主要内容
- 进入今日头条https://www.toutiao.com/
- 按F12进行数据分析,找到要爬取的内容
- 根据获取的网页信息,编写代码
- 一些模块的使用方法
- 源代码展示
- 打包成可执行程序exe
1.进入今日头条,按F12找到开发者工具,选择Network(网络),本文使用谷歌浏览器为例。
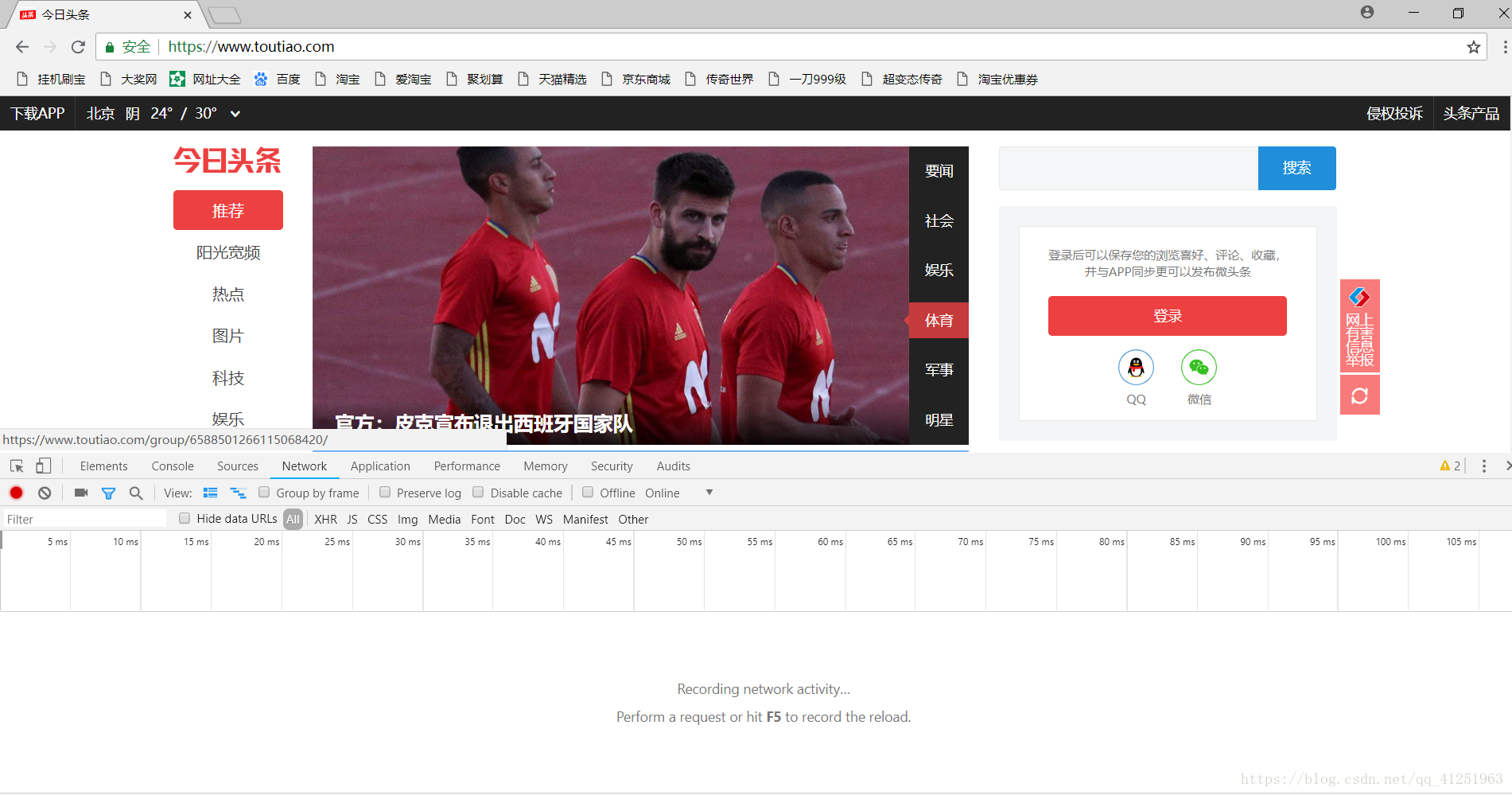
2.在搜索栏里输入搜索内容(也是我们后续要爬取的图片内容),点击搜索,观察开发者工具中Network的变化,找出有用的数据。
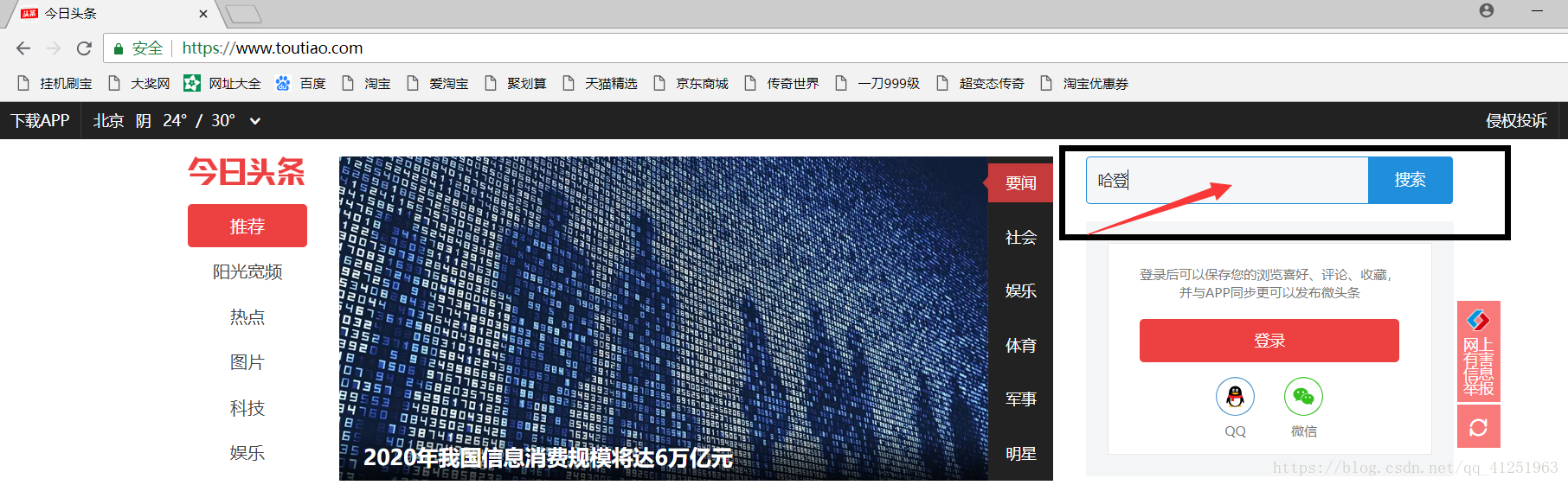
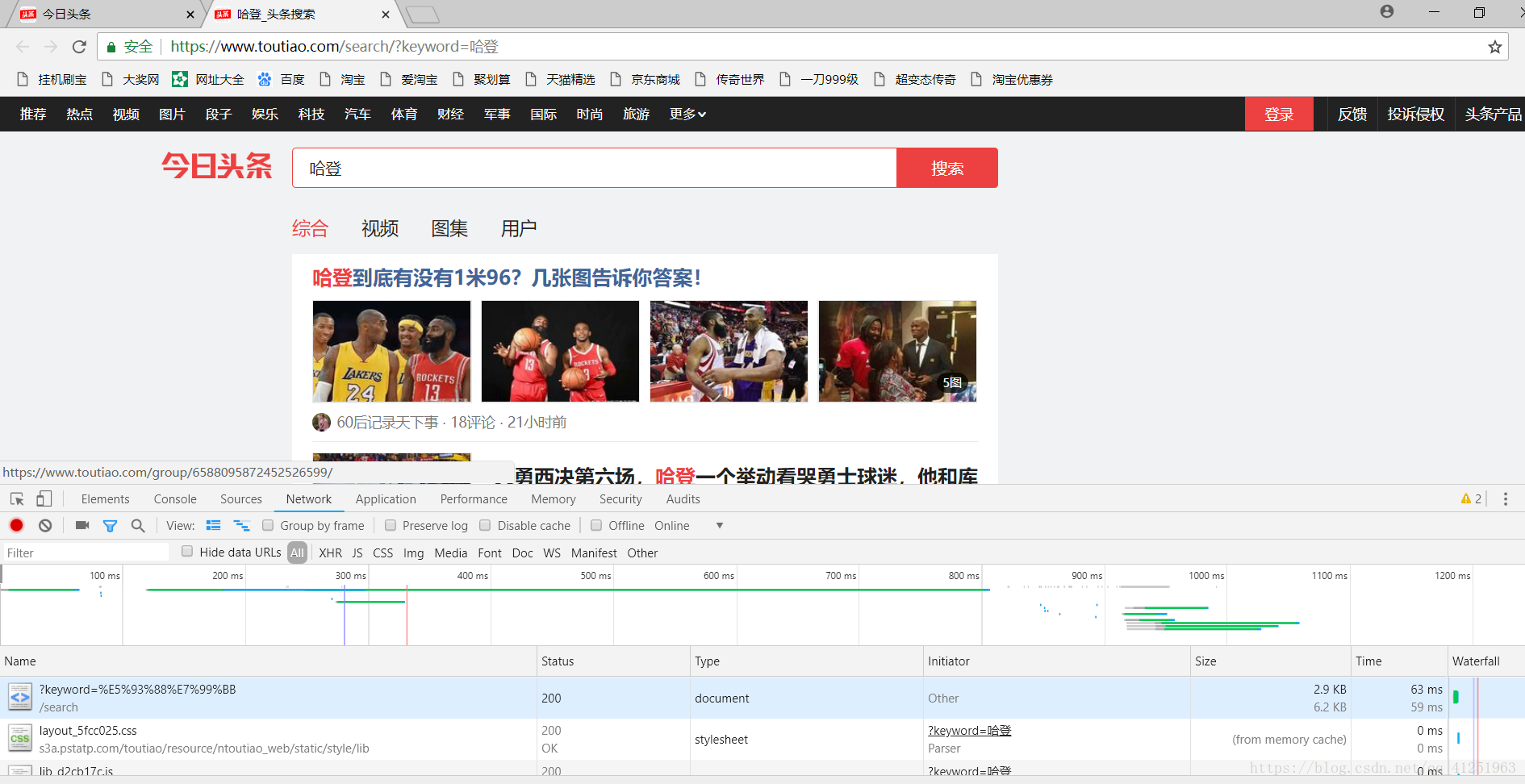
3.找到这条数据,可以看到请求头的一些信息,注意Query String Parameters的内容,与我们请求的网址(Request URL:)有关。
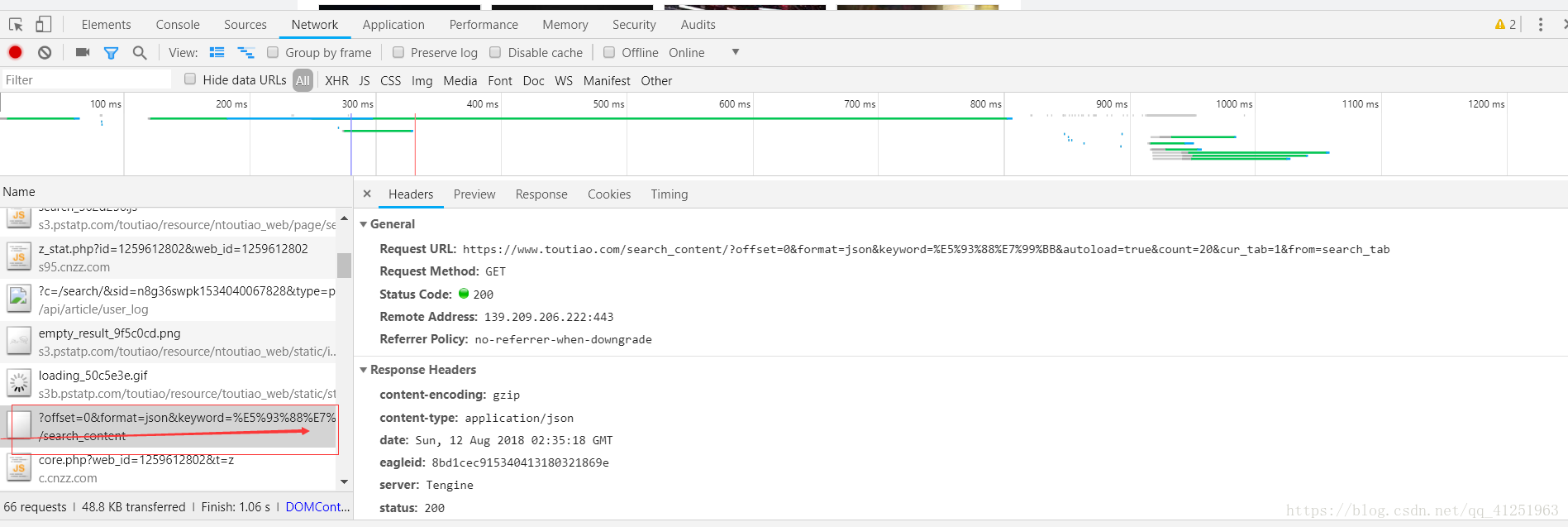
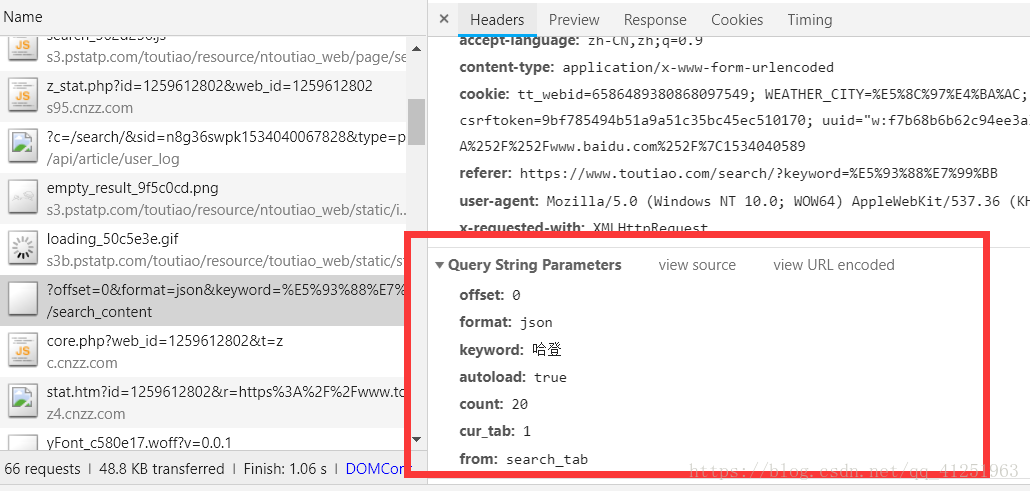
4.找到Preview,我们要找的数据都在这里!!!
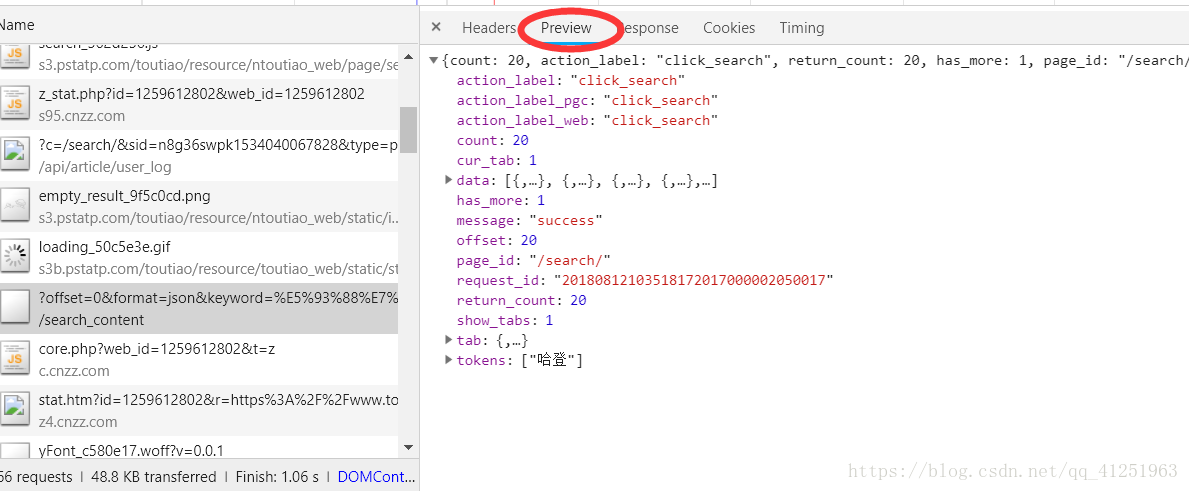
5.找到data下的数据,随意打开一个,我们将看到这些信息,包括标题,文章链接,关键字,评论数量等很多信息。我们主要目的是爬取图片,因此image_list里面的数据才是我们最关心的。
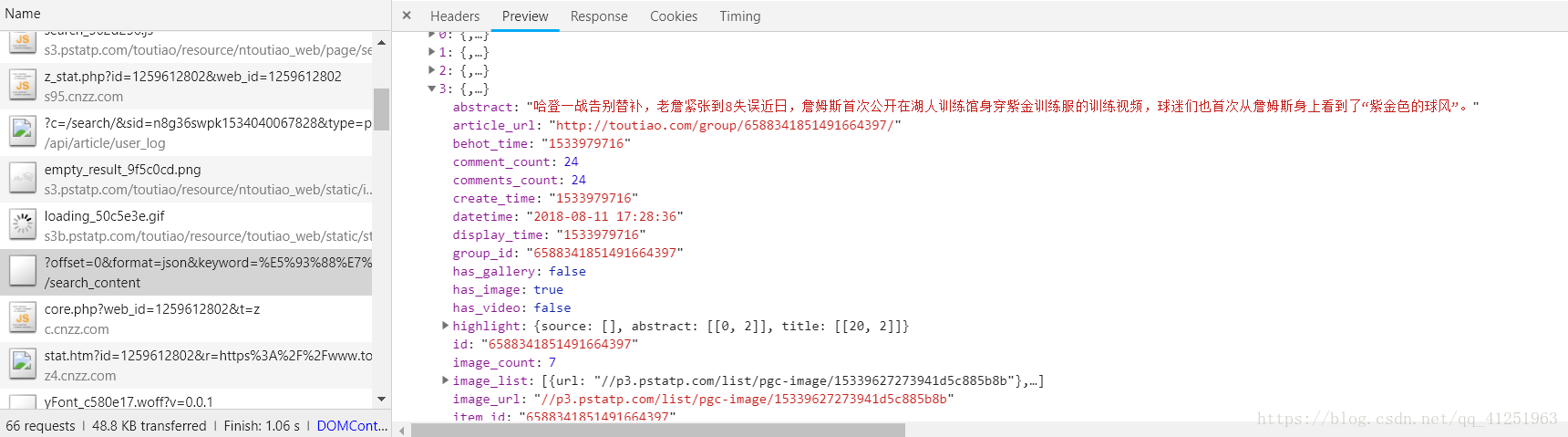
