Table of Contents
结合上一节在获得人眼特征点后需要对睁眼闭眼状态做出判断,方法的选择需要经验结合公平的评价方法,使用大量测试集得到不同方法下的精确度并做出比较:
1、均值法
50帧睁眼数据取均值,得到不同阈值下精确度。
2、中值法
50帧睁眼数据取中值,得到不同阈值下精确度。
3、KNN
KNN是一种ML常用分类算法,通过测量不同特征值之间的距离进行分类。它的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别,其中K通常是不大于20的整数。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
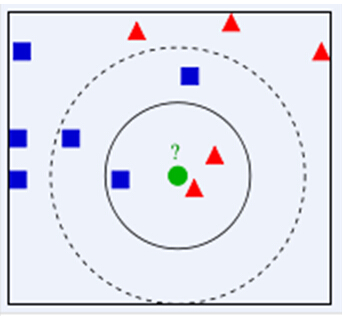
下面通过一个简单的例子说明一下:如下图,绿色圆要被决定赋予哪个类,是红色三角形还是蓝色四方形?如果K=3,由于红色三角形所占比例为2/3,绿色圆将被赋予红色三角形那个类,如果K=5,由于蓝色四方形比例为3/5,因此绿色圆被赋予蓝色四方形类。

KNN算法的思想:就是在训练集中数据和标签已知的情况下,输入测试数据,将测试数据的特征与训练集中对应的特征进行相互比较,找到训练集中与之最为相似的前K个数据,则该测试数据对应的类别就是K个数据中出现次数最多的那个分类,其算法的描述为:
1)计算测试数据与各个训练数据之间的距离;
2)按照距离的递增关系进行排序;
3)选取距离最小的K个点;
4)确定前K个点所在类别的出现频率;
5)返回前K个点中出现频率最高的类别作为测试数据的预测分类。
针对疲劳检测问题:将50帧睁眼、50闭眼数据进行训练,用1600张图像做测试,得到不同K值时的精确度。
KNN方法适用于训练集较小,因为每次predict都需要遍历训练集,当然训练集较大的话可以用KD-Tree KNN,减少搜索时间。
OpenCV提供了KNN算法接口,支持Mat数据作为训练集和测试集,要求训练集和测试集Mat形式相同,OpenCV设了很多assert,不支持直接给你抛出异常,需要训练前将特征数据标准化。不过网上只提供了标准输入参数,阅读完接口可以根据具体数据做一些转换,比如要训练的数据是一维的,把Vector直接放进Mat也可以,有了这接口可以少敲不少代码。下附KNN法主要代码:
//KNN clarify eye status
cv::Mat train_data;
cv::Mat train_labels;; //特征
int train_num = 50;
for(int i = 0; i < train_num ; i++)
{
train_data.push_back(left_eye_ratio_[i]); //序列化后放入data
train_labels.push_back(1); //对应的标注 睁眼1
}
for(int i = left_eye_ratio_.size()/2; i < (left_eye_ratio_.size()/2 + train_num); i++)
{
train_data.push_back(left_eye_ratio_[i]); //序列化后放入data
train_labels.push_back(0); //对应的标注 闭眼0
}
//使用KNN算法
//cv::Ptr<cv::ml::TrainData> tData = cv::ml::TrainData::create(train_data, cv::ml::ROW_SAMPLE, train_labels);
for(int K = 3;K <= 8;K += 1) {
float count_left_eye = 0;
float left_accuracy;
float count_right_eye = 0;
float right_accuracy;
cv::Ptr<cv::ml::KNearest> model = cv::ml::KNearest::create();
model->setDefaultK(K);
model->setIsClassifier(true);
//2nd KDTREE-KNN 训练集很大
model->setAlgorithmType(cv::ml::KNearest::BRUTE_FORCE);
model->train(train_data, cv::ml::ROW_SAMPLE, train_labels);
cout<< "K ="<< K<<" ";
for(int i = 0; i< left_eye_ratio_.size()/2; i++) {
// if(left_eye_ratio_[i] > FACTOR*eyeMouthStatus.GetLeftEyeThresh()) {
// count_left_eye++;
// }
cv::Mat test_Mat;
test_Mat.push_back(left_eye_ratio_[i]);
float cnn_num = model->predict(test_Mat);
//cout << i <<"CNN predict"<< cnn_num << " ";
if(cnn_num == 1)
{
count_left_eye++;
}
}
for(int i = left_eye_ratio_.size()/2; i< left_eye_ratio_.size(); i++) {
cv::Mat test_Mat;
test_Mat.push_back(left_eye_ratio_[i]);
float cnn_num = model->predict(test_Mat);
// if(left_eye_ratio_[i] < FACTOR*eyeMouthStatus.GetLeftEyeThresh()) {
// count_left_eye++;
// }
if(cnn_num == 0)
{
count_left_eye++;
}
}
left_accuracy = count_left_eye/left_eye_ratio_.size();
cout<<"left_accuracy"<<left_accuracy<<" ";
for(int i = 0; i< right_eye_ratio_.size()/2; i++) {
cv::Mat test_Mat;
test_Mat.push_back(right_eye_ratio_[i]);
float cnn_num = model->predict(test_Mat);
if(cnn_num == 1)
{
count_right_eye++;
}
}
for(int i = right_eye_ratio_.size()/2; i< right_eye_ratio_.size(); i++) {
cv::Mat test_Mat;
test_Mat.push_back(right_eye_ratio_[i]);
float cnn_num = model->predict(test_Mat);
if(cnn_num == 0)
{
count_right_eye++;
}
}
right_accuracy = count_right_eye/right_eye_ratio_.size();
cout<<"right_accuracy"<<right_accuracy<<endl;
}三种方法对比效果如下图:其中K取值3-8效果相同,横轴为test1、2不同阈值,纵轴为对应精确度。

4、K-means
K-means顾名思义,K表示需要聚成的K个类,means指对象均值。
K-MEANS算法是输入聚类个数k,以及包含 n个数据对象的数据库,输出满足方差最小标准k个聚类的一种算法。k-means 算法接受输入量 k ;然后将n个数据对象划分为 k个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。
基本步骤
(1) 从 n个数据对象任意选择 k 个对象作为初始聚类中心;
(2) 根据每个聚类对象的均值(中心对象),计算每个对象与这些中心对象的距离;并根据最小距离重新对相应对象进行划分;
(3) 重新计算每个(有变化)聚类的均值(中心对象);
(4) 计算标准测度函数,当满足一定条件,如函数收敛时,则算法终止;如果条件不满足则回到步骤(2)。