最近开始啃LSTM,发现BPTT这块还是不是很清晰,结合RNN,把这块整理整理
RNN
前馈神经网络(feedforward neural networks)如下图所示(这块内容可见我的博客神经网络BP算法):
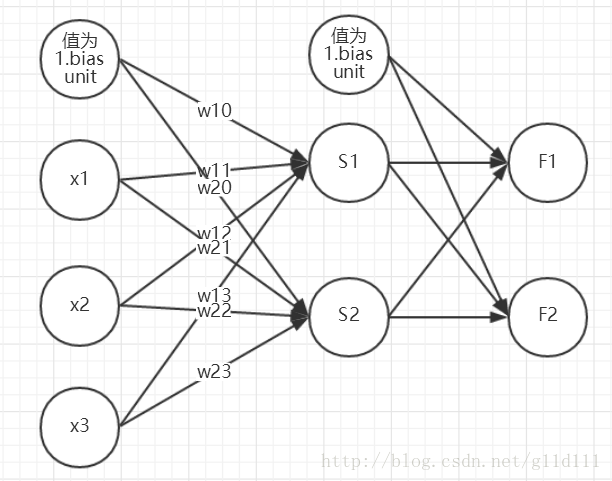
假设我们的训练集只有一个实例(
以中间层神经元
第1个神经元的净输入值
其中,
用上图的
净输入
好了,我们用抽象的形式进行表述(图摘自Jiaxun Cai’s Blog):

对每一层,因为考虑time step,所以都有:
其中图中的
前馈神经网络从输入节点接受信息,它只能对输入空间进行操作,对不同时序下的输入是没有“记忆”的。在前馈神经网络中,信息只能从输入层流向隐藏层,再流向输出层。这种网络无法解决带有时序性的问题,比如预测句子中的下一个单词,这种情况下,往往需要使用到前面已知的单词。假设要预测这样一句话:今天天气_。
由于受到前面的词语“天气”的影响,横线中填入“晴”的概率应该是挺大的,但是由于不考虑时序,即相当于每次输入的单词:“今天”“天气”都变换成输入向量,那我们无法有效的做出预测,因此,科学家们提出了RNN(Recurrent neural network)来解决在深度学习领域处理时序问题。
RNN与前馈神经网络最大的不同是,它维持有一个内部的空间,来维持/保存上下文的状态信息。

可以看到,RNN的隐藏层多了一条连向自己的边。因此,它的输入不仅包括输入层的数据,还包括了来自上一时刻的隐藏层的输出。
将其横向展开为:

传统的RNN
2015年发表在Nature杂志的Deep Learning中,将RNN定义为:RNNs, once unfolded in time, can be seen as very deep feedforward networks in which all the layers share the same weights.
即值得注意的是,在展开的RNN中,每一层隐藏层实际上是相同的(只是在不同时刻的副本),也就是说,它们最后得到的权值参数(不包括内部状态权值)——这个涉及到内部必须是一致的。在训练过程中,不同时刻的隐藏层的参数可能会不一致,最后可以将它们的平均数作为模型的参数。
RNN的BPTT算法导致的梯度消失与梯度爆炸
先看一下比较典型的BPTT一个展开的结构,如下图,这里只考虑了部分图,因为其他部分不是这里要讨论的内容。(思路基于论文Long Short-Term Memory)
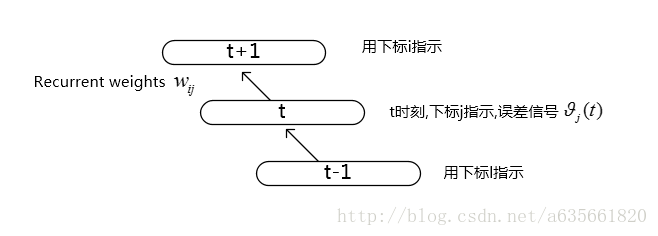
其中误差信号
即: 当前层单元
其中,
每一层的权值调整公式为:
对不同时刻

对RNN网络,在

对
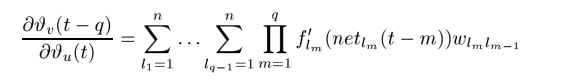
显然,这是连乘积的形式,当出现下图情形时:

梯度就会随着q的增大而呈指数增长,那么网络的参数更新会引起非常大的震荡。
如果出现:

梯度就会慢慢消失(趋近于0),导致学习无效。一般激活函数用simoid函数,它的导数最大值是0.25, 权值最大值要小于4才能保证不会小于1,所以一般的CNN/RNN中选用tanh比较多了。
为了避免梯度消失和梯度爆炸,一个简单(Naive)的做法是强制让流过每个神经元的误差都为1(也可以理解成:“误差信号不随时间步的变化而发生变化“)
思路是这样的:
① 假设每一个LSTM层只有一个单元
j ,那么误差信号的传递公式变为:
δj(t)=f′j(netj(t))wjjδj(t+1) ② 这里假设
f′j(netj(t))wjj=1.0 ,即δj(t)=δj(t+1)
并且,可以推出fj(netj(t)) 的形式为:
fj(netj(t))=netj(t)wjj
其中,
误差呈指数增长的现象比较少,误差消失在BPTT中很常见。在原论文中还有更详细的数学分析,但是了解到此个人觉的已经足够理解问题所在了。