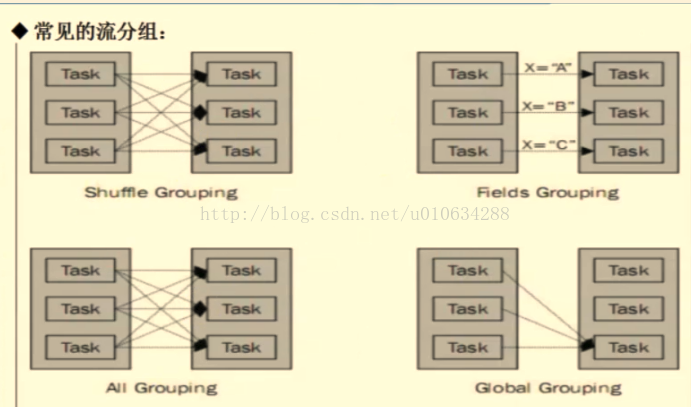
1、定义:Stream Grouping:为每一个bolt指定应该接收哪个流作为输入,流分组定义了如何在bolt的任务直接进行分发。
1.1 Shuffle Grouping随机分组:保证每个bolt接受到的tuple数目相同
1.2 Fields Grouping按字段分组,比如按照userid来分组,具有同样的userid的tuple会被分到同样的Bolts,而不同的userid则会被分配到不同的Bolts。
1.3 All Grouping广播发送,对于每一个tuple,所有的Bolts都会收到。
1.4 Global Grouping 全局分组,这个tuple会被分配到storm中的一个bolt的其中一个task,再具体一点就是分配到给id值最低的那个task.。这种分组方式并不常用。
1.5 本地分组,如果目标bolts是在同一个工作进程存在一个或者多个任务,tuple会被随机分配给执行任务,否则该分组方式和随机分组方式一样。
例子:首先我新增Spout、bolts和Topology类
Spout类:
package hellow.spout;
import java.util.HashMap;
import java.util.Map;
import java.util.Random;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
public class PWSpout extends BaseRichSpout {
private static final long serialVersionUID = 1L;
private SpoutOutputCollector collector;
private static final Map<Integer, String> map = new HashMap<Integer, String>();
static {
map.put(0, "java");
map.put(1, "php");
map.put(2, "groovy");
map.put(3, "python");
map.put(4, "ruby");
map.put(5, "c++");
map.put(6, ".net");
}
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
//对spout进行初始化
this.collector = collector;
//System.out.println(this.collector);
}
/**
* <B>方法名称:</B>轮询tuple<BR>
* <B>概要说明:</B><BR>
* @see backtype.storm.spout.ISpout#nextTuple()
*/
@Override
public void nextTuple() {
//随机发送一个单词
final Random r = new Random();
int num = r.nextInt(7);
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
this.collector.emit(new Values(map.get(num)));
}
/**
* <B>方法名称:</B>declarer声明发送数据的field<BR>
* <B>概要说明:</B><BR>
* @see backtype.storm.topology.IComponent#declareOutputFields(backtype.storm.topology.OutputFieldsDeclarer)
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
//进行声明
declarer.declare(new Fields("print"));
}
}
第一个bolt类,用于在控制台打印数据
package hellow.bolt;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
public class PrintBolt extends BaseBasicBolt {
private static final Log log = LogFactory.getLog(PrintBolt.class);
private static final long serialVersionUID = 1L;
@Override
public void execute(Tuple input, BasicOutputCollector collector) {
//获取上一个组件所声明的Field
String print = input.getStringByField("print");
log.info("【print】: " + print);
//System.out.println("Name of input word is : " + word);
//进行传递给下一个bolt
collector.emit(new Values(print));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("write"));
}
}
第二个bolt类用于将数据写入到文件中
package hellow.bolt;
import java.io.FileWriter;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import clojure.main;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Tuple;
public class WriteBolt extends BaseBasicBolt {
private static final long serialVersionUID = 1L;
private static final Log log = LogFactory.getLog(WriteBolt.class);
private FileWriter writer ;
@Override
public void execute(Tuple input, BasicOutputCollector collector) {
//获取上一个组件所声明的Field
String text = input.getStringByField("write");
try {
if(writer == null){
if(System.getProperty("os.name").equals("Windows 10")){
writer = new FileWriter("D:\\099_test\\" + this);
} else if(System.getProperty("os.name").equals("Windows 8.1")){
writer = new FileWriter("D:\\099_test\\" + this);
} else if(System.getProperty("os.name").equals("Windows 7")){
writer = new FileWriter("D:\\099_test\\" + this);
} else if(System.getProperty("os.name").equals("Linux")){
System.out.println("----:" + System.getProperty("os.name"));
writer = new FileWriter("/usr/local/temp/" + this);
}
}
log.info("【write】: 写入文件");
writer.write(text);
writer.write("\n");
writer.flush();
} catch (Exception e) {
e.printStackTrace();
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
最后新增拓扑类
package hellow.topology;
import hellow.bolt.PrintBolt;
import hellow.bolt.WriteBolt;
import hellow.spout.PWSpout;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.StormSubmitter;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.tuple.Fields;
public class PWTopology3 {
public static void main(String[] args) throws Exception {
//
Config cfg = new Config();
cfg.setNumWorkers(2);
cfg.setDebug(true);
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout", new PWSpout(), 4);
builder.setBolt("print-bolt", new PrintBolt(), 4).shuffleGrouping("spout");
//设置字段分组
builder.setBolt("write-bolt", new WriteBolt(), 8).fieldsGrouping("print-bolt", new Fields("write"));
//设置广播分组
//builder.setBolt("write-bolt", new WriteBolt(), 4).allGrouping("print-bolt");
//设置全局分组
//builder.setBolt("write-bolt", new WriteBolt(), 4).globalGrouping("print-bolt");
//2 集群模式
StormSubmitter.submitTopology("top3", cfg, builder.createTopology());
}
}
在集群环境中,我们进入zk目录和storm目录,启动相关服务
zk服务启动
zkServer.sh startstorm nimbus & storm supervisor &nimbus运行PWTopology3
storm jar storm01.jar hellow.topology.PWTopology3
print-bolt使用随机分组,bolt接受到的tuple数目相同,也就是print-bolt接受到的单词数量是相同的
write-bolt使用字段分组,具有同样的userid的tuple会被分到同样的Bolts
因此在集群环境中,write-bolt设置了8个task,由于我们这里只有7个单词,所以最多会产生
7个文件,并且相同的单词会被分到相同的文件中。
因此我们看到了如下图所示的结果,2台服务器分别出现了2个和4个文件。并且相同的词会被分配到同一个文件里面