我们要爬取图片的链接都在这里。
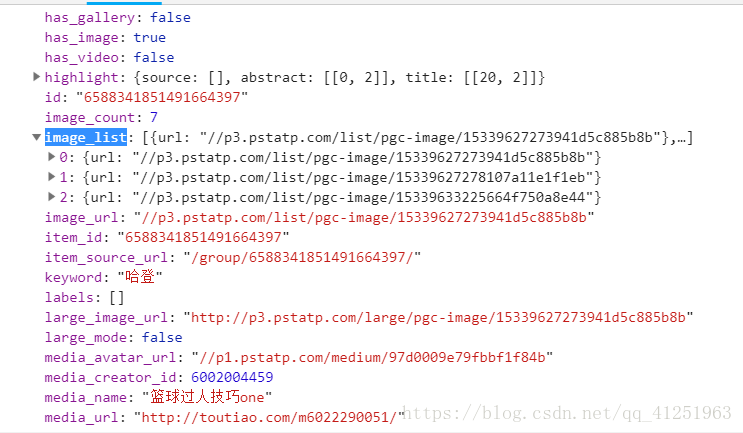
6.分析到这里,我们就可以写代码了。首先到入一些必要的模块。
import requests
from urllib.parse import urlencode
import os
from hashlib import md5requests模块用于请网页信息,获取网页;os模块主要用于文件创建,存取爬到的内容;hashlib模块用md5生成图片名;urlencode将字典形式的数据转化成查询字符串;
定义一个函数,用来获取一个页面的内容,传入两个参数,(offset,keyword),如果我们继续翻看网页,会发现有很多这样的数据。
def get_page(offset,keyword):
params={
'offset':offset,
'format':'json',
'keyword':keyword,
'autoload':'true',
'count':'20',
'cur_tab':'1',
'from':'search_tab'
}
#https://www.toutiao.com/search_content/?offset=60&format=json&keyword=%E8%BD%A6%E6%A8%A1&autoload=true&count=20&cur_tab=1&from=search_tab
url='https://www.toutiao.com/search_content/?'+urlencode(params)
response=requests.get(url)
