ConcurrentHashMap的实现原理与使用
传统的HashMap不是线程安全的, 所以多线程进行put()和get()操作的时候可能会引发问题.
还有一个叫做HashTable的数据结构, 它使用的是synchronized来保证线程安全, 但是效率很低, 因为不能并发读.
ConcurrentHashMap采用的是锁分段技术, 将数据分成一段一段存储, 然后给每一段数据配一把锁,
当一个线程对某段数据进行写操作的时候, 其他段的数据也能被其他线程安全访问(读写).
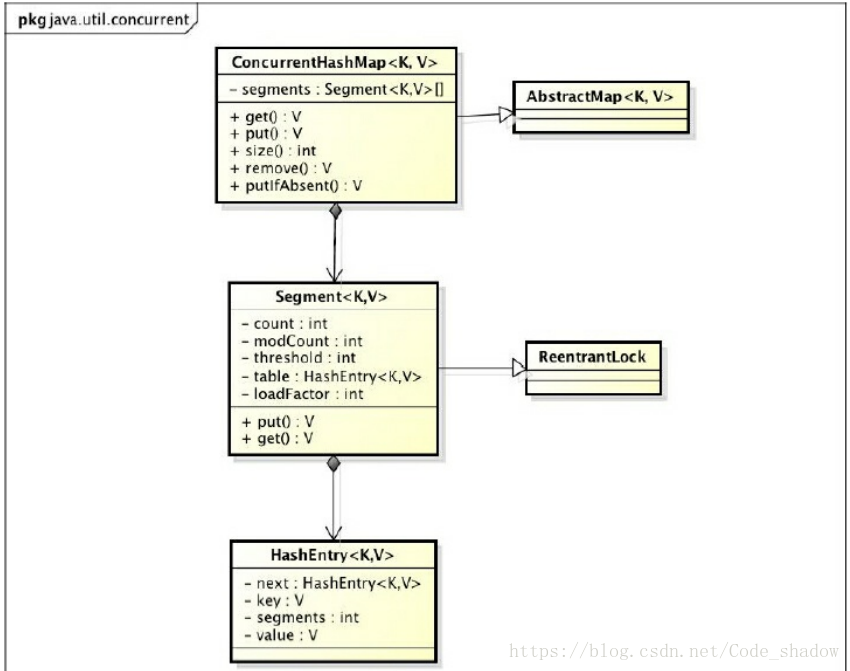
ConcurrentHashMap的结构
- 一个
ConcurrentHashMap包含一个Segment数组; - 一个
Segment里面包含一个HashEntry链表.
Segment是一种可重入锁, 在ConcurrentHashMap中扮演锁的角色.
HashEntry则是实际存储键值对数据的地方. 当对HashEntry的数据进行修改时, 必须首先获得与它对应的Segment锁.
ConcurrentHashMap的初始化
初始化segments数组
if (concurrencyLevel > MAX_SEGMENTS) { // 如果自定义的concurrencyLevel超过允许最大的并发数
concurrencyLevel = MAX_SEGMENTS; // 设定为允许的最大的并发数
}
int sshift = 0;
int ssize = 1;
while (ssize < concurrencyLevel) {
++sshift;
// 为了能够使用按位与的散列算法来定位segments数组的索引, 必须保证segments数组的长度是2的N次方
// 例如concurrencyLevel是14, 15或者16, 那么锁的个数也总是16
ssize <<= 1;
}
segmentShift = 32 -sshift; // 用于定位参与散列运算的位数长度
segmentMask = ssize - 1; // 散列运算的掩码, 各个二进制位都是1
this.segments = Segment.newArray(ssize); // 创建Segment数组初始化单个segment
if (initialCapacity > MAXIMUM_CAPACITY) { // 如果自定义的Capacity超过了单个segment允许的最大的Capacity
initialCapacity = MAXIMUM_CAPACITY; // 设定为单个segment允许的最大的Capacity
}
int c = initialCapacity / ssize; // 计算单个segment下的HashEntry数组的长度基值
if (c * ssize < initialCapacity) { // 确保数组能够容纳所有键值对
++c;
}
int cap = 1;
while (cap < c) {
cap <<= 1; // 将HashEntry的长度向2的N次方对齐
}
for (int i = 0; i < this.segments.length; ++i) {
// 初始化各个segment元素, 实际上是创建cap长度的HashEntry数组, loadFactor指定了HashEntry数组总体上允许的最大负载百分比
this.segments[i] = new Segment<K, V>(cap, loadFactor)
}定位Segment
在插入和获取元素的时候, 必须先通过散列算法定位到Segment,
ConcurrentHashMap首先使用Wang/Jenkins hash的变种算法对元素的hashCode进行一次再散列.
