目录
链接:
http://speech.ee.ntu.edu.tw/~tlkagk/courses/MLDS_2015_2/Lecture/Structured%20SVM%20(v7).pdf
这次对SSVM不是很理解,只能做一个大概的笔记整理,如有错误还请指正。
Structured Learning
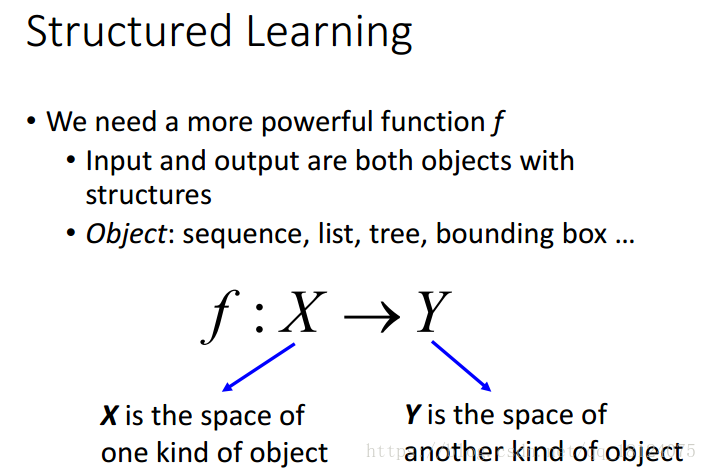
所谓的Structured Learning,就是寻找一个function,输入和输出可能是sequence, list, tree, bounding box等。为了解决这种问题,我们提出两步走战略,这种战略相当于解决这类问题的通解。刚开始,我也不是很习惯,但是这种思想却很重要。

Step1:把x和y当做输入,找到一个函数F,满足F(x,y)的值为一个实数。
Step2:在找到F(x,y)的情况下,穷举所有可能出现的y,找到F(x,y)的值最大的那个y值。
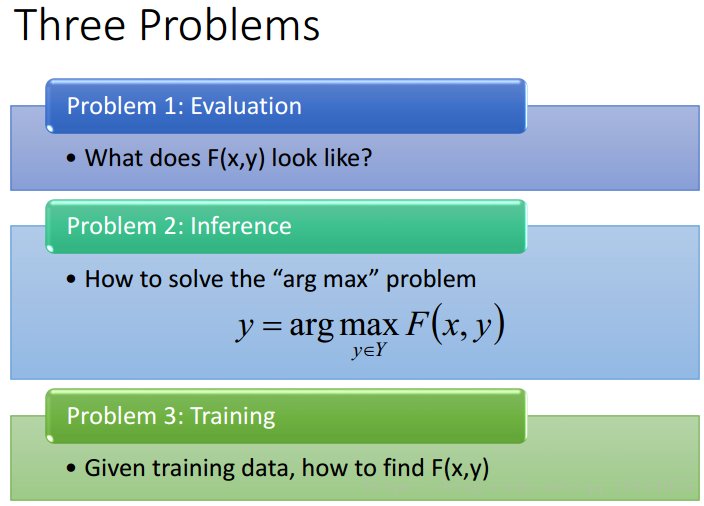
完成这两步,我们需要解决以下三个问题,这和HMM特别相似。
Separable case
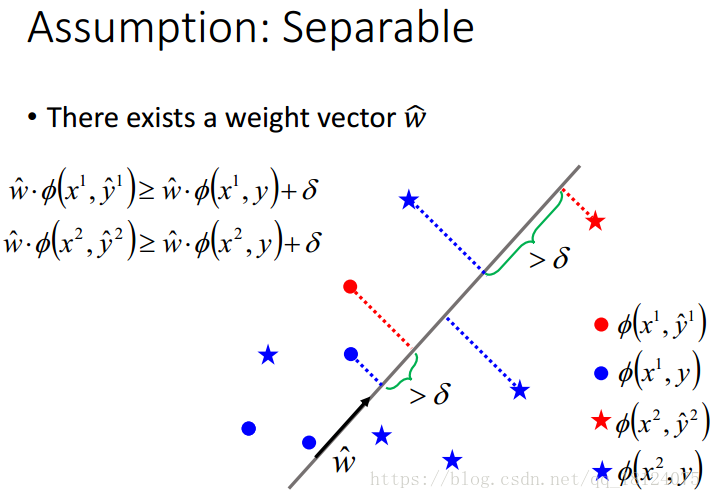
有separable的定义可以知道,在所有的各自训练样例中,存在一个样例,使得该类别的其他样例与w_hat的内积,再加上margin都是大于等于的。这里,有两种类别,所以有两个式子。