#500服务器内部错误,400错误请求(服务器找不到请求的语法) 404未找到
if response.status_code==200:
return response.json()获取json数据,判断image_list是否存在,如果存在,遍历图片的链接,构造一个生成器。
def get_images(json):
data=json.get('data')
if data:
for item in data:
image_list=item.get('image_list')
title=item.get('title')
if image_list:
for image in image_list:
#构造一个生成器,将图片和标题一起返回
yield {
'image':image.get('url'),
'title':title
}图片的存取:用title作为要存取图片的文件夹,创建文件夹,并用二进制文件写入图片。
def save_image(item):
if not os.path.exists(item.get('title')):
os.mkdir(item.get('title'))
local_image_url=item.get('image')
response=requests.get("http:"+local_image_url)
if response.status_code==200:
file_path='{0}/{1}.{2}'.format(item.get('title'),md5(response.content).hexdigest(),'jpg')
#判断路径是否存在,如果不存在,写入
if not os.path.exists(file_path):
with open(file_path,'wb')as f:
f.write(response.content)
定义一个offset数组,遍历,提取图片,下载
def main(offset,keyword):
json=get_page(offset,keyword)
for item in get_images(json):
print(item)
save_image(item)完整代码
#coding=utf-8
import requests
from urllib.parse import urlencode
import os
from hashlib import md5
def get_page(offset,keyword):
params={
'offset':offset,
'format':'json',
'keyword':keyword,
'autoload':'true',
'count':'20',
'cur_tab':'1',
'from':'search_tab'
}
#https://www.toutiao.com/search_content/?offset=60&format=json&keyword=%E8%BD%A6%E6%A8%A1&autoload=true&count=20&cur_tab=1&from=search_tab
url='https://www.toutiao.com/search_content/?'+urlencode(params)
