图 相关问题和算法
其他
2018-08-13 22:58:31
阅读次数: 0
一. 一些定义和术语
- 顶点(vertex):图中的数据元素。
- 弧(arc):<v,w>表示从顶点v到顶点w的一条弧,v为弧尾(tail)或初始点,w为弧头(head)或终端结点。此时图为有向图。
- 边(edge):(v,w)表示顶点v和w之间的一条边,边是没有方向的。此时的图为无向图。
- 无向图e的取值范围是:0到 1/2*n(n-1);有向图是:0到n(n-1)。(其中e是边或弧的数目,n是顶点数,下同)
- 完全图:无向图中,有1/2*n(n-1)条边的图;有向图中,有n(n-1)条边的图。
- 稀疏图(sparse graph):有很少条边或弧的图(e<nlogn)。
- 稠密图(dense graph):反之就是稠密图。
- 权(weight):边或弧具有与它相关的数,这个数叫做权。
- 网(network):带权的图通常叫做网。
- 邻接点:对于无向图,两个点之间存在一条边。这条边称依附于该点,或者说两个顶点相关联。
- 度(degree):对于无向图,和v相关联的顶点数。
- 出度(OutDegree) 和 入度(InDegree):对于有向图而言,因为有进入顶点或离开顶点的弧,所以度分为出度和入度。
- 路径:从一个顶点到另外一个顶点的序列(中间可以有很多顶点)。如果图是有向的,那么路径也是有向的。
- 回路(cycle):或称环。即第一个顶点和最后一个顶点相同的路径。
- 简单路径:序列中顶点不重复出现的路径。
- 连通:一个顶点到另外一个顶点有路径,那么称这两个顶点连通。
- 连通图:对于无向图,如果任意两个顶点都是连通的,那么就是连通图。
- 连通分量:无向图、非连通图中的极大连通子图。
- 强连通图:在有向图中,对于任意两个顶点,可以互相来回的图。
- 强连通分量:有向图中,极大强连通子图。
二. 图的存储
1. 邻接矩阵
- 图的邻接矩阵(Adjacency Matrix)存储方式是用两个数组来表示图。一个一维数组存储图中顶点信息,一个二维数组(称为邻接矩阵)存储图中的边或弧的信息。
- 假设图G有n个顶点,则邻接矩阵式一个 n∗n 方阵,定义为:arc[i][j]=1,若(vi,vj)∈E 或 <vi,vj>∈E;反之arc[i][j]=0 。因此无向图的边数组是一个对称矩阵。
- 如果是一个网,有权值。可以直接把1和0变成权值,然后定义一个无穷大值,如果没有边或弧则为无穷大。
- 因为无向图的邻接矩阵是对称的,因此可以压缩掉一半,用一个一维数组来存储。
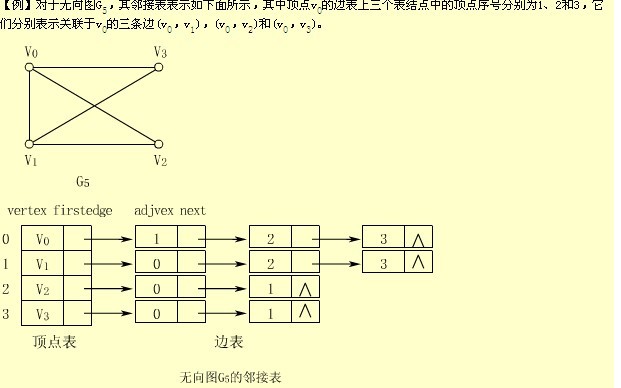
2. 邻接表
- 对于边数相对顶点较少的图,邻接矩阵这种结构存在对存储空间的极大浪费。考虑另一种存储结构,可考虑对边或弧使用链式存储的方式来避免空间浪费问题。
- 基本思想:对图的每个顶点建立一个单链表,存储该顶点所有邻接顶点及其相关信息。每一个单链表设一个表头结点。第i个单链表表示依附于顶点Vi的边(对有向图是以顶点Vi为头或尾的弧)。
- 由邻接表获得一些信息:
①某顶点的度为该顶点边表中结点的个数
②判断两顶点是否有边,只需测试顶点的边表中是否有该顶点的下标即可
③求顶点的邻接点,只需对该顶点的边表进行遍历
- 若是有向图,以顶点为弧尾来存储边表,这样就能得到该顶点的出度。有时也为了能方便确定顶点入度,以顶点为弧头的弧,建立一个有向图的逆邻接表,及对每个顶点都建立一个链接为顶点为弧头的表。
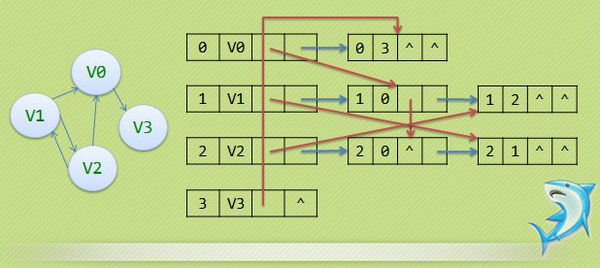
3. 十字链表
