1.前言
我觉得JAVA集合框架里边,比较难以理解的就属HashMap了,这篇博文一次应该是写不完的,希望日后慢慢完善。下面主要从存储结构,扩容机制,内部方法,线程安全,JDK1.8的优化等方面来记录下我对HashMap的理解
3.HashMap的存储结构
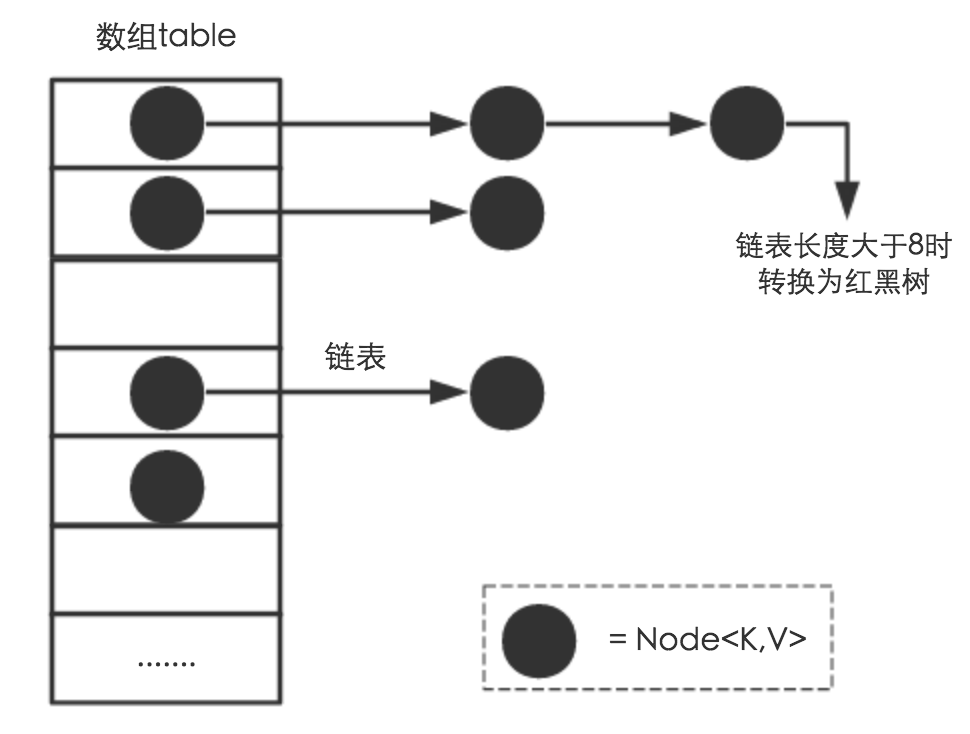
如上图所示,主要分为以下几个部分:
“骨干”:哈希桶数组,Node<K,V>节点key值经过hash后会映射到哈希桶数组中。key值经过hash后,hash值可能相同,也就是会产生hash冲突。解决hash冲突有两种方式,
一种是开放式hash,另一种是封闭式hash。HashMap中采用的是开放式hash,所以就引出了另一个组成部分---链表
(开放式hash
:每个Node节点后挂接一个链表(或其他可替代的数据结构)来存放hash一样的键值对
封闭式hash:Node节点数组作为主体,如果产生冲突,则以某个增量(一般为1)线性向后移动,然后插入)
链表:挂接在Node<K,V>,如果产生hash冲突,则键值对将被加入到挂接的链表中
红黑树:我们知道,链表的查询速度是O(n),所以在Java8中对这一问题进行了优化,默认链表元素size超过8时,将重构为一个红黑树,此时时间复杂度是O(lgn)
4.扩容机制
我们先来看看HashMap的几个字段:
intthreshold; // 最多能够容纳的键值对数目
finalfloatloadFactor; // 负载因子
intmodCount;intsize;//表示当前HashMap中与多少个元素
threshold表示HashMap中能够容纳键值对的最大数目,默认大小为16,loadFactor表示负载因子,loadFactor*threshold就会得到HashMap的阈值,一旦超过这个阈值,就会
触发扩容机制。modCount表示用来记录内部结构发生变化的次数,用于快速失败;size表示HashMap中当前元素个数。
当我们向HashMap中插入元素的时候,如果达到阈值,就会触发扩容机制,我们现在来看看扩容机制,先看看JDK1.7的扩容机制:
void resize(int newCapacity) { //传入新的容量
Entry[] oldTable = table; //引用扩容前的Entry数组
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) { //扩容前的数组大小如果已经达到最大(2^30)了
threshold = Integer.MAX_VALUE; //修改阈值为int的最大值(2^31-1),这样以后就不会扩容了
return;
}
Entry[] newTable = new Entry[newCapacity]; //初始化一个新的Entry数组
transfer(newTable); //!!将数据转移到新的Entry数组里
table = newTable; //HashMap的table属性引用新的Entry数组
threshold = (int)(newCapacity * loadFactor); //修改阈值
}
扩容机制就是用更大的数组来替换更小的数组,那么就需要将旧数组中的元素复制到新数组中,我们来看看这个transfer():
void transfer(Entry[] newTable) {
Entry[] src = table; //src引用了旧的Entry数组
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) { //遍历旧的Entry数组
Entry<K,V> e = src[j]; //取得旧Entry数组的每个元素
if (e != null) {
src[j] = null;//释放旧Entry数组的对象引用(for循环后,旧的Entry数组不再引用任何对象)
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity); //!!重新计算每个元素在数组中的位置
e.next = newTable[i]; //标记[1]
newTable[i] = e; //将元素放在数组上
e = next; //访问下一个Entry链上的元素
} while (e != null);
}
}
}5.内部方法-put

①.判断键值对数组table[i]是否为空或为null,否则执行resize()进行扩容;
②.根据键值key计算hash值得到插入的数组索引i,如果table[i]==null,直接新建节点添加,转向⑥,如果table[i]不为空,转向③;
③.判断table[i]的首个元素是否和key一样,如果相同直接覆盖value,否则转向④,这里的相同指的是hashCode以及equals;
④.判断table[i] 是否为treeNode,即table[i] 是否是红黑树,如果是红黑树,则直接在树中插入键值对,否则转向⑤;
⑤.遍历table[i],判断链表长度是否大于8,大于8的话把链表转换为红黑树,在红黑树中执行插入操作,否则进行链表的插入操作;遍历过程中若发现key已经存在直接覆盖value即可;
⑥.插入成功后,判断实际存在的键值对数量size是否超多了最大容量threshold,如果超过,进行扩容。
②.根据键值key计算hash值得到插入的数组索引i,如果table[i]==null,直接新建节点添加,转向⑥,如果table[i]不为空,转向③;
③.判断table[i]的首个元素是否和key一样,如果相同直接覆盖value,否则转向④,这里的相同指的是hashCode以及equals;
④.判断table[i] 是否为treeNode,即table[i] 是否是红黑树,如果是红黑树,则直接在树中插入键值对,否则转向⑤;
⑤.遍历table[i],判断链表长度是否大于8,大于8的话把链表转换为红黑树,在红黑树中执行插入操作,否则进行链表的插入操作;遍历过程中若发现key已经存在直接覆盖value即可;
⑥.插入成功后,判断实际存在的键值对数量size是否超多了最大容量threshold,如果超过,进行扩容。