前言
随着自然语言处理(NLP)的关注度越来越高,很多人都想向这个领域小小的探索一番,巧了,小编就是这其中之一。在看文章的你,也许是小编的前辈,在这里先行鞠躬致意,如有不妥望指正;也许正如一个月前的小编,是一个什么都不懂的小白。
此前,小编稍微了解过一点NLP,其实,其实也就会用jieba分一下词。-_-
而接下来介绍的,就是功能强大的百度NLP了,实话说,百度公司在NLP领域是一个不折不扣的佼佼者,不论从结果还是从效率上,百度NLP都是一个很棒的存在。关键是,它居然开放了。开!放!了!对于在这个领域探索的人来说,不管是对新入门者还是对从事研究者,无疑都是一个天大的好消息。
闲言少叙,咱们进入正题。
初识百度NLP
打开百度,搜索“百度NLP”,不出意外的话,排名第一位的便是带有官网标识的结果了。点进去跳转到一个新的界面,右上方看到“控制台”三个字,点进去,此时会到一个登录界面,登录一下就ok了,没有百度账号的小朋友是时候注册一个了。登录进去以后,可以看到左侧有个产品服务,然后:【产品服务】-【人工智能】-【自然语言处理】,好了,终于来到了我们梦寐以求的界面。
这里面是没有应用的,这时我们需要创建一下应用,点击创建应用,然后起个名字、选个类型、选择接口(自然语言处理是默认选中的)、写一下描述,ok!这个时候你会发现,自己多了一个应用,没错,就是我们自己刚刚创建的。应用列表中有名称、ID、API Key、Secret Key,咳咳,这两个key可是大有用处啊。可以说,我们费了这么半天功夫,就为了拿到这两个key,有了这个,我们就可以调用接口了。
接口在哪?不急,你再点一下自己创建的应用试试,API列表是不是尽显眼前?对,这便是传说中的接口了。如下图。

使用百度NLP
调用接口?怎么调用?小编这里给大家介绍两种方法。
- 第一种,话不多说直接贴出网址:【https://ai.baidu.com/sdk#nlp】,里面有说明文档,相当详细,而且涵盖java、php、python等多种语言,非常nice。(一般情况下我们选择的SDK资源类型为“语言处理基础技术”)
- 第二种,代码直接实现,小编这里用的是python,所以就直接贴出代码了。(代码中的API Key和Secret Key要用自己的替换掉才可以正确运行)
# -*- coding: utf-8 -*-
### 基于python3
### 思路很清晰:获得access token -> 接入接口 -> 送入数据调用接口 -> 返回数据
import urllib
import requests
import json
import time
import os
## 获得access token
## 注意:需要API Key和Secret Key
def get_access_token():
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=【API Key】&client_secret=【Secret Key】'
request = urllib.request.Request(host)
request.add_header('Content-Type', 'application/json; charset=UTF-8')
response = urllib.request.urlopen(request)
content = response.read()
content=json.loads(content)
if content:
return content["access_token"]
## 接口接入
## 注意:返回的是json格式数据
def get_content(text):
access_token = get_access_token().strip()
url = "https://aip.baidubce.com/rpc/2.0/nlp/v1/lexer?access_token="+access_token #API
headers = {"Content-Type": "application/json"}
data={"text":text}
try:
data=json.dumps(data, ensure_ascii=False).encode('gbk')
r = requests.post(url, data=data, headers=headers)
return r.text
except Exception as e:
print ('a', str(e))
return 0
## 主函数调用接口
if __name__ == '__main__':
text = '今天是非常开心的一天,明天也要开心。' #送入的数据
contents = get_content(text) #接收返回的结果
#创建一个json文件,将结果放进文件
f = open('test.json','w')
f.write(contents)这个时候我们打开“test.json”看一下结果,我们发现,只有一行,结果不是很好看。如下图。

