知道该文件是需要下载的;
- 就是找准要下载的文件的路径从而拿到输入流,在通过response拿到输出流;
- 通过OUtils.copy(is, out);就解决了,不用在乎其中内部的实现。
FileUpload的使用就到这里了,望诸^(* ̄(oo) ̄)^君笑纳