变种算法的代码如下:
// 本段代码无需理解, 只需要知道是一个对要插入ConcurrentHashMap元素的原始hash值的再散列(hash)的过程即可
private static int hash(int h) {
h += (h << 15) ^ 0xffffcd7d;
h ^= (h >>> 10);
h += (h << 3);
h ^= (h >>> 6);
h += (h << 2) + (h << 14);
return h ^ (h >>> 16);
}// 用再散列后的元素的hash值来定位segment数组索引
final Segment<K, V> segmentFor(int hash) { // hash 是再散列后的元素的hash值
// 使用hash值的高四位进行Segment数组索引的计算
// 这里假设segmentMask为1111, segmentShift为28, 也就是Segment数组的长度为16
return segments[(hash >>> segmetnShift) & segmentMask];
}之所以进行再散列, 目的是减少散列冲突, 使元素能够均匀分布在不同的Segment上. 如若负载不均, 那么分段锁就会失去意义.
ConcurrentHashMap的操作
主要介绍三种操作: get, put和size操作
get操作
步骤如下:
- 对元素的原始hash值先进行再散列;
- 通过这个散列值定位到
segment数组索引; - 通过散列算法定位到具体的
HashEntry数组中的元素;
public V get(Object key) {
int hash = hash(key.hashCode()); // 再散列
return segmentFor(hash).get(key, hash); // 点调用segmentFor返回具体的segment, 然后通过hash值获取元素
}需要注意的是, 定位Segment参与计算是再散列后的hash值的高位, 而定位HashEntry参与计算的是再散列后的hash值的低位, 这是为了避免两次计算使用的hash值相同, 导致元素在Segment中散开了, 但是没有在HashEntry中散开.
(hash >>> segmentShift) & segmentMask; // 定位Segment数组索引使用高位
hash & (tab.length - 1); 定位HashEntry使用低位get的高效之处在于整个get过程不需要加锁, 因为value和count都是volatile类型的值. 所以可以多线程并发读, 但是写入仍然是独占的(对每个数据段独占).
put操作
put操作是需要加锁的. 需要完成以下操作:
- 通过再散列的hash值定位到需要插入的Segment;
- 判断是否需要对
Segment的HashEntry数组进行扩容(通过判断是否超过负载因子*总容量来判断); - 定位添加元素的位置;
在扩容的时候, 首先会在当前需要扩容的Segment中创建一个容量是之前两倍的数组, 然后将原数组里的元素进行再散列后插入到新的数组里.
为了高效, ConcurrentHashMap不会对整个容器进行扩容, 仅会对某个segment进行扩容.
size操作
size操作获取count的累加值的具体步骤是:
- 先通过两次不锁住segment数组的方式来累加count;
- 如果统计的过程中, 容器的count出现了变化, 则再采用加锁的方式统计Segment数组中所有元素的个数.
上述的判断容器的count是否发生变化是通过一个modCount变量来统计的, 任何会造成count变化的操作, 比如put, remove, clean方法操作元素都会将modCount加1, 所以在进行size操作前后比较modCount元素是否发生变化, 就可以得知容器的大小是否发生变化.