怎么办呢?很简单,去百度搜一下“json在线格式化”,把我们的结果复制到这里格式化一下就可以了。如下图。
>>> 如果数据量比较大的话,这样的办法就有点不太合适了。
>>> 小编建议读者自己写个python格式化一下,代码很简单,还可以练练手,小编就是这么干的。
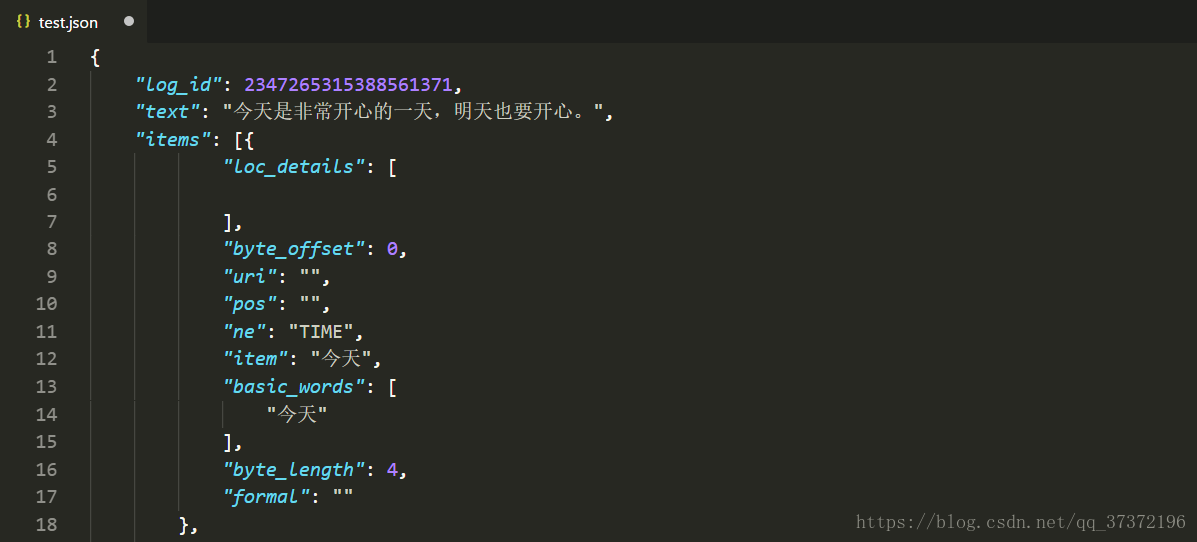
上述返回的参数都是什么意思呢?
话不多说,网址奉上,里面详细的很:【http://ai.baidu.com/docs#/NLP-Python-SDK/top】
上面的介绍只是小编用百度NLP下的词法分析接口做的一个介绍,如果读者想要使用句法分析、情感分析等接口,只需将下方图片方框中的网址(即接口)替换一下即可。
>>> 后面那个问号不要删,除了这个网址其他的都不要动。

上述例子用的只是一句话,如果你有大量的数据,而且存储在文本文件中,该怎么办呢?小编相信以你的聪明才智完全可以很棒的解决这个问题。
小编能想到的就是按自然段送入、按句子送入、按行送入,至于怎么实现,那要看你的文本长什么样子了。
有python,无难事,无非就是写个代码处理一下数据呗。
后话
上面呢,小编算是带大家入了一下门,并没有深入去讲。
其实,自然语言处理中又何止词法分析这一个,语法分析、情感倾向分析、中文词向量表示等比比皆是;百度NLP功能里又何止自然语言处理这一种,语音识别、人脸识别、人体分析等应有尽有。
不过,会用了其中一种,其它的举一反三,融会贯通,自然是不难。无非就是接口换一下、送进去的数据变一下,仅此而已。
相信你是一个懂得思考的读者,这些对你来说只是一些小操作而已。
哦,对了,调用这个接口是不限速的,也就是说,完全不用担心调用频率太高而被封掉,完全可以不需要sleep函数。只是,在数据量庞大的时候,如果网速不是很稳定,一个卡壳就很有可能导致前功尽弃。
小编就在这上面吃了不少的苦头,几经周折之后终于忍受不了了,于是修改了一下代码,使得在爆出error以后电脑会放出一段优美的音乐来提示小编,听到音乐以后小编就知道网络出现了问题,待修复网络问题在执行处敲回车,代码就仍然可以继续正确的运行了。从此以后,妈妈再也不用担心断网问题导致的error了。
最后,如果你对以上文章有什么疑问,欢迎在下方留言,或者直接QQ走一波:1329924827(邮箱同步)
博客新人,期待您的关注:【https://blog.csdn.net/qq_37372196】