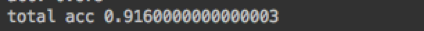今天写一个比较简单的机器学习例子
使用线性回归实现人脸识别
使用的数据集是ORL数据集
算法描述
输入:图片矩阵img,标签信息label,测试图片test
对每一个类:
第一步:从图片矩阵中读出来一类图片,划分为训练集(X)与测试集(y)
第二步:计算w
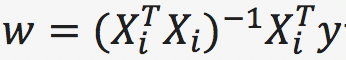
第三步:计算预测图片
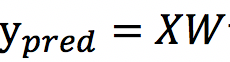
第四步:计算出dis即预测图片与真实图片之间的误差,并将误差存储起来
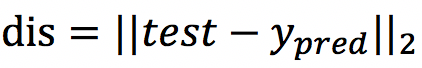
对于每一个测试图片test,找到最小dis对应的标签label,label对test的分类
使用二折交叉验证,将原油数据集划分为两部分X1,X2;第一次将X1作为训练集,X2作为测试集;第二次将X2作为训练集,X1作为测试集。
数据集
ORL人脸数据集
使用的是:ORL_32_32.mat
使用scipy直接读取,里面包含两个矩阵,第一个矩阵是人脸的数据,第二个矩阵是标签
实验环境
python 3.6
macOS 10.12
上代码
比较简单就直接放代码了
注释也比较详细
使用二折交叉验证,我直接把二折写死了,如果是n折的话,可以用循环去写。
二折的思路比较简单:第一次选取每一类前五张照片做训练集,后五张照片做测试集,第二次选取每一类前五张照片做测试集,后五张照片做训练集。
import scipy.io as sio
import random
import numpy as np
#使用scipy读取mat文件
mat=sio.loadmat('ORL_32_32.mat')
img=mat['alls']
label=mat['gnd']
count=0
acc_sum=0
#测试100次,每一次都计算一下准确率
for iter in range(1):
#对40个类中的图片 随机取样 用于测试
for i in range(40):
index = random.sample(range(0, 10), 1) #计算一组随机数
totest = img[:, i * 10 + index[0]:i * 10 + index[0] + 1] #在每个类中随机取出一张图片
tolabel = label[0][i * 10] #取出该图片对应的标签
dislist = [] #建立一个list 用于存储距离
#对每一个类都进行一次线性回归
for j in range(40):
batch_img = img[:, j * 10:j * 10 + 10] #取出一个batch,其中包含了测试集与训练集
#二折交叉验证 对训练集与测试集进行划分
# 第一次 batch中的前五个数据 作为训练集 后五个数据作为测试集合
train_img = batch_img[:, 0:5]
test_img = batch_img[:, 5:10]
#将训练集合与测试集合转换为矩阵
xMat = np.mat(train_img / 255)
yMat = np.mat(test_img / 255)
#计算w
xTx = xMat.T * xMat
w = xTx.I * xMat.T * yMat
# w = np.linalg.solve(xTx, xMat.T * yMat) #可能会出现矩阵非正定的情况,这个时候使用np.linalg.solve解决
#计算出一张预测的图片
y_pred_1 = train_img * w
# 第二次 batch中的前五个数据 作为测试集合 后五个数据作为训练集
train_img = batch_img[:, 5:10]
test_img = batch_img[:, 0:5]
# 将训练集合与测试集合转换为矩阵
xMat = np.mat(train_img / 255)
yMat = np.mat(test_img / 255)
#计算w
xTx = xMat.T * xMat
w = xTx.I * xMat.T * yMat
# w = np.linalg.solve(xTx, xMat.T * yMat) #可能会出现矩阵非正定的情况,这个时候使用np.linalg.solve解决
#计算出一张预测的图片
y_pred_2 = train_img * w
#计算预测图片与真实图片之间的误差
dis = (y_pred_1 + y_pred_2) / 2 - totest
#对误差计算二范数,得到欧式距离 将这些距离存储dislist中
dislist.append(np.linalg.norm(dis, ord=2))
#取出误差最小的预测图片 并找到他对应的标签 作为预测结果输出
label_pridect = dislist.index(min(dislist))
#count用于计算准确率
if (label_pridect + 1 == tolabel):
count = count + 1
# print(label_pridect)
print('acc:', count / 40)
acc_sum =acc_sum+count/40
count=0
print('total acc',acc_sum/100)
这里再给出使用留出法的代码
count=0
#对40个类中的图片 随机取样 用于测试
for i in range(40):
totest=img[:,i*10+7:i*10+8]
tolabel = label[0][i*10]
dislist=[]
for j in range(40):
train_img = img[:, j * 10:j * 10 + 9] #每一类图片的前9个作为训练集
test_img = img[:, j*10+9:j*10+10] #每一类图片的最后一个作为测试集
xMat = np.mat(train_img / 255)
yMat = np.mat(test_img / 255)
#计算w
xTx = xMat.T * xMat
w = xTx.I * xMat.T * yMat
y_pred = train_img * w
#计算真实值于预测值的误差
dis=y_pred - totest
dislist.append(np.linalg.norm(dis, ord=2))
#取出误差最小的预测图片 并找到他对应的标签 作为预测结果输出
label_pridect=dislist.index(min(dislist))
if(label_pridect+1==tolabel):
count=count+1
print(label_pridect)
print('acc:',count/40)训练结果
留出效果可以说是非常好了,几乎100%,二折训练集会少一些,所以效果差一点。
跑了十次二折的结果
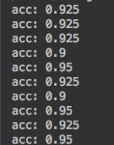
跑了100次二折求平均的结果