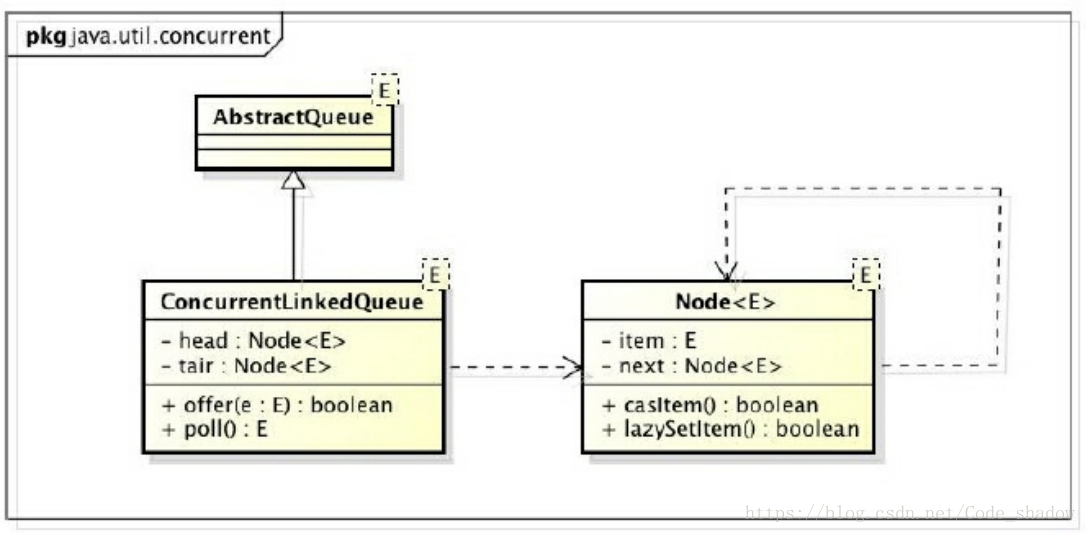
ConcurrentLinkedQueue
是一个线程安全的基于链接节点的非阻塞FIFO无界队列.
对于阻塞算法, 有两种实现思路:
- 使用一个锁, 也就是入队出队用同一个锁
- 使用两个锁, 入队出队用两个锁;
对于非阻塞算法, 可以借助循环CAS的方式来实现(注: 实际上是通过加轻量级锁的方式, 循环CAS会消耗较多的时间片, 只有确认同步块运行速度较快的情况才能使用轻量级锁).
以下是ConcurrentLinkedQueue的结构
阻塞队列
阻塞队列是支持阻塞的插入和阻塞的移除的队列.
阻塞的插入 意思是当队列满时, 队列会阻塞插入元素的线程, 直到队列不满;
阻塞的移除 意思是在队列为空时, 获取元素的线程会等待队列变为非空;
常见的应用场景是生产者和消费者的场景, 作为二者获取元素的容器.
Java中的阻塞队列
ArrayBlockingQueue一个由数组结构组成的有界阻塞队列LinkedBlockingQueue一个由链表结构组成的有界(初始化和最大值均为Integer.MAX_VALUE大小, 可以看做无界队列)阻塞队列PriorityBlockingQueue一个支持优先级排序的无界阻塞队列DelayQueue一个使用优先级队列实现的无界阻塞队列, 在创建元素的时候可以指定多久才能从队列中获取当前元素,
只有在延迟期满才能从队列中提取元素.SynchronousQueue一个不存储元素的阻塞队列, 也就是容量是0, 直接将生产者线程的数据传递给消费者.
每一个put操作必须等待一个take操作, 否则会被阻塞LinkedTransferQueue一个由链表结构组成的无界阻塞队列, 如果有消费者在等待数据, 就直接将生产者的数据传递给消费者,
如果没有消费者在等待获取数据, 就将数据放置在队列尾部.LinkedBlockingDeque一个由链表结构组成的双向阻塞队列. 由于两端都可以入队和出队, 比前述队列减少了一半的数据竞争,
可以用在”工作窃取”模式中
未完待续