response=requests.get(url)
#500服务器内部错误,400错误请求(服务器找不到请求的语法) 404未找到
if response.status_code==200:
return response.json()
def get_images(json):
data=json.get('data')
if data:
for item in data:
image_list=item.get('image_list')
title=item.get('title')
if image_list:
for image in image_list:
#构造一个生成器,将图片和标题一起返回
yield {
'image':image.get('url'),
'title':title
}
#item就是get_image()返回的一个字典
#item里面的title创建一个文件夹
def save_image(item):
if not os.path.exists(item.get('title')):
os.mkdir(item.get('title'))
local_image_url=item.get('image')
response=requests.get("http:"+local_image_url)
if response.status_code==200:
file_path='{0}/{1}.{2}'.format(item.get('title'),md5(response.content).hexdigest(),'jpg')
#判断路径是否存在,如果不存在,写入
if not os.path.exists(file_path):
with open(file_path,'wb')as f:
f.write(response.content)
#定义一个offset数组,遍历,提取图片,下载
def main(offset,keyword):
json=get_page(offset,keyword)
for item in get_images(json):
print(item)
save_image(item)
if __name__ == '__main__':
keyword=input("请输入要爬取图片的关键词:")
offset=input("请输入要爬取的数量:")
main(offset,keyword)
为了使用方便,我们可以将我们的程序打包成可执行文件。这里我们使用pyinstaller这个模块。如果没有这个模块,可以使用pip install pyinstaller 安装。
安装方法
1.用cmd进入你要打包的python目录
2.输入pyinstaller 文件名.py回车即可
3.可执行文件在dist文件夹下
pyinstaller用法扩展:
-F 表示生成单个可执行文件
-w 表示去掉控制台窗口,这在GUI界面时非常有用。不过如果是命令行程序的话那就把这个选项删除吧!
-p 表示你自己自定义需要加载的类路径,一般情况下用不到
-i 表示可执行文件的图标
–version-file file_version_info.txt :表示将标准版本信息文件的内容赋给exe文件的属性