这里,我们用计算weight的structured perceptron演算法。y_hat表示正确分类的结果,反之为错误分类的结果。+表示让w跟正确的y_hat更靠近一些;-表示李错的更远离一点。
但是有一个问题,这种演算法什么时候会使得所有的输出y才能和正确的全部相等呢?要多久才收敛?结论如下:
具体数学公式推导省略,感兴趣的可以看ppt链接,这里我只想说用这种方法迭代,最后肯定会收敛的。

Non-separable case
对于Non-separable case的数据,可能某些w比之前的separable case的w更好,那么我们怎么去评判一个w的好坏呢?


这里,我们使用随机梯度下降法来作为演算法。
Considering Errors
对于误差这个东西,不是每次被错误分类的情况都能被一视同仁的。这里利用正确和错误面积的交并部分比,再加入到之前的损失函数之中,我们可以得到新的一个cost function。

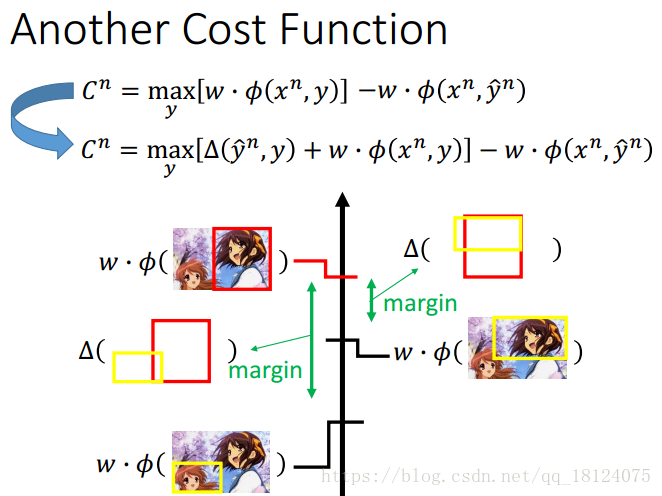
Regularization


加入惩罚项,这样可以使得误差函数更加的适合训练和测试数据分布不一样的情况,从而增加模型的泛化能力。随着损失函数的更加复杂化,其偏导、权值更新公式都会发生一些变化。其中,权值的变化和之前DNN的weight decay还挺像的。
Structured SVM

这种结果和普通的SVM挺像的,所以我们也可以套用svm去解,Cutting Plane Algorithm。这方法我也是第一次看见,一般都是对目标函数与约束条件的对偶求拉格朗日乘子,然后对其各项参数求偏导,代入拉格朗日方程中,只剩下关于a的一个方程,利用KKT条件构造约束条件,再求其对偶形式,从而求解。



Multi-class and binary SVM

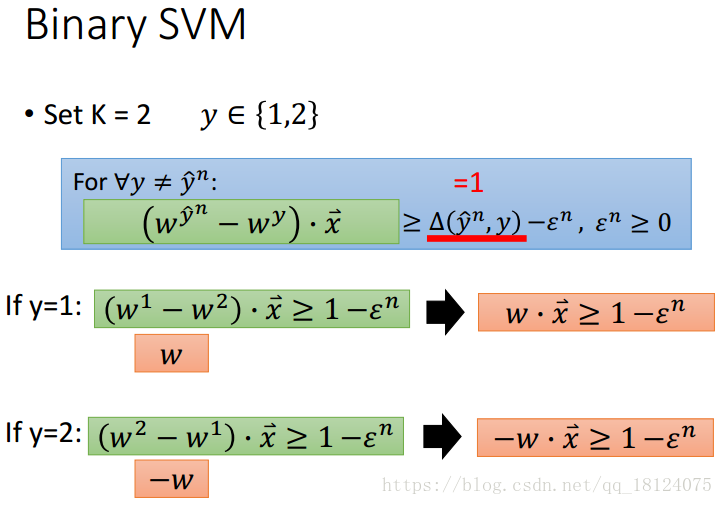
小结
学习了这节课structured svm,让我对svm有了新的认识,感觉以前学的都是啃公式。这种讲解方法确实是对知识的活学活用,但是理解起来还是需要一定的基础,毕竟是有一定的难度的。