- 在有向图中,邻接表是有缺陷的,关心了出度问题,要想知道入度,就必须遍历整个图,反之逆邻接表解决了入度却不能解决出度,那能否将邻接表与逆邻接表结合起来呢,答案是肯定的,于是就有了一种新的有向图的存储方法:十字链表法。
- 红线箭头表示该图的逆邻接表的表示,蓝色箭头表示该图的邻接表。
三. 遍历算法
1. 深度优先搜索DFS(Depth First Search)
- DFS,类似于树中的前序遍历。
- 大致过程:
①从任一个顶点出发,访问它任意一个未被访问的邻接点,一直到它所有的邻接点都被访问。
②此时开始原路退回上一个顶点,检查是否有邻接点没被访问,如果有继续。
③如果没有再退回,直到退回起点为止。
- 当以邻接表做存储结构时,DFS的时间复杂度为O(n+e)。用邻接矩阵的时间复杂度为O(n^2)。
2. 广度优先搜索BFS(Breadth First Search)
- BFS,类似于树中的按层次遍历。
- 大致过程:可以借助队列
①从任一个顶点出发,把该顶点放入队列。然后出队时访问它所有邻接点,依次放入队列。
②上一次的顶点依次出队,每个结点把它所有没被访问的邻接点入队。
③重复上面的步骤,队列里出来的顶点直到没有任何邻接点为止。
- 当以邻接表做存储结构时,BFS的时间复杂度为O(n+e)。用邻接矩阵的时间复杂度为O(n^2)。
四. 最小生成树问题
- 最小生成树:在连通网的所有生成树中,所有边的代价和最小的生成树,称为最小生成树。
- 最小生成树可能不是唯一的,但最小生成树的权值之和一定是唯一的。
- 一般用的都是贪心算法,但存在的一些限制:①只能用图里面的边 ②只能正好用掉n-1条边(不多不少)③选的这条边不能让图构成回路(就不是树了)。在这种限制下,有下面两种算法 Prim 和 Kruskal 。
1. Prim算法
- 整体思路:每次迭代选择代价最小的边对应的点,加入到最小生成树中(一种贪心算法)。算法从某一个顶点s开始,逐渐长大覆盖整个连通网的所有顶点。
长大的意思:就是慢慢收顶点,每次包含都是找权最小和满足限制的(如果同时有多条满足条件的,任选一条)。
在选权值最小的边时候,记得限制:①只能用图里面的边 ②只能正好用掉n-1条边 ③选的这条边不能让图构成回路。
- 生长过程图示(红色的表示生成树):







2. Kruskal算法
- 整体思想:将森林合并为树。此算法可以称为“加边法”。一开始把每个顶点看成一颗单独的树,通过加入最小的,并且满足限制的边,把多颗树合并起来。最终形成一颗生成树。
1. 把图中的所有边按代价从小到大排序。
2. 把图中的n个顶点看成独立的n棵树组成的森林。
3. 按权值从小到大选择边,所选的边连接的两个顶点ui,vi,应属于两颗不同的树,则成为最小生成树的一条边,并将这两颗树合并作为一颗树。
4. 重复3,直到所有顶点都在一颗树内或者有n-1条边为止。
- 生成过程图示:




五. 其他问题
1.稀疏图和稠密图的存储问题
- 稠密图用:邻接矩阵存储
- 稀疏图用:邻接表存储
- 原因:
邻接表只存储非零节点,而邻接矩阵则要把所有的节点信息(非零节点与零节点)都存储下来。
稀疏图的非零节点不多,所以选用邻接表效率高,如果选用邻接矩阵则效率很低,矩阵中大多数都会是零节点!
稠密图的非零界点多,零节点少,选用邻接矩阵是最适合不过!
2. 一些计算
- 完全图:无向图中,有1/2*n(n-1)条边的图;有向图中,有n(n-1)条边的图。
3. 其他
- 最小生成树可能不是唯一的,但最小生成树的权值之和一定是唯一的。
- 连通图上各边权值均不相同,则该图的最小生成树是唯一的。
转载自blog.csdn.net/weixin_39731083/article